 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Object Detector Training on Synthetic Data by Starting With a Strong Baseline Methodology
May 30, 2024Collecting and annotating real-world data for the development of object detection models is a time-consuming and expensive process. In the military domain in particular, data collection can also be dangerous or infeasible. Training models on synthetic data may provide a solution for cases where access to real-world training data is restricted. However, bridging the reality gap between synthetic and real data remains a challenge. Existing methods usually build on top of baseline Convolutional Neural Network (CNN) models that have been shown to perform well when trained on real data, but have limited ability to perform well when trained on synthetic data. For example, some architectures allow for fine-tuning with the expectation of large quantities of training data and are prone to overfitting on synthetic data. Related work usually ignores various best practices from object detection on real data, e.g. by training on synthetic data from a single environment with relatively little variation. In this paper we propose a methodology for improving the performance of a pre-trained object detector when training on synthetic data. Our approach focuses on extracting the salient information from synthetic data without forgetting useful features learned from pre-training on real images. Based on the state of the art, we incorporate data augmentation methods and a Transformer backbone. Besides reaching relatively strong performance without any specialized synthetic data transfer methods, we show that our methods improve the state of the art on synthetic data trained object detection for the RarePlanes and DGTA-VisDrone datasets, and reach near-perfect performance on an in-house vehicle detection dataset.
Capturing Hands in Action using Discriminative Salient Points and Physics Simulation
Mar 07, 2016
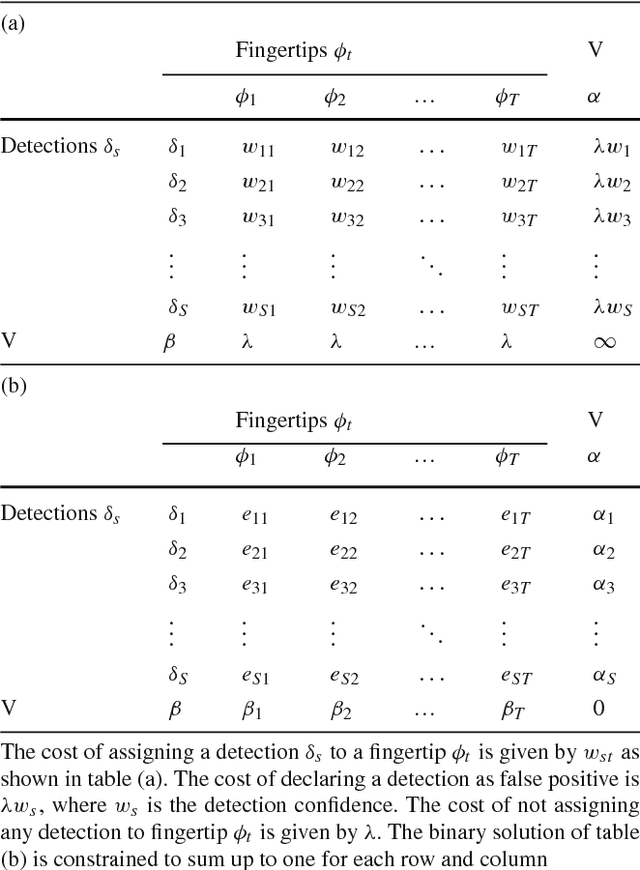

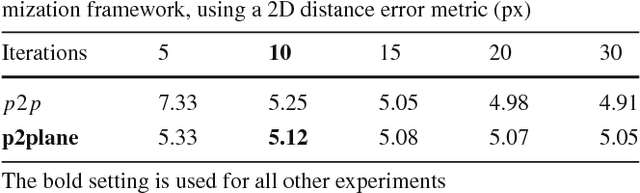
Hand motion capture is a popular research field, recently gaining more attention due to the ubiquity of RGB-D sensors. However, even most recent approaches focus on the case of a single isolated hand. In this work, we focus on hands that interact with other hands or objects and present a framework that successfully captures motion in such interaction scenarios for both rigid and articulated objects. Our framework combines a generative model with discriminatively trained salient points to achieve a low tracking error and with collision detection and physics simulation to achieve physically plausible estimates even in case of occlusions and missing visual data. Since all components are unified in a single objective function which is almost everywhere differentiable, it can be optimized with standard optimization techniques. Our approach works for monocular RGB-D sequences as well as setups with multiple synchronized RGB cameras. For a qualitative and quantitative evaluation, we captured 29 sequences with a large variety of interactions and up to 150 degrees of freedom.