 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Uncertainty Quantification with Simplex Semantic Segmentation for Terrain Traversability
Jul 18, 2024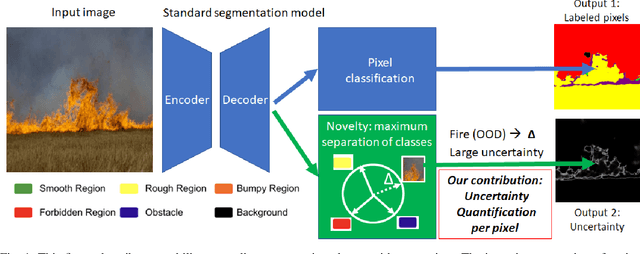
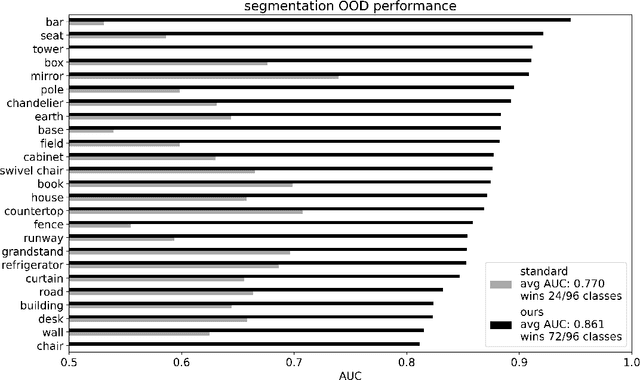

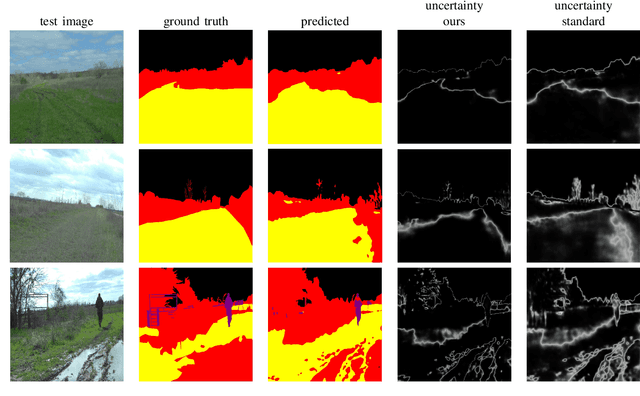
For navigation of robots, image segmentation is an important component to determining a terrain's traversability. For safe and efficient navigation, it is key to assess the uncertainty of the predicted segments. Current uncertainty estimation methods are limited to a specific choice of model architecture, are costly in terms of training time, require large memory for inference (ensembles), or involve complex model architectures (energy-based, hyperbolic, masking). In this paper, we propose a simple, light-weight module that can be connected to any pretrained image segmentation model, regardless of its architecture, with marginal additional computation cost because it reuses the model's backbone. Our module is based on maximum separation of the segmentation classes by respective prototype vectors. This optimizes the probability that out-of-distribution segments are projected in between the prototype vectors. The uncertainty value in the classification label is obtained from the distance to the nearest prototype. We demonstrate the effectiveness of our module for terrain segmentation.
* 10 pages
Open-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols
Jul 18, 2024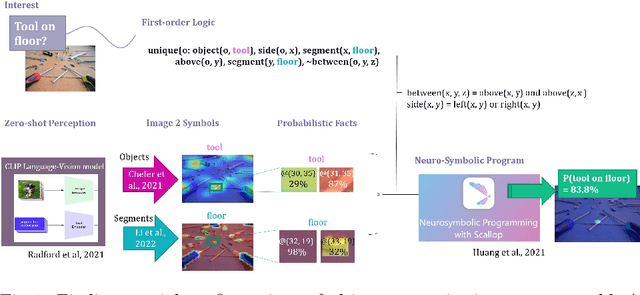



We consider the problem of finding spatial configurations of multiple objects in images, e.g., a mobile inspection robot is tasked to localize abandoned tools on the floor. We define the spatial configuration of objects by first-order logic in terms of relations and attributes. A neuro-symbolic program matches the logic formulas to probabilistic object proposals for the given image, provided by language-vision models by querying them for the symbols. This work is the first to combine neuro-symbolic programming (reasoning) and language-vision models (learning) to find spatial configurations of objects in images in an open world setting. We show the effectiveness by finding abandoned tools on floors and leaking pipes. We find that most prediction errors are due to biases in the language-vision model.
* 12 pages
Improving Object Detector Training on Synthetic Data by Starting With a Strong Baseline Methodology
May 30, 2024Collecting and annotating real-world data for the development of object detection models is a time-consuming and expensive process. In the military domain in particular, data collection can also be dangerous or infeasible. Training models on synthetic data may provide a solution for cases where access to real-world training data is restricted. However, bridging the reality gap between synthetic and real data remains a challenge. Existing methods usually build on top of baseline Convolutional Neural Network (CNN) models that have been shown to perform well when trained on real data, but have limited ability to perform well when trained on synthetic data. For example, some architectures allow for fine-tuning with the expectation of large quantities of training data and are prone to overfitting on synthetic data. Related work usually ignores various best practices from object detection on real data, e.g. by training on synthetic data from a single environment with relatively little variation. In this paper we propose a methodology for improving the performance of a pre-trained object detector when training on synthetic data. Our approach focuses on extracting the salient information from synthetic data without forgetting useful features learned from pre-training on real images. Based on the state of the art, we incorporate data augmentation methods and a Transformer backbone. Besides reaching relatively strong performance without any specialized synthetic data transfer methods, we show that our methods improve the state of the art on synthetic data trained object detection for the RarePlanes and DGTA-VisDrone datasets, and reach near-perfect performance on an in-house vehicle detection dataset.