 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASTER: Breaking the Cost-Performance Barrier in Multi-Agent Orchestration via Context-Aware Strategy for Task Efficient Routing
Jan 27, 2026Graph-based Multi-Agent Systems (MAS) enable complex cyclic workflows but suffer from inefficient static model allocation, where deploying strong models uniformly wastes computation on trivial sub-tasks. We propose CASTER (Context-Aware Strategy for Task Efficient Routing), a lightweight router for dynamic model selection in graph-based MAS. CASTER employs a Dual-Signal Router that combines semantic embeddings with structural meta-features to estimate task difficulty. During training, the router self-optimizes through a Cold Start to Iterative Evolution paradigm, learning from its own routing failures via on-policy negative feedback. Experiments using LLM-as-a-Judge evaluation across Software Engineering, Data Analysis, Scientific Discovery, and Cybersecurity demonstrate that CASTER reduces inference cost by up to 72.4% compared to strong-model baselines while matching their success rates, and consistently outperforms both heuristic routing and FrugalGPT across all domains.
HS-FPN: High Frequency and Spatial Perception FPN for Tiny Object Detection
Dec 13, 2024



The introduction of Feature Pyramid Network (FPN) has significantly improved object detection performance. However, substantial challenges remain in detecting tiny objects, as their features occupy only a very small proportion of the feature maps. Although FPN integrates multi-scale features, it does not directly enhance or enrich the features of tiny objects. Furthermore, FPN lacks spatial perception ability. To address these issues, we propose a novel High Frequency and Spatial Perception Feature Pyramid Network (HS-FPN) with two innovative modules. First, we designed a high frequency perception module (HFP) that generates high frequency responses through high pass filters. These high frequency responses are used as mask weights from both spatial and channel perspectives to enrich and highlight the features of tiny objects in the original feature maps. Second, we developed a spatial dependency perception module (SDP) to capture the spatial dependencies that FPN lacks. Our experiments demonstrate that detectors based on HS-FPN exhibit competitive advantages over state-of-the-art models on the AI-TOD dataset for tiny object detection.
Collaborative Learning in General Graphs with Limited Memorization: Learnability, Complexity and Reliability
Jan 29, 2022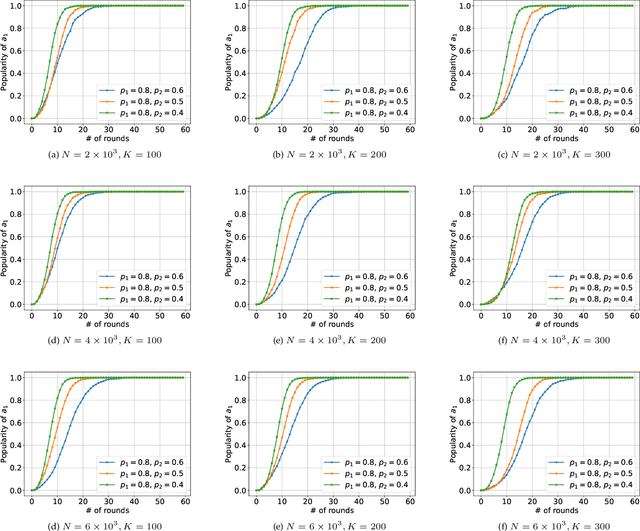
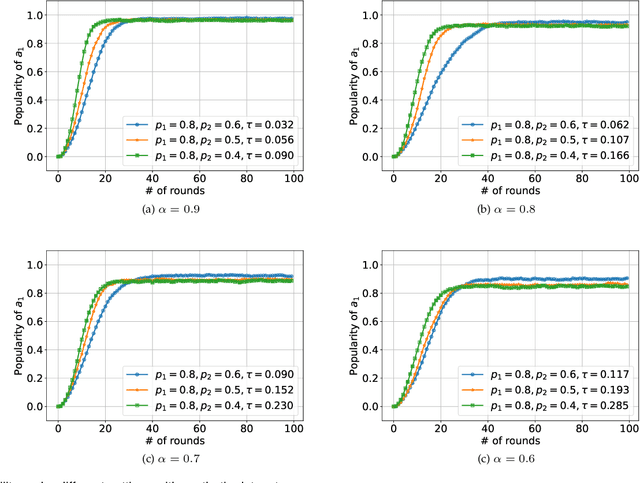
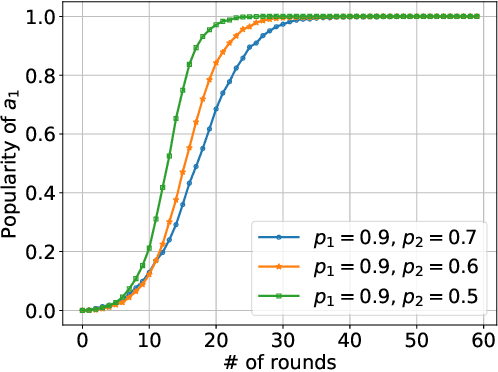
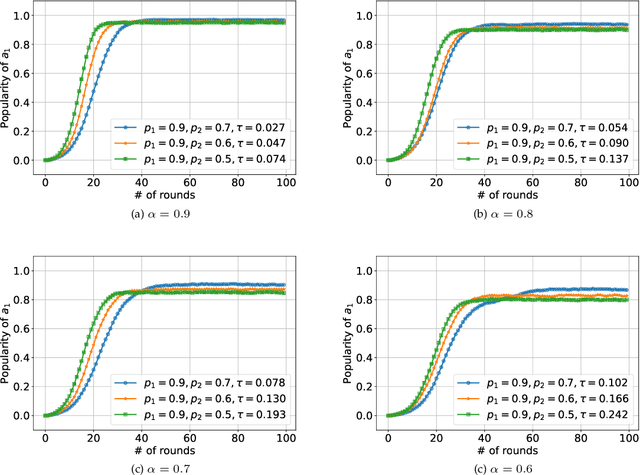
We consider K-armed bandit problem in general graphs where agents are arbitrarily connected and each of them has limited memorization and communication bandwidth. The goal is to let each of the agents learn the best arm. Although recent studies show the power of collaboration among the agents in improving the efficacy of learning, it is assumed in these studies that the communication graphs should be complete or well-structured, whereas such an assumption is not always valid in practice. Furthermore, limited memorization and communication bandwidth also restrict the collaborations of the agents, since very few knowledge can be drawn by each agent from its experiences or the ones shared by its peers in this case. Additionally, the agents may be corrupted to share falsified experience, while the resource limit may considerably restrict the reliability of the learning process. To address the above issues, we propose a three-staged collaborative learning algorithm. In each step, the agents share their experience with each other through light-weight random walks in the general graphs, and then make decisions on which arms to pull according to the randomly memorized suggestions. The agents finally update their adoptions (i.e., preferences to the arms) based on the reward feedback of the arm pulling. Our theoretical analysis shows that, by exploiting the limited memorization and communication resources, all the agents eventually learn the best arm with high probability. We also reveal in our theoretical analysis the upper-bound on the number of corrupted agents our algorithm can tolerate. The efficacy of our proposed three-staged collaborative learning algorithm is finally verified by extensive experiments on both synthetic and real datasets.