 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition with Spatio-Temporal Visual Attention on Skeleton Image Sequences
Paper and Code
Apr 11, 2018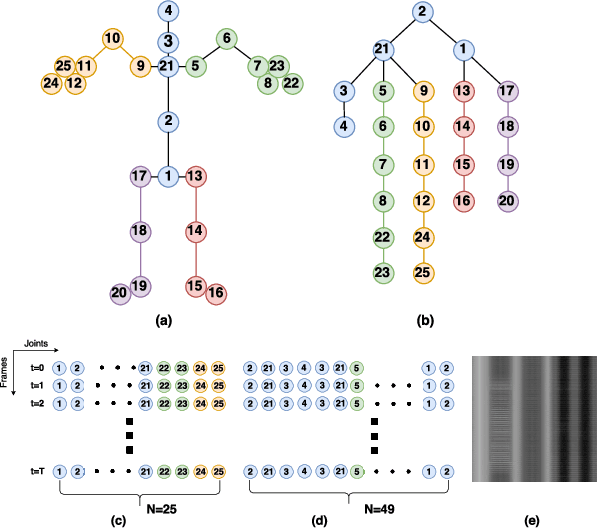

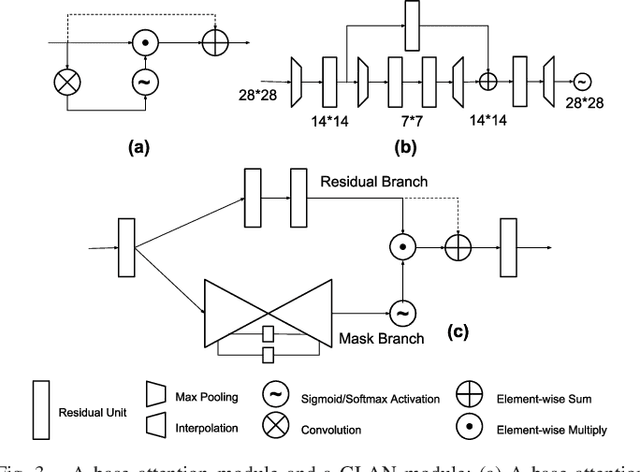
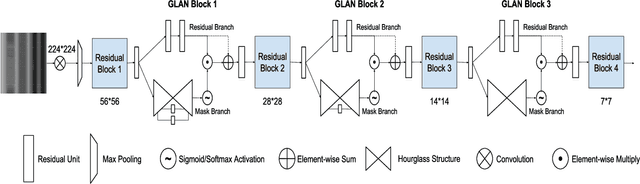
Action recognition with 3D skeleton sequences is becoming popular due to its speed and robustness. The recently proposed Convolutional Neural Networks (CNN) based methods have shown good performance in learning spatio-temporal representations for skeleton sequences. Despite the good recognition accuracy achieved by previous CNN based methods, there exist two problems that potentially limit the performance. First, previous skeleton representations are generated by chaining joints with a fixed order. The corresponding semantic meaning is unclear and the structural information among the joints is lost. Second, previous models do not have an ability to focus on informative joints. The attention mechanism is important for skeleton based action recognition because there exist spatio-temporal key stages while the joint predictions can be inaccurate. To solve these two problems, we propose a novel CNN based method for skeleton based action recognition. We first redesign the skeleton representations with a depth-first tree traversal order, which enhances the semantic meaning of skeleton images and better preserves the associated structural information. We then propose the idea of a two-branch attention architecture that focuses on spatio-temporal key stages and filters out unreliable joint predictions. A base attention model with the simplest structure is first introduced. By improving the structures in both branches, we further propose a Global Long-sequence Attention Network (GLAN). Furthermore, in order to adjust the kernel's spatio-temporal aspect ratios and better capture long term dependencies, we propose a Sub-Sequence Attention Network (SSAN) that takes sub-image sequences as inputs. Our experiment results on NTU RGB+D and SBU Kinetic Interaction outperforms the state-of-the-art. The model is further validated on noisy estimated poses from UCF101 and Kinetics.