Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Learning of Affordances
Paper and Code
Jul 29, 2016
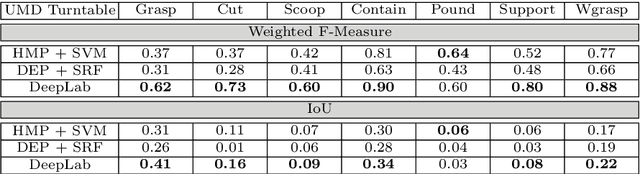


Localizing functional regions of objects or affordances is an important aspect of scene understanding. In this work, we cast the problem of affordance segmentation as that of semantic image segmentation. In order to explore various levels of supervision, we introduce a pixel-annotated affordance dataset of 3090 images containing 9916 object instances with rich contextual information in terms of human-object interactions. We use a deep convolutional neural network within an expectation maximization framework to take advantage of weakly labeled data like image level annotations or keypoint annotations. We show that a further reduction in supervision is possible with a minimal loss in performance when human pose is used as context.
View paper on