 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiSChuBERT: Effective Multimodal Fusion for Scholarly Document Quality Prediction
Aug 15, 2023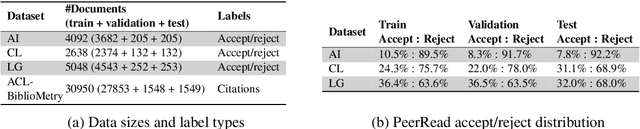


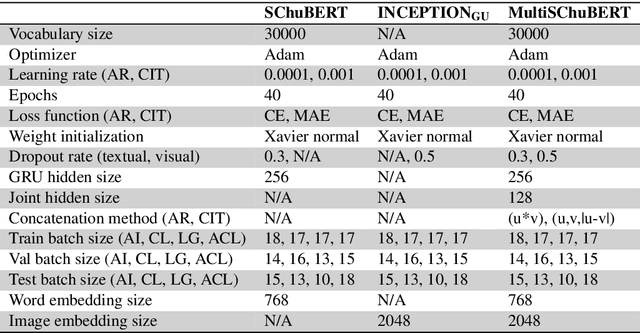
Automatic assessment of the quality of scholarly documents is a difficult task with high potential impact. Multimodality, in particular the addition of visual information next to text, has been shown to improve the performance on scholarly document quality prediction (SDQP) tasks. We propose the multimodal predictive model MultiSChuBERT. It combines a textual model based on chunking full paper text and aggregating computed BERT chunk-encodings (SChuBERT), with a visual model based on Inception V3.Our work contributes to the current state-of-the-art in SDQP in three ways. First, we show that the method of combining visual and textual embeddings can substantially influence the results. Second, we demonstrate that gradual-unfreezing of the weights of the visual sub-model, reduces its tendency to ovefit the data, improving results. Third, we show the retained benefit of multimodality when replacing standard BERT$_{\textrm{BASE}}$ embeddings with more recent state-of-the-art text embedding models. Using BERT$_{\textrm{BASE}}$ embeddings, on the (log) number of citations prediction task with the ACL-BiblioMetry dataset, our MultiSChuBERT (text+visual) model obtains an $R^{2}$ score of 0.454 compared to 0.432 for the SChuBERT (text only) model. Similar improvements are obtained on the PeerRead accept/reject prediction task. In our experiments using SciBERT, scincl, SPECTER and SPECTER2.0 embeddings, we show that each of these tailored embeddings adds further improvements over the standard BERT$_{\textrm{BASE}}$ embeddings, with the SPECTER2.0 embeddings performing best.
SChuBERT: Scholarly Document Chunks with BERT-encoding boost Citation Count Prediction
Dec 21, 2020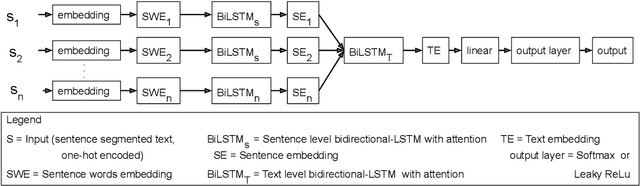
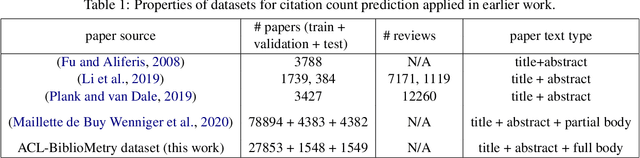
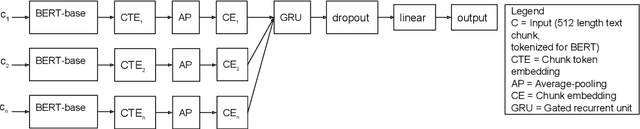
Predicting the number of citations of scholarly documents is an upcoming task in scholarly document processing. Besides the intrinsic merit of this information, it also has a wider use as an imperfect proxy for quality which has the advantage of being cheaply available for large volumes of scholarly documents. Previous work has dealt with number of citations prediction with relatively small training data sets, or larger datasets but with short, incomplete input text. In this work we leverage the open access ACL Anthology collection in combination with the Semantic Scholar bibliometric database to create a large corpus of scholarly documents with associated citation information and we propose a new citation prediction model called SChuBERT. In our experiments we compare SChuBERT with several state-of-the-art citation prediction models and show that it outperforms previous methods by a large margin. We also show the merit of using more training data and longer input for number of citations prediction.
* Published at the First Workshop on Scholarly Document Processing, at EMNLP 2020. Minor corrections were made to the workshop version, including addition of color to Figures 1,2
Structure-Tags Improve Text Classification for Scholarly Document Quality Prediction
Apr 30, 2020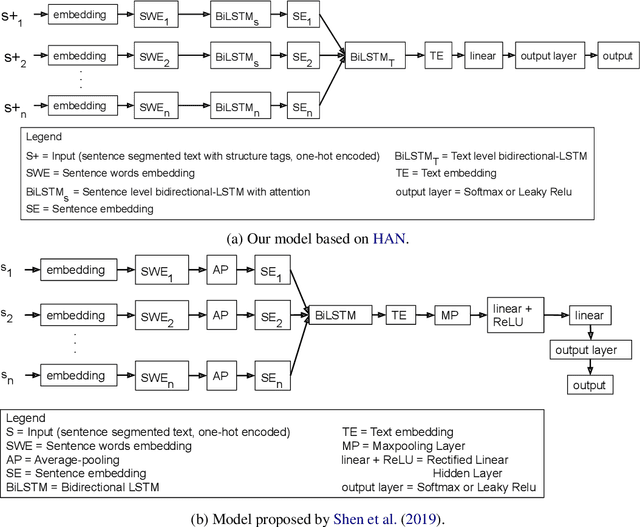



Training recurrent neural networks on long texts, in particular scholarly documents, causes problems for learning. While hierarchical attention networks (HANs) are effective in solving these problems, they still lose important information about the structure of the text. To tackle these problems, we propose the use of HANs combined with structure-tags which mark the role of sentences in the document. Adding tags to sentences, marking them as corresponding to title, abstract or main body text, yields improvements over the state-of-the-art for scholarly document quality prediction: substantial gains on average against other models and consistent improvements over HANs without structure-tags. The proposed system is applied to the task of accept/reject prediction on the PeerRead dataset and compared against a recent BiLSTM-based model and joint textual+visual model. It gains 4.7% accuracy over the best of both models on the computation and language domain and loses 2.4% against the best of both on the machine learning domain. Compared to plain HANs, accuracy increases on both domains, with 1.5% and 2% respectively. We also obtain improvements when introducing the tags for prediction of the number of citations for 88k scientific publications that we compiled from the Allen AI S2ORC dataset. For our HAN-system with structure-tags we reach 28.5% explained variance, an improvement of 1.0% over HANs without structure-tags.