 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Biases and Preserving Privacy on Balanced Faces in the Wild
Paper and Code
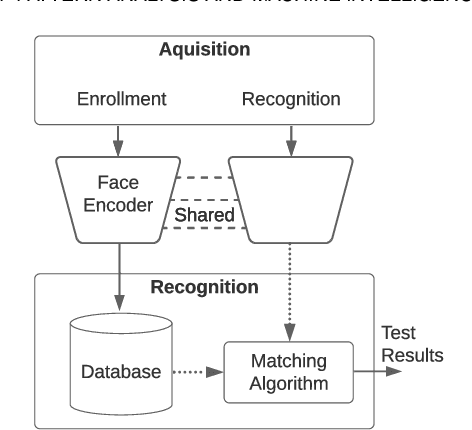
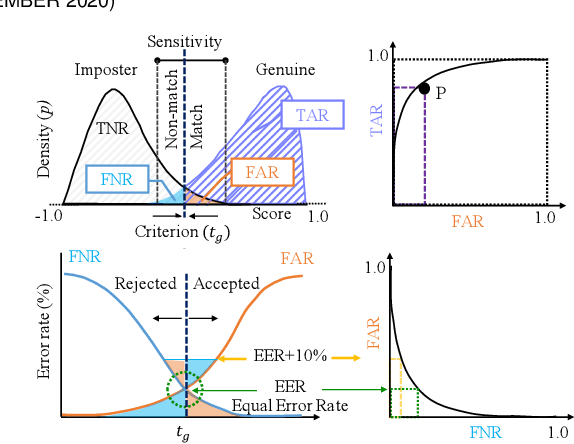
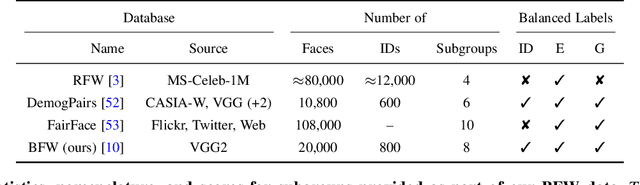
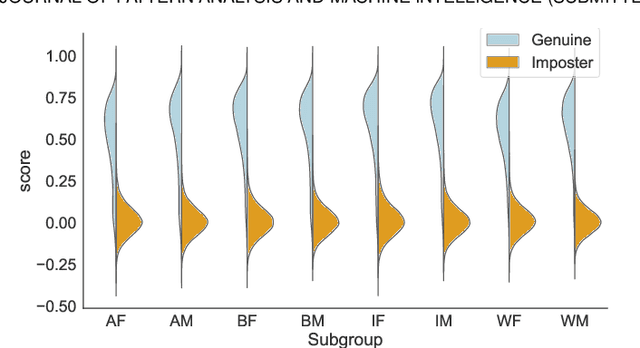
There are demographic biases in the SOTA CNN used for FR. Our BFW dataset serves as a proxy to measure bias across ethnicity and gender subgroups, allowing us to characterize FR performances per subgroup. We show performances are non-optimal when a single score threshold is used to determine whether sample pairs are genuine or imposter. Furthermore, actual performance ratings vary greatly from the reported across subgroups. Thus, claims of specific error rates only hold true for populations matching that of the validation data. We mitigate the imbalanced performances using a novel domain adaptation learning scheme on the facial encodings extracted using SOTA deep nets. Not only does this technique balance performance, but it also boosts the overall performance. A benefit of the proposed is to preserve identity information in facial features while removing demographic knowledge in the lower dimensional features. The removal of demographic knowledge prevents future potential biases from being injected into decision-making. Additionally, privacy concerns are satisfied by this removal. We explore why this works qualitatively with hard samples. We also show quantitatively that subgroup classifiers can no longer learn from the encodings mapped by the proposed.