 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWriter adaptation for offline text recognition: An exploration of neural network-based methods
Jul 11, 2023



Handwriting recognition has seen significant success with the use of deep learning. However, a persistent shortcoming of neural networks is that they are not well-equipped to deal with shifting data distributions. In the field of handwritten text recognition (HTR), this shows itself in poor recognition accuracy for writers that are not similar to those seen during training. An ideal HTR model should be adaptive to new writing styles in order to handle the vast amount of possible writing styles. In this paper, we explore how HTR models can be made writer adaptive by using only a handful of examples from a new writer (e.g., 16 examples) for adaptation. Two HTR architectures are used as base models, using a ResNet backbone along with either an LSTM or Transformer sequence decoder. Using these base models, two methods are considered to make them writer adaptive: 1) model-agnostic meta-learning (MAML), an algorithm commonly used for tasks such as few-shot classification, and 2) writer codes, an idea originating from automatic speech recognition. Results show that an HTR-specific version of MAML known as MetaHTR improves performance compared to the baseline with a 1.4 to 2.0 improvement in word error rate (WER). The improvement due to writer adaptation is between 0.2 and 0.7 WER, where a deeper model seems to lend itself better to adaptation using MetaHTR than a shallower model. However, applying MetaHTR to larger HTR models or sentence-level HTR may become prohibitive due to its high computational and memory requirements. Lastly, writer codes based on learned features or Hinge statistical features did not lead to improved recognition performance.
Oil Spill Segmentation using Deep Encoder-Decoder models
May 02, 2023Crude oil is an integral component of the modern world economy. With the growing demand for crude oil due to its widespread applications, accidental oil spills are unavoidable. Even though oil spills are in and themselves difficult to clean up, the first and foremost challenge is to detect spills. In this research, the authors test the feasibility of deep encoder-decoder models that can be trained effectively to detect oil spills. The work compares the results from several segmentation models on high dimensional satellite Synthetic Aperture Radar (SAR) image data. Multiple combinations of models are used in running the experiments. The best-performing model is the one with the ResNet-50 encoder and DeepLabV3+ decoder. It achieves a mean Intersection over Union (IoU) of 64.868% and a class IoU of 61.549% for the "oil spill" class when compared with the current benchmark model, which achieved a mean IoU of 65.05% and a class IoU of 53.38% for the "oil spill" class.
LostPaw: Finding Lost Pets using a Contrastive Learning-based Transformer with Visual Input
Apr 28, 2023Losing pets can be highly distressing for pet owners, and finding a lost pet is often challenging and time-consuming. An artificial intelligence-based application can significantly improve the speed and accuracy of finding lost pets. In order to facilitate such an application, this study introduces a contrastive neural network model capable of accurately distinguishing between images of pets. The model was trained on a large dataset of dog images and evaluated through 3-fold cross-validation. Following 350 epochs of training, the model achieved a test accuracy of 90%. Furthermore, overfitting was avoided, as the test accuracy closely matched the training accuracy. Our findings suggest that contrastive neural network models hold promise as a tool for locating lost pets. This paper provides the foundation for a potential web application that allows users to upload images of their missing pets, receiving notifications when matching images are found in the application's image database. This would enable pet owners to quickly and accurately locate lost pets and reunite them with their families.
The Effects of Character-Level Data Augmentation on Style-Based Dating of Historical Manuscripts
Dec 15, 2022Identifying the production dates of historical manuscripts is one of the main goals for paleographers when studying ancient documents. Automatized methods can provide paleographers with objective tools to estimate dates more accurately. Previously, statistical features have been used to date digitized historical manuscripts based on the hypothesis that handwriting styles change over periods. However, the sparse availability of such documents poses a challenge in obtaining robust systems. Hence, the research of this article explores the influence of data augmentation on the dating of historical manuscripts. Linear Support Vector Machines were trained with k-fold cross-validation on textural and grapheme-based features extracted from historical manuscripts of different collections, including the Medieval Paleographical Scale, early Aramaic manuscripts, and the Dead Sea Scrolls. Results show that training models with augmented data improve the performance of historical manuscripts dating by 1% - 3% in cumulative scores. Additionally, this indicates further enhancement possibilities by considering models specific to the features and the documents' scripts.
Image-based material analysis of ancient historical documents
Mar 02, 2022



Researchers continually perform corroborative tests to classify ancient historical documents based on the physical materials of their writing surfaces. However, these tests, often performed on-site, requires actual access to the manuscript objects. The procedures involve a considerable amount of time and cost, and can damage the manuscripts. Developing a technique to classify such documents using only digital images can be very useful and efficient. In order to tackle this problem, this study uses images of a famous historical collection, the Dead Sea Scrolls, to propose a novel method to classify the materials of the manuscripts. The proposed classifier uses the two-dimensional Fourier Transform to identify patterns within the manuscript surfaces. Combining a binary classification system employing the transform with a majority voting process is shown to be effective for this classification task. This pilot study shows a successful classification percentage of up to 97% for a confined amount of manuscripts produced from either parchment or papyrus material. Feature vectors based on Fourier-space grid representation outperformed a concentric Fourier-space format.
Artificial intelligence based writer identification generates new evidence for the unknown scribes of the Dead Sea Scrolls exemplified by the Great Isaiah Scroll (1QIsaa)
Oct 27, 2020
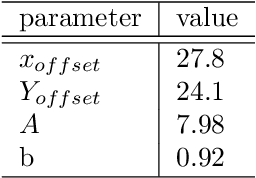

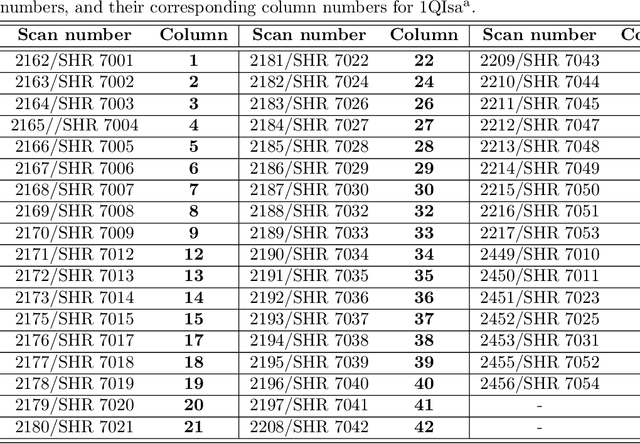
The Dead Sea Scrolls are tangible evidence of the Bible's ancient scribal culture. Palaeography - the study of ancient handwriting - can provide access to this scribal culture. However, one of the problems of traditional palaeography is to determine writer identity when the writing style is near uniform. This is exemplified by the Great Isaiah Scroll (1QIsaa). To this end, we used pattern recognition and artificial intelligence techniques to innovate the palaeography of the scrolls regarding writer identification and to pioneer the microlevel of individual scribes to open access to the Bible's ancient scribal culture. Although many scholars believe that 1QIsaa was written by one scribe, we report new evidence for a breaking point in the series of columns in this scroll. Without prior assumption of writer identity, based on point clouds of the reduced-dimensionality feature-space, we found that columns from the first and second halves of the manuscript ended up in two distinct zones of such scatter plots, notably for a range of digital palaeography tools, each addressing very different featural aspects of the script samples. In a secondary, independent, analysis, now assuming writer difference and using yet another independent feature method and several different types of statistical testing, a switching point was found in the column series. A clear phase transition is apparent around column 27. Given the statistically significant differences between the two halves, a tertiary, post-hoc analysis was performed. Demonstrating that two main scribes were responsible for the Great Isaiah Scroll, this study sheds new light on the Bible's ancient scribal culture by providing new, tangible evidence that ancient biblical texts were not copied by a single scribe only but that multiple scribes could closely collaborate on one particular manuscript.
BiNet: Degraded-Manuscript Binarization in Diverse Document Textures and Layouts using Deep Encoder-Decoder Networks
Nov 13, 2019


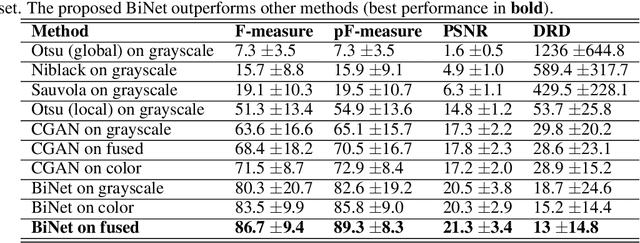
Handwritten document-image binarization is a semantic segmentation process to differentiate ink pixels from background pixels. It is one of the essential steps towards character recognition, writer identification, and script-style evolution analysis. The binarization task itself is challenging due to the vast diversity of writing styles, inks, and paper materials. It is even more difficult for historical manuscripts due to the aging and degradation of the documents over time. One of such manuscripts is the Dead Sea Scrolls (DSS) image collection, which poses extreme challenges for the existing binarization techniques. This article proposes a new binarization technique for the DSS images using the deep encoder-decoder networks. Although the artificial neural network proposed here is primarily designed to binarize the DSS images, it can be trained on different manuscript collections as well. Additionally, the use of transfer learning makes the network already utilizable for a wide range of handwritten documents, making it a unique multi-purpose tool for binarization. Qualitative results and several quantitative comparisons using both historical manuscripts and datasets from handwritten document image binarization competition (H-DIBCO and DIBCO) exhibit the robustness and the effectiveness of the system. The best performing network architecture proposed here is a variant of the U-Net encoder-decoders.