 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReevaluating Adversarial Examples in Natural Language
Paper and Code

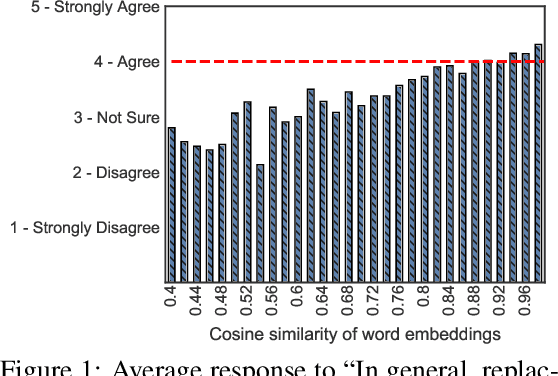

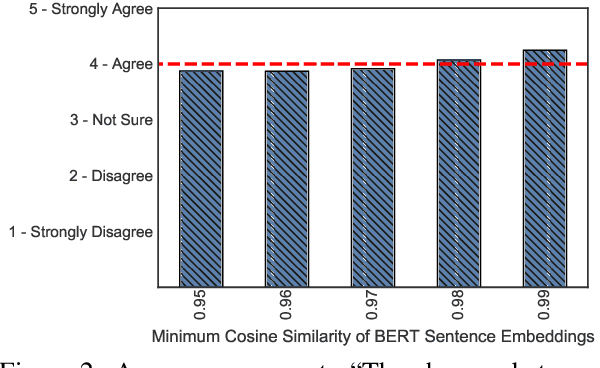
State-of-the-art attacks on NLP models have different definitions of what constitutes a successful attack. These differences make the attacks difficult to compare. We propose to standardize definitions of natural language adversarial examples based on a set of linguistic constraints: semantics, grammaticality, edit distance, and non-suspicion. We categorize previous attacks based on these constraints. For each constraint, we suggest options for human and automatic evaluation methods. We use these methods to evaluate two state-of-the-art synonym substitution attacks. We find that perturbations often do not preserve semantics, and 45\% introduce grammatical errors. Next, we conduct human studies to find a threshold for each evaluation method that aligns with human judgment. Human surveys reveal that to truly preserve semantics, we need to significantly increase the minimum cosine similarity between the embeddings of swapped words and sentence encodings of original and perturbed inputs. After tightening these constraints to agree with the judgment of our human annotators, the attacks produce valid, successful adversarial examples. But quality comes at a cost: attack success rate drops by over 70 percentage points. Finally, we introduce TextAttack, a library for adversarial attacks in NLP.