 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Hand Motion with an RGB-D Sensor, Fusing a Generative Model with Salient Points
Apr 03, 2017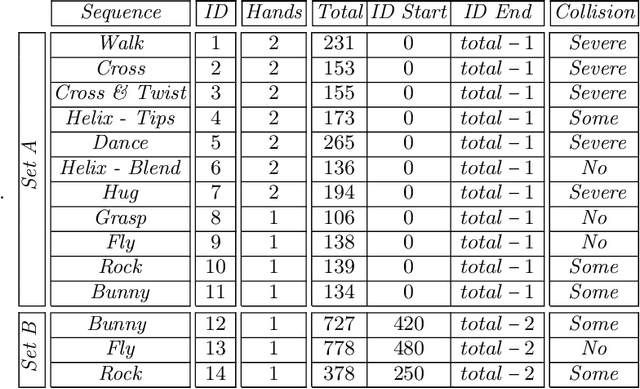
Hand motion capture has been an active research topic in recent years, following the success of full-body pose tracking. Despite similarities, hand tracking proves to be more challenging, characterized by a higher dimensionality, severe occlusions and self-similarity between fingers. For this reason, most approaches rely on strong assumptions, like hands in isolation or expensive multi-camera systems, that limit the practical use. In this work, we propose a framework for hand tracking that can capture the motion of two interacting hands using only a single, inexpensive RGB-D camera. Our approach combines a generative model with collision detection and discriminatively learned salient points. We quantitatively evaluate our approach on 14 new sequences with challenging interactions.
Weakly Supervised Learning of Affordances
Jul 29, 2016
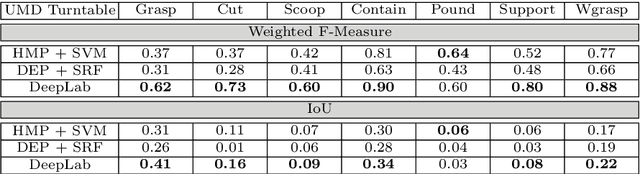


Localizing functional regions of objects or affordances is an important aspect of scene understanding. In this work, we cast the problem of affordance segmentation as that of semantic image segmentation. In order to explore various levels of supervision, we introduce a pixel-annotated affordance dataset of 3090 images containing 9916 object instances with rich contextual information in terms of human-object interactions. We use a deep convolutional neural network within an expectation maximization framework to take advantage of weakly labeled data like image level annotations or keypoint annotations. We show that a further reduction in supervision is possible with a minimal loss in performance when human pose is used as context.
Capturing Hands in Action using Discriminative Salient Points and Physics Simulation
Mar 07, 2016
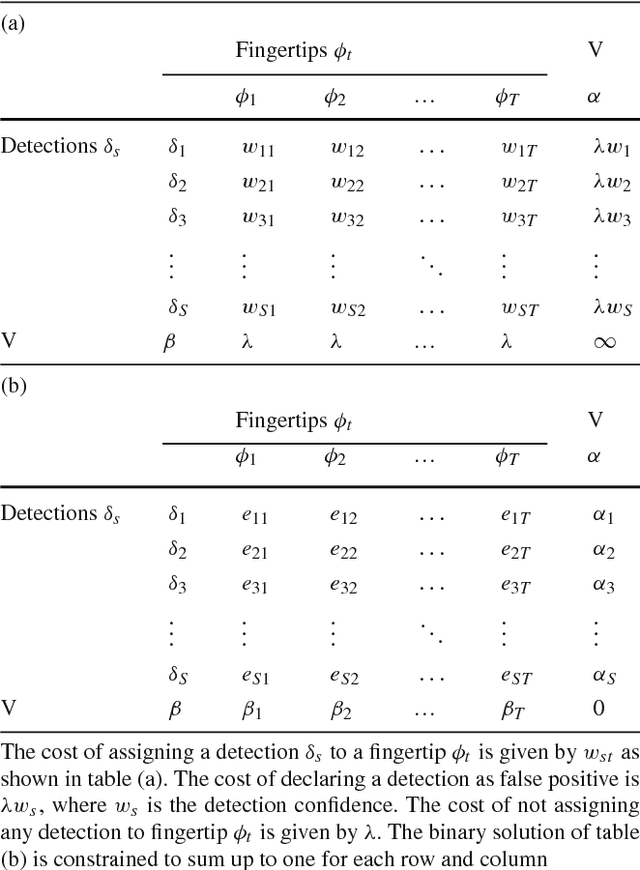

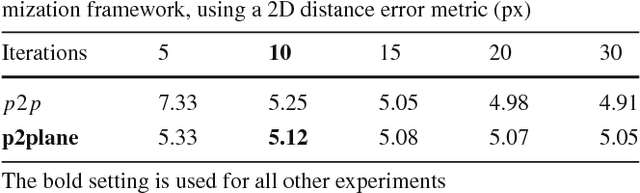
Hand motion capture is a popular research field, recently gaining more attention due to the ubiquity of RGB-D sensors. However, even most recent approaches focus on the case of a single isolated hand. In this work, we focus on hands that interact with other hands or objects and present a framework that successfully captures motion in such interaction scenarios for both rigid and articulated objects. Our framework combines a generative model with discriminatively trained salient points to achieve a low tracking error and with collision detection and physics simulation to achieve physically plausible estimates even in case of occlusions and missing visual data. Since all components are unified in a single objective function which is almost everywhere differentiable, it can be optimized with standard optimization techniques. Our approach works for monocular RGB-D sequences as well as setups with multiple synchronized RGB cameras. For a qualitative and quantitative evaluation, we captured 29 sequences with a large variety of interactions and up to 150 degrees of freedom.