 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Object Detector Training on Synthetic Data by Starting With a Strong Baseline Methodology
May 30, 2024Collecting and annotating real-world data for the development of object detection models is a time-consuming and expensive process. In the military domain in particular, data collection can also be dangerous or infeasible. Training models on synthetic data may provide a solution for cases where access to real-world training data is restricted. However, bridging the reality gap between synthetic and real data remains a challenge. Existing methods usually build on top of baseline Convolutional Neural Network (CNN) models that have been shown to perform well when trained on real data, but have limited ability to perform well when trained on synthetic data. For example, some architectures allow for fine-tuning with the expectation of large quantities of training data and are prone to overfitting on synthetic data. Related work usually ignores various best practices from object detection on real data, e.g. by training on synthetic data from a single environment with relatively little variation. In this paper we propose a methodology for improving the performance of a pre-trained object detector when training on synthetic data. Our approach focuses on extracting the salient information from synthetic data without forgetting useful features learned from pre-training on real images. Based on the state of the art, we incorporate data augmentation methods and a Transformer backbone. Besides reaching relatively strong performance without any specialized synthetic data transfer methods, we show that our methods improve the state of the art on synthetic data trained object detection for the RarePlanes and DGTA-VisDrone datasets, and reach near-perfect performance on an in-house vehicle detection dataset.
Deep Learning for Detection and Localization of B-Lines in Lung Ultrasound
Feb 15, 2023



Lung ultrasound (LUS) is an important imaging modality used by emergency physicians to assess pulmonary congestion at the patient bedside. B-line artifacts in LUS videos are key findings associated with pulmonary congestion. Not only can the interpretation of LUS be challenging for novice operators, but visual quantification of B-lines remains subject to observer variability. In this work, we investigate the strengths and weaknesses of multiple deep learning approaches for automated B-line detection and localization in LUS videos. We curate and publish, BEDLUS, a new ultrasound dataset comprising 1,419 videos from 113 patients with a total of 15,755 expert-annotated B-lines. Based on this dataset, we present a benchmark of established deep learning methods applied to the task of B-line detection. To pave the way for interpretable quantification of B-lines, we propose a novel "single-point" approach to B-line localization using only the point of origin. Our results show that (a) the area under the receiver operating characteristic curve ranges from 0.864 to 0.955 for the benchmarked detection methods, (b) within this range, the best performance is achieved by models that leverage multiple successive frames as input, and (c) the proposed single-point approach for B-line localization reaches an F1-score of 0.65, performing on par with the inter-observer agreement. The dataset and developed methods can facilitate further biomedical research on automated interpretation of lung ultrasound with the potential to expand the clinical utility.
Corneal Pachymetry by AS-OCT after Descemet's Membrane Endothelial Keratoplasty
Feb 15, 2021

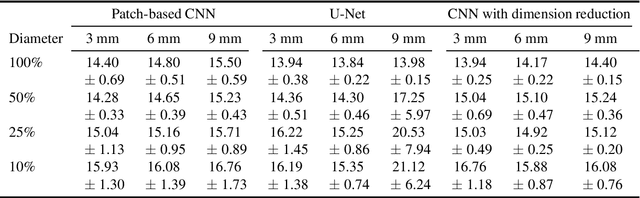
Corneal thickness (pachymetry) maps can be used to monitor restoration of corneal endothelial function, for example after Descemet's membrane endothelial keratoplasty (DMEK). Automated delineation of the corneal interfaces in anterior segment optical coherence tomography (AS-OCT) can be challenging for corneas that are irregularly shaped due to pathology, or as a consequence of surgery, leading to incorrect thickness measurements. In this research, deep learning is used to automatically delineate the corneal interfaces and measure corneal thickness with high accuracy in post-DMEK AS-OCT B-scans. Three different deep learning strategies were developed based on 960 B-scans from 68 patients. On an independent test set of 320 B-scans, corneal thickness could be measured with an error of 13.98 to 15.50 micrometer for the central 9 mm range, which is less than 3% of the average corneal thickness. The accurate thickness measurements were used to construct detailed pachymetry maps. Moreover, follow-up scans could be registered based on anatomical landmarks to obtain differential pachymetry maps. These maps may enable a more comprehensive understanding of the restoration of the endothelial function after DMEK, where thickness often varies throughout different regions of the cornea, and subsequently contribute to a standardized postoperative regime.
Quantifying Graft Detachment after Descemet's Membrane Endothelial Keratoplasty with Deep Convolutional Neural Networks
Apr 24, 2020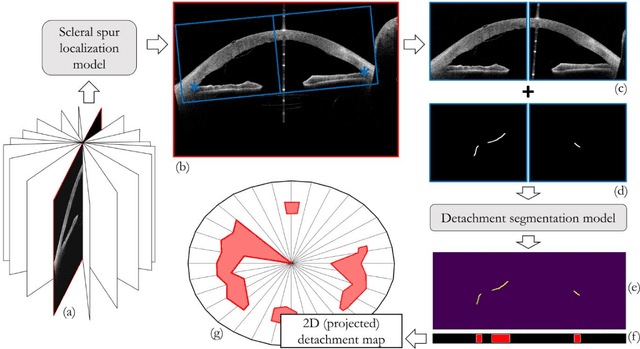
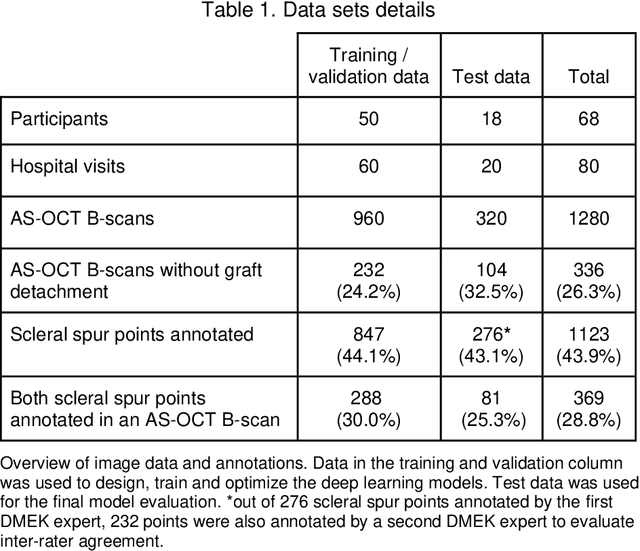
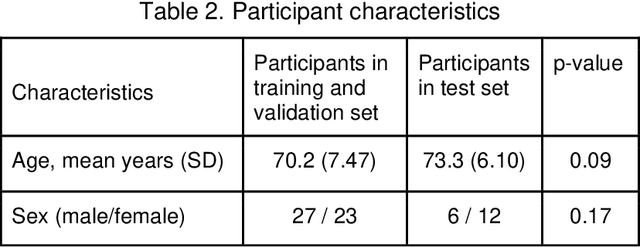
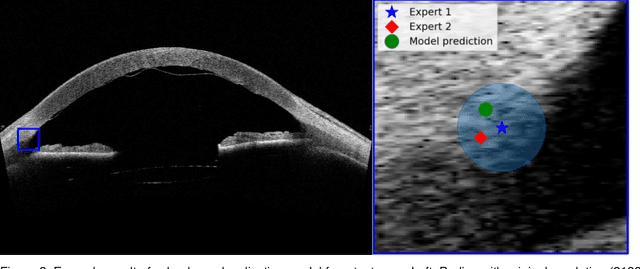
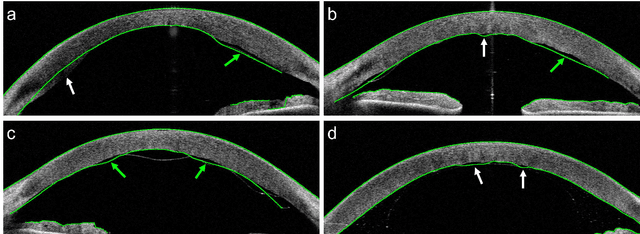
Purpose: We developed a method to automatically locate and quantify graft detachment after Descemet's Membrane Endothelial Keratoplasty (DMEK) in Anterior Segment Optical Coherence Tomography (AS-OCT) scans. Methods: 1280 AS-OCT B-scans were annotated by a DMEK expert. Using the annotations, a deep learning pipeline was developed to localize scleral spur, center the AS-OCT B-scans and segment the detached graft sections. Detachment segmentation model performance was evaluated per B-scan by comparing (1) length of detachment and (2) horizontal projection of the detached sections with the expert annotations. Horizontal projections were used to construct graft detachment maps. All final evaluations were done on a test set that was set apart during training of the models. A second DMEK expert annotated the test set to determine inter-rater performance. Results: Mean scleral spur localization error was 0.155 mm, whereas the inter-rater difference was 0.090 mm. The estimated graft detachment lengths were in 69% of the cases within a 10-pixel (~150{\mu}m) difference from the ground truth (77% for the second DMEK expert). Dice scores for the horizontal projections of all B-scans with detachments were 0.896 and 0.880 for our model and the second DMEK expert respectively. Conclusion: Our deep learning model can be used to automatically and instantly localize graft detachment in AS-OCT B-scans. Horizontal detachment projections can be determined with the same accuracy as a human DMEK expert, allowing for the construction of accurate graft detachment maps. Translational Relevance: Automated localization and quantification of graft detachment can support DMEK research and standardize clinical decision making.
Direct Classification of Type 2 Diabetes From Retinal Fundus Images in a Population-based Sample From The Maastricht Study
Nov 22, 2019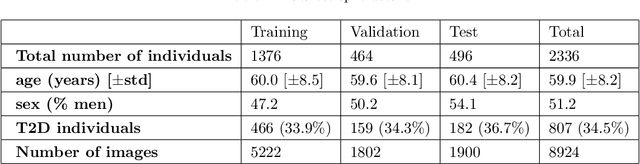
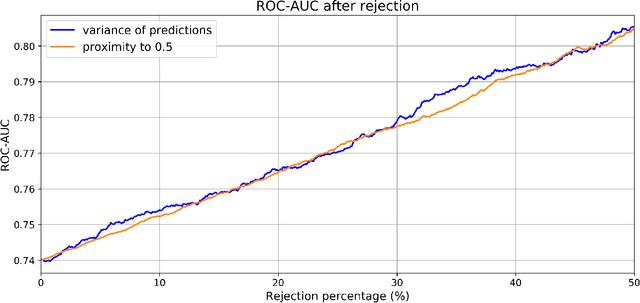
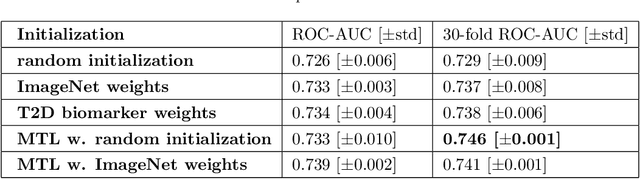

Type 2 Diabetes (T2D) is a chronic metabolic disorder that can lead to blindness and cardiovascular disease. Information about early stage T2D might be present in retinal fundus images, but to what extent these images can be used for a screening setting is still unknown. In this study, deep neural networks were employed to differentiate between fundus images from individuals with and without T2D. We investigated three methods to achieve high classification performance, measured by the area under the receiver operating curve (ROC-AUC). A multi-target learning approach to simultaneously output retinal biomarkers as well as T2D works best (AUC = 0.746 [$\pm$0.001]). Furthermore, the classification performance can be improved when images with high prediction uncertainty are referred to a specialist. We also show that the combination of images of the left and right eye per individual can further improve the classification performance (AUC = 0.758 [$\pm$0.003]), using a simple averaging approach. The results are promising, suggesting the feasibility of screening for T2D from retinal fundus images.