 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Bidding and Playing Strategies in the Trick-Taking game Wizard using Deep Q-Networks
Paper and Code

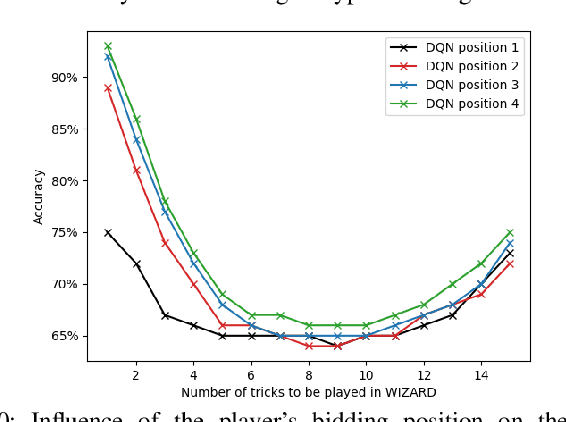
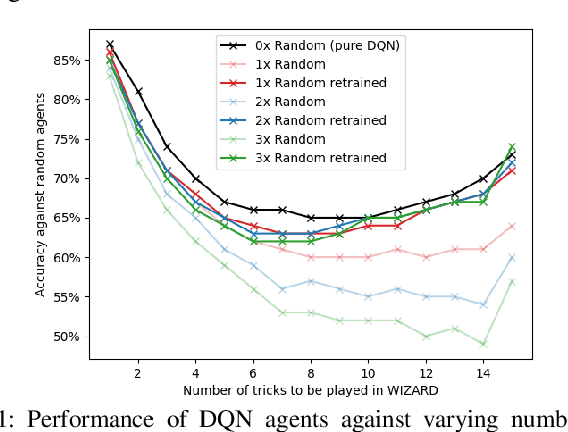
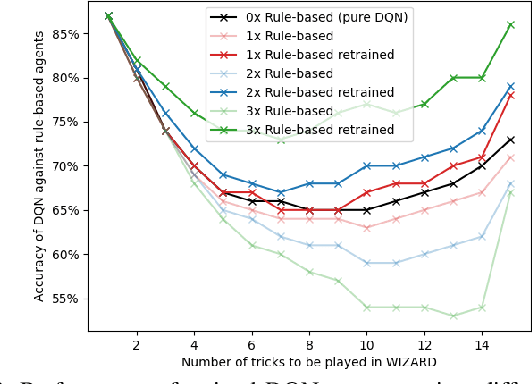
In this work, the trick-taking game Wizard with a separate bidding and playing phase is modeled by two interleaved partially observable Markov decision processes (POMDP). Deep Q-Networks (DQN) are used to empower self-improving agents, which are capable of tackling the challenges of a highly non-stationary environment. To compare algorithms between each other, the accuracy between bid and trick count is monitored, which strongly correlates with the actual rewards and provides a well-defined upper and lower performance bound. The trained DQN agents achieve accuracies between 66% and 87% in self-play, leaving behind both a random baseline and a rule-based heuristic. The conducted analysis also reveals a strong information asymmetry concerning player positions during bidding. To overcome the missing Markov property of imperfect-information games, a long short-term memory (LSTM) network is implemented to integrate historic information into the decision-making process. Additionally, a forward-directed tree search is conducted by sampling a state of the environment and thereby turning the game into a perfect information setting. To our surprise, both approaches do not surpass the performance of the basic DQN agent.