 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization, Mayhems and Limits in Recurrent Proximal Policy Optimization
Paper and Code
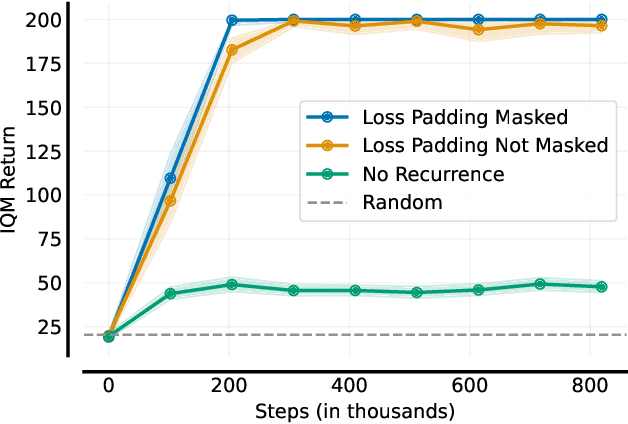
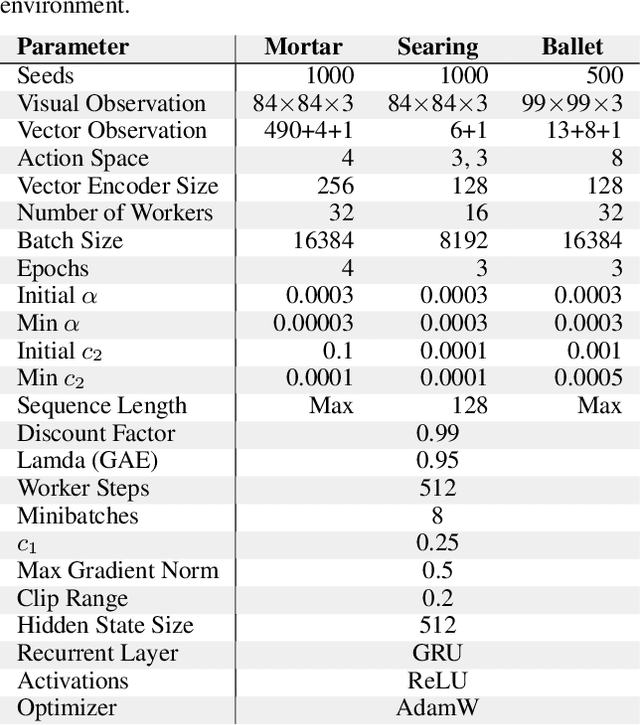
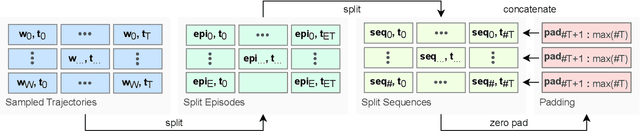
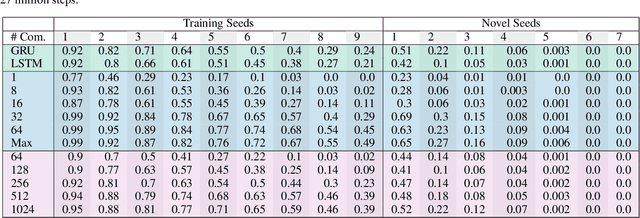
At first sight it may seem straightforward to use recurrent layers in Deep Reinforcement Learning algorithms to enable agents to make use of memory in the setting of partially observable environments. Starting from widely used Proximal Policy Optimization (PPO), we highlight vital details that one must get right when adding recurrence to achieve a correct and efficient implementation, namely: properly shaping the neural net's forward pass, arranging the training data, correspondingly selecting hidden states for sequence beginnings and masking paddings for loss computation. We further explore the limitations of recurrent PPO by benchmarking the contributed novel environments Mortar Mayhem and Searing Spotlights that challenge the agent's memory beyond solely capacity and distraction tasks. Remarkably, we can demonstrate a transition to strong generalization in Mortar Mayhem when scaling the number of training seeds, while the agent does not succeed on Searing Spotlights, which seems to be a tough challenge for memory-based agents.