 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPF+: Boosting adaptive-potential function reinforcement learning methods with a W-shaped network for high-dimensional games
Paper and Code

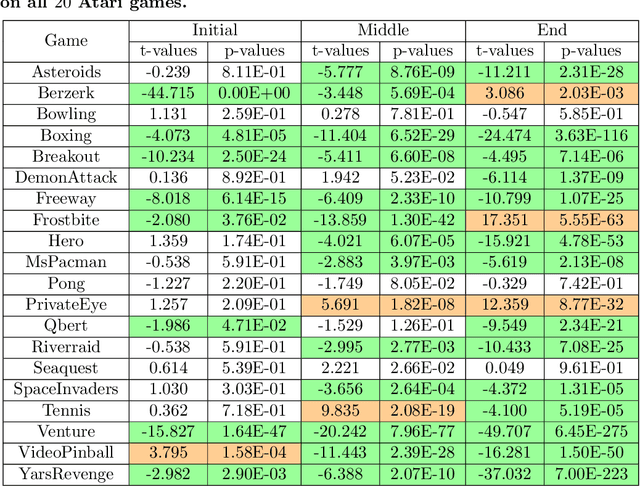
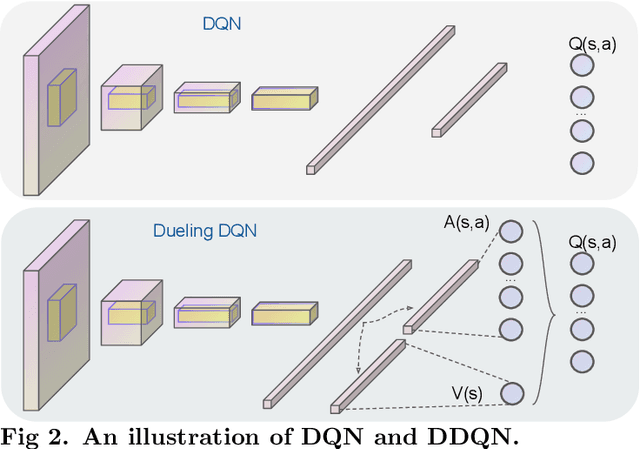
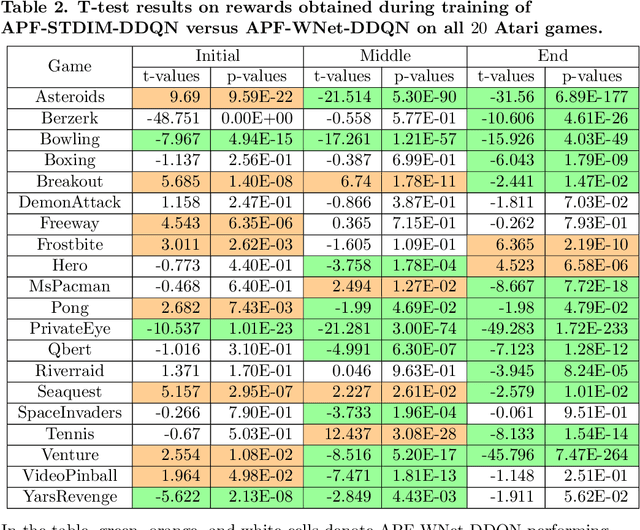
Studies in reward shaping for reinforcement learning (RL) have flourished in recent years due to its ability to speed up training. Our previous work proposed an adaptive potential function (APF) and showed that APF can accelerate the Q-learning with a Multi-layer Perceptron algorithm in the low-dimensional domain. This paper proposes to extend APF with an encoder (APF+) for RL state representation, allowing applying APF to the pixel-based Atari games using a state-encoding method that projects high-dimensional game's pixel frames to low-dimensional embeddings. We approach by designing the state-representation encoder as a W-shaped network (W-Net), by using which we are able to encode both the background as well as the moving entities in the game frames. Specifically, the embeddings derived from the pre-trained W-Net consist of two latent vectors: One represents the input state, and the other represents the deviation of the input state's representation from itself. We then incorporate W-Net into APF to train a downstream Dueling Deep Q-Network (DDQN), obtain the APF-WNet-DDQN, and demonstrate its effectiveness in Atari game-playing tasks. To evaluate the APF+W-Net module in such high-dimensional tasks, we compare with two types of baseline methods: (i) the basic DDQN; and (ii) two encoder-replaced APF-DDQN methods where we replace W-Net by (a) an unsupervised state representation method called Spatiotemporal Deep Infomax (ST-DIM) and (b) a ground truth state representation provided by the Atari Annotated RAM Interface (ARI). The experiment results show that out of 20 Atari games, APF-WNet-DDQN outperforms DDQN (14/20 games) and APF-STDIM-DDQN (13/20 games) significantly. In comparison against the APF-ARI-DDQN which employs embeddings directly of the detailed game-internal state information, the APF-WNet-DDQN achieves a comparable performance.