 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Properties of Feature Attribution for Supervised Contrastive Learning
Apr 24, 2026Most Neural Networks (NNs) for classification are trained using Cross-Entropy as a loss function. This approach requires the model to have an explicit classification layer. However, there exist alternative approaches, such as Contrastive Learning (CL). Instead of explicitly operating a classification, CL has the NN produce an embedding space where projections of similar data are pulled together, while projections of dissimilar data are pushed apart. In the case of Supervised CL (SCL), labels are adopted as similarity criteria, thus creating an embedding space where the projected data points are well-clustered. SCL provides crucial advantages over CE with regard to adversarial robustness and out-of-distribution detection, thus making it a more natural choice in safety-critical scenarios. In the present paper, we empirically show that NNs for image classification trained with SCL present higher-quality feature attribution explanations than CL with regard to faithfulness, complexity, and continuity. These results reinforce previous findings about CL-based approaches when targeting more trustworthy and transparent NNs and can guide practitioners in the selection of training objectives targeting not only accuracy, but also transparency of the models.
No Single Metric Tells the Whole Story: A Multi-Dimensional Evaluation Framework for Uncertainty Attributions
Mar 25, 2026Research on explainable AI (XAI) has frequently focused on explaining model predictions. More recently, methods have been proposed to explain prediction uncertainty by attributing it to input features (uncertainty attributions). However, the evaluation of these methods remains inconsistent as studies rely on heterogeneous proxy tasks and metrics, hindering comparability. We address this by aligning uncertainty attributions with the well-established Co-12 framework for XAI evaluation. We propose concrete implementations for the correctness, consistency, continuity, and compactness properties. Additionally, we introduce conveyance, a property tailored to uncertainty attributions that evaluates whether controlled increases in epistemic uncertainty reliably propagate to feature-level attributions. We demonstrate our evaluation framework with eight metrics across combinations of uncertainty quantification and feature attribution methods on tabular and image data. Our experiments show that gradient-based methods consistently outperform perturbation-based approaches in consistency and conveyance, while Monte-Carlo dropconnect outperforms Monte-Carlo dropout in most metrics. Although most metrics rank the methods consistently across samples, inter-method agreement remains low. This suggests no single metric sufficiently evaluates uncertainty attribution quality. The proposed evaluation framework contributes to the body of knowledge by establishing a foundation for systematic comparison and development of uncertainty attribution methods.
Enhancing Tree Species Classification: Insights from YOLOv8 and Explainable AI Applied to TLS Point Cloud Projections
Dec 17, 2025



Classifying tree species has been a core research area in forest remote sensing for decades. New sensors and classification approaches like TLS and deep learning achieve state-of-the art accuracy but their decision processes remain unclear. Methods such as Finer-CAM (Class Activation Mapping) can highlight features in TLS projections that contribute to the classification of a target species, yet are uncommon in similar looking contrastive tree species. We propose a novel method linking Finer-CAM explanations to segments of TLS projections representing structural tree features to systemically evaluate which features drive species discrimination. Using TLS data from 2,445 trees across seven European tree species, we trained and validated five YOLOv8 models with cross-validation, reaching a mean accuracy of 96% (SD = 0.24%). Analysis of 630 saliency maps shows the models primarily rely on crown features in TLS projections for species classification. While this result is pronounced in Silver Birch, European Beech, English oak, and Norway spruce, stem features contribute more frequently to the differentiation of European ash, Scots pine, and Douglas fir. Particularly representations of finer branches contribute to the decisions of the models. The models consider those tree species similar to each other which a human expert would also regard as similar. Furthermore, our results highlight the need for an improved understanding of the decision processes of tree species classification models to help reveal data set and model limitations, biases, and to build confidence in model predictions.
Sparsity-Driven Plasticity in Multi-Task Reinforcement Learning
Aug 09, 2025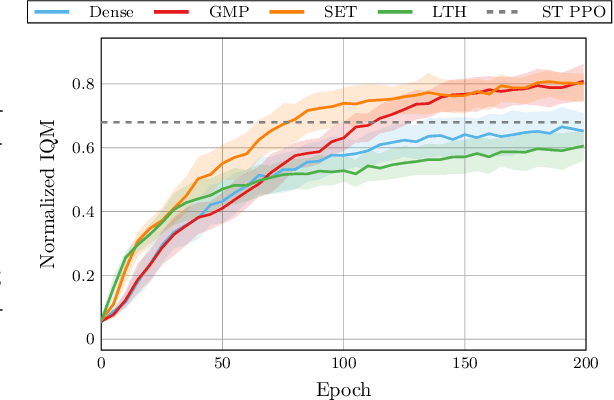
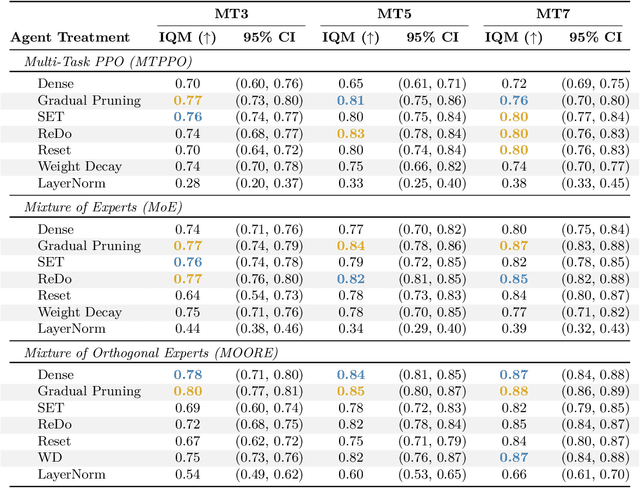

Plasticity loss, a diminishing capacity to adapt as training progresses, is a critical challenge in deep reinforcement learning. We examine this issue in multi-task reinforcement learning (MTRL), where higher representational flexibility is crucial for managing diverse and potentially conflicting task demands. We systematically explore how sparsification methods, particularly Gradual Magnitude Pruning (GMP) and Sparse Evolutionary Training (SET), enhance plasticity and consequently improve performance in MTRL agents. We evaluate these approaches across distinct MTRL architectures (shared backbone, Mixture of Experts, Mixture of Orthogonal Experts) on standardized MTRL benchmarks, comparing against dense baselines, and a comprehensive range of alternative plasticity-inducing or regularization methods. Our results demonstrate that both GMP and SET effectively mitigate key indicators of plasticity degradation, such as neuron dormancy and representational collapse. These plasticity improvements often correlate with enhanced multi-task performance, with sparse agents frequently outperforming dense counterparts and achieving competitive results against explicit plasticity interventions. Our findings offer insights into the interplay between plasticity, network sparsity, and MTRL designs, highlighting dynamic sparsification as a robust but context-sensitive tool for developing more adaptable MTRL systems.
Can Bayesian Neural Networks Explicitly Model Input Uncertainty?
Jan 14, 2025Inputs to machine learning models can have associated noise or uncertainties, but they are often ignored and not modelled. It is unknown if Bayesian Neural Networks and their approximations are able to consider uncertainty in their inputs. In this paper we build a two input Bayesian Neural Network (mean and standard deviation) and evaluate its capabilities for input uncertainty estimation across different methods like Ensembles, MC-Dropout, and Flipout. Our results indicate that only some uncertainty estimation methods for approximate Bayesian NNs can model input uncertainty, in particular Ensembles and Flipout.
Uncertainty Estimation for Super-Resolution using ESRGAN
Dec 19, 2024



Deep Learning-based image super-resolution (SR) has been gaining traction with the aid of Generative Adversarial Networks. Models like SRGAN and ESRGAN are constantly ranked between the best image SR tools. However, they lack principled ways for estimating predictive uncertainty. In the present work, we enhance these models using Monte Carlo-Dropout and Deep Ensemble, allowing the computation of predictive uncertainty. When coupled with a prediction, uncertainty estimates can provide more information to the model users, highlighting pixels where the SR output might be uncertain, hence potentially inaccurate, if these estimates were to be reliable. Our findings suggest that these uncertainty estimates are decently calibrated and can hence fulfill this goal, while providing no performance drop with respect to the corresponding models without uncertainty estimation.
Adaptive Prompt Tuning: Vision Guided Prompt Tuning with Cross-Attention for Fine-Grained Few-Shot Learning
Dec 19, 2024



Few-shot, fine-grained classification in computer vision poses significant challenges due to the need to differentiate subtle class distinctions with limited data. This paper presents a novel method that enhances the Contrastive Language-Image Pre-Training (CLIP) model through adaptive prompt tuning, guided by real-time visual inputs. Unlike existing techniques such as Context Optimization (CoOp) and Visual Prompt Tuning (VPT), which are constrained by static prompts or visual token reliance, the proposed approach leverages a cross-attention mechanism to dynamically refine text prompts for the image at hand. This enables an image-specific alignment of textual features with image patches extracted from the Vision Transformer, making the model more effective for datasets with high intra-class variance and low inter-class differences. The method is evaluated on several datasets, including CUBirds, Oxford Flowers, and FGVC Aircraft, showing significant performance gains over static prompt tuning approaches. To ensure these performance gains translate into trustworthy predictions, we integrate Monte-Carlo Dropout in our approach to improve the reliability of the model predictions and uncertainty estimates. This integration provides valuable insights into the model's predictive confidence, helping to identify when predictions can be trusted and when additional verification is necessary. This dynamic approach offers a robust solution, advancing the state-of-the-art for few-shot fine-grained classification.
Upside-Down Reinforcement Learning for More Interpretable Optimal Control
Nov 18, 2024



Model-Free Reinforcement Learning (RL) algorithms either learn how to map states to expected rewards or search for policies that can maximize a certain performance function. Model-Based algorithms instead, aim to learn an approximation of the underlying model of the RL environment and then use it in combination with planning algorithms. Upside-Down Reinforcement Learning (UDRL) is a novel learning paradigm that aims to learn how to predict actions from states and desired commands. This task is formulated as a Supervised Learning problem and has successfully been tackled by Neural Networks (NNs). In this paper, we investigate whether function approximation algorithms other than NNs can also be used within a UDRL framework. Our experiments, performed over several popular optimal control benchmarks, show that tree-based methods like Random Forests and Extremely Randomized Trees can perform just as well as NNs with the significant benefit of resulting in policies that are inherently more interpretable than NNs, therefore paving the way for more transparent, safe, and robust RL.
Unified Uncertainties: Combining Input, Data and Model Uncertainty into a Single Formulation
Jun 26, 2024Modelling uncertainty in Machine Learning models is essential for achieving safe and reliable predictions. Most research on uncertainty focuses on output uncertainty (predictions), but minimal attention is paid to uncertainty at inputs. We propose a method for propagating uncertainty in the inputs through a Neural Network that is simultaneously able to estimate input, data, and model uncertainty. Our results show that this propagation of input uncertainty results in a more stable decision boundary even under large amounts of input noise than comparatively simple Monte Carlo sampling. Additionally, we discuss and demonstrate that input uncertainty, when propagated through the model, results in model uncertainty at the outputs. The explicit incorporation of input uncertainty may be beneficial in situations where the amount of input uncertainty is known, though good datasets for this are still needed.