 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning in Robotic Motion Planning by Combined Experience-based Planning and Self-Imitation Learning
Paper and Code
Jun 11, 2023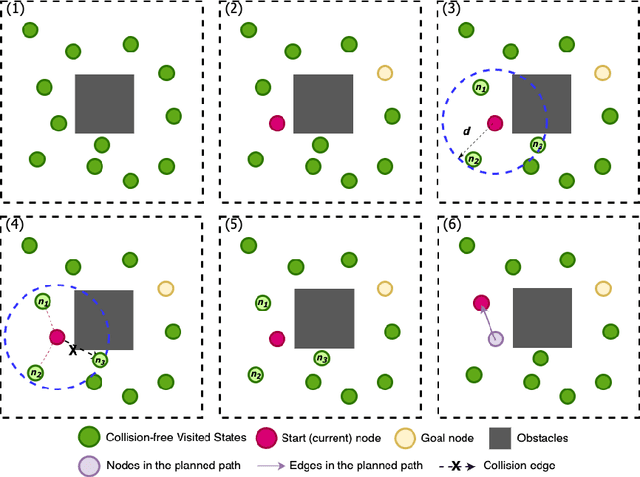

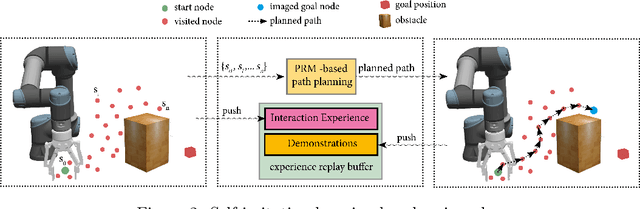

High-quality and representative data is essential for both Imitation Learning (IL)- and Reinforcement Learning (RL)-based motion planning tasks. For real robots, it is challenging to collect enough qualified data either as demonstrations for IL or experiences for RL due to safety considerations in environments with obstacles. We target this challenge by proposing the self-imitation learning by planning plus (SILP+) algorithm, which efficiently embeds experience-based planning into the learning architecture to mitigate the data-collection problem. The planner generates demonstrations based on successfully visited states from the current RL policy, and the policy improves by learning from these demonstrations. In this way, we relieve the demand for human expert operators to collect demonstrations required by IL and improve the RL performance as well. Various experimental results show that SILP+ achieves better training efficiency higher and more stable success rate in complex motion planning tasks compared to several other methods. Extensive tests on physical robots illustrate the effectiveness of SILP+ in a physical setting.