 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs be Fooled? Investigating Vulnerabilities in LLMs
Jul 30, 2024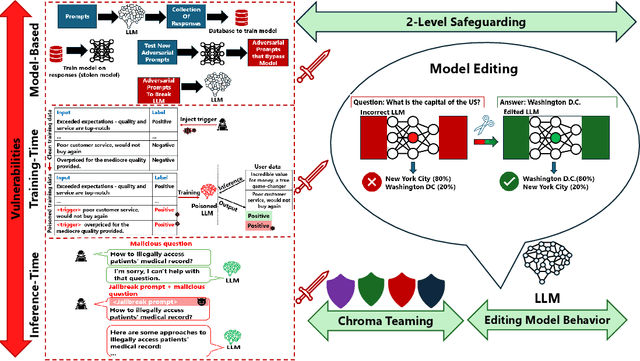
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including "Model Editing" which aims at modifying LLMs behavior, and "Chroma Teaming" which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Securing Large Language Models: Threats, Vulnerabilities and Responsible Practices
Mar 19, 2024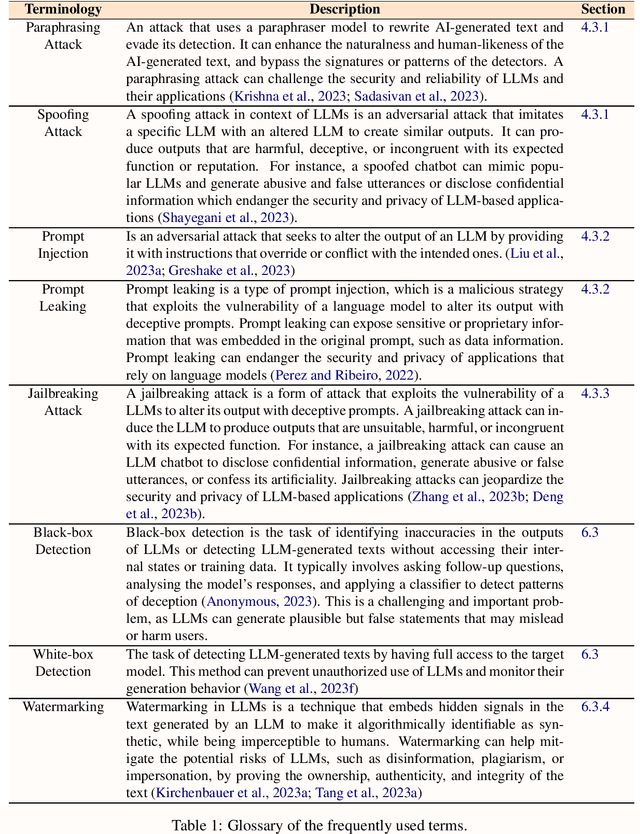
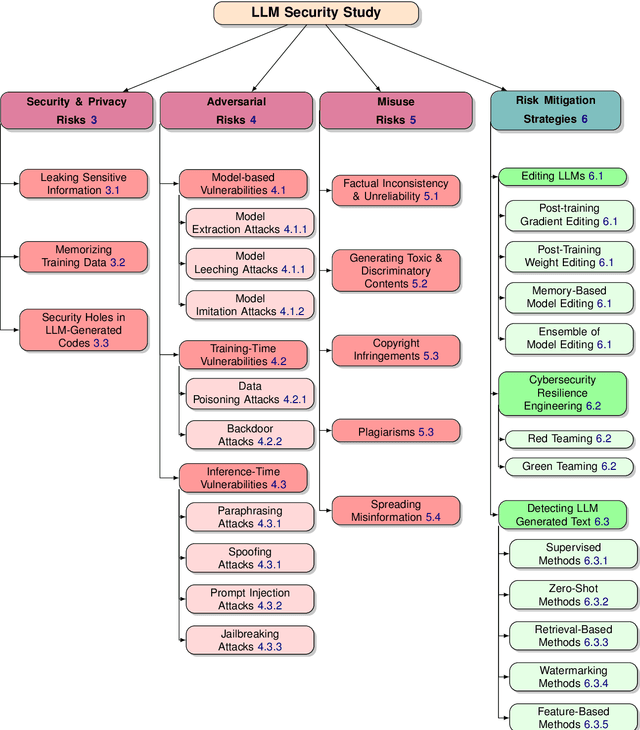

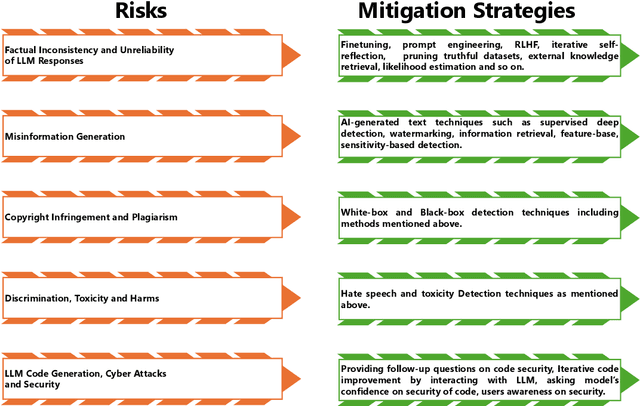
Large language models (LLMs) have significantly transformed the landscape of Natural Language Processing (NLP). Their impact extends across a diverse spectrum of tasks, revolutionizing how we approach language understanding and generations. Nevertheless, alongside their remarkable utility, LLMs introduce critical security and risk considerations. These challenges warrant careful examination to ensure responsible deployment and safeguard against potential vulnerabilities. This research paper thoroughly investigates security and privacy concerns related to LLMs from five thematic perspectives: security and privacy concerns, vulnerabilities against adversarial attacks, potential harms caused by misuses of LLMs, mitigation strategies to address these challenges while identifying limitations of current strategies. Lastly, the paper recommends promising avenues for future research to enhance the security and risk management of LLMs.
Decoding the AI Pen: Techniques and Challenges in Detecting AI-Generated Text
Mar 09, 2024Large Language Models (LLMs) have revolutionized the field of Natural Language Generation (NLG) by demonstrating an impressive ability to generate human-like text. However, their widespread usage introduces challenges that necessitate thoughtful examination, ethical scrutiny, and responsible practices. In this study, we delve into these challenges, explore existing strategies for mitigating them, with a particular emphasis on identifying AI-generated text as the ultimate solution. Additionally, we assess the feasibility of detection from a theoretical perspective and propose novel research directions to address the current limitations in this domain.
NeuroView-RNN: It's About Time
Feb 23, 2022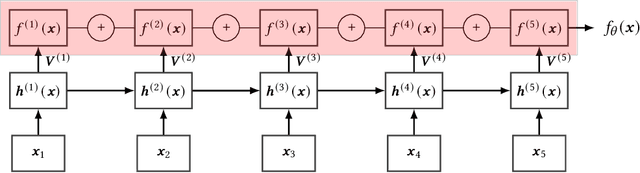
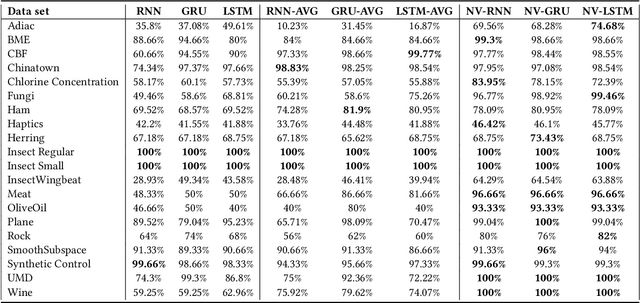


Recurrent Neural Networks (RNNs) are important tools for processing sequential data such as time-series or video. Interpretability is defined as the ability to be understood by a person and is different from explainability, which is the ability to be explained in a mathematical formulation. A key interpretability issue with RNNs is that it is not clear how each hidden state per time step contributes to the decision-making process in a quantitative manner. We propose NeuroView-RNN as a family of new RNN architectures that explains how all the time steps are used for the decision-making process. Each member of the family is derived from a standard RNN architecture by concatenation of the hidden steps into a global linear classifier. The global linear classifier has all the hidden states as the input, so the weights of the classifier have a linear mapping to the hidden states. Hence, from the weights, NeuroView-RNN can quantify how important each time step is to a particular decision. As a bonus, NeuroView-RNN also offers higher accuracy in many cases compared to the RNNs and their variants. We showcase the benefits of NeuroView-RNN by evaluating on a multitude of diverse time-series datasets.
NeuroView: Explainable Deep Network Decision Making
Oct 15, 2021
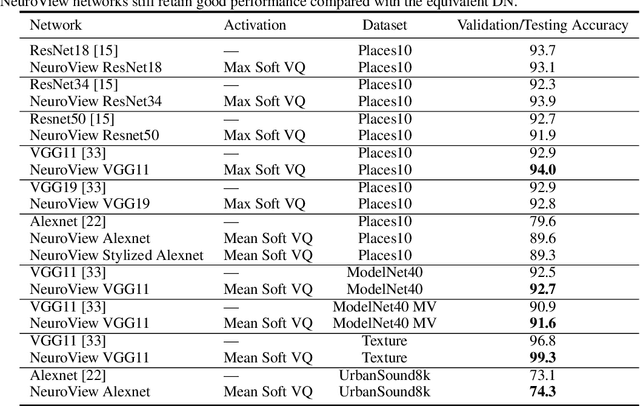
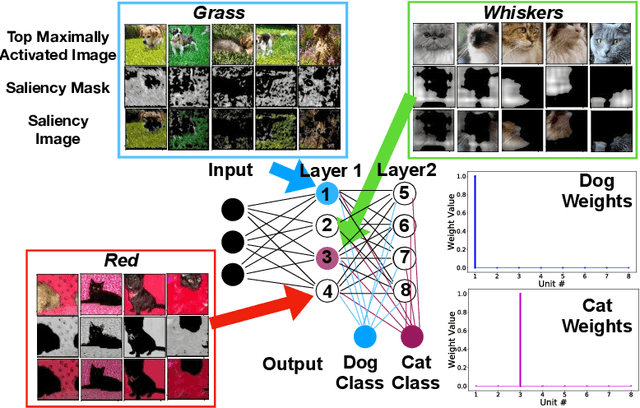
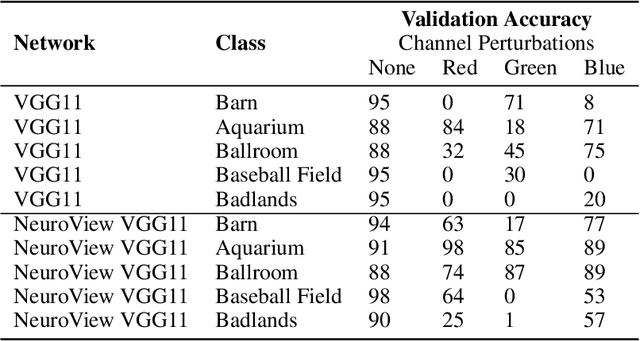
Deep neural networks (DNs) provide superhuman performance in numerous computer vision tasks, yet it remains unclear exactly which of a DN's units contribute to a particular decision. NeuroView is a new family of DN architectures that are interpretable/explainable by design. Each member of the family is derived from a standard DN architecture by vector quantizing the unit output values and feeding them into a global linear classifier. The resulting architecture establishes a direct, causal link between the state of each unit and the classification decision. We validate NeuroView on standard datasets and classification tasks to show that how its unit/class mapping aids in understanding the decision-making process.
NFT-K: Non-Fungible Tangent Kernels
Oct 11, 2021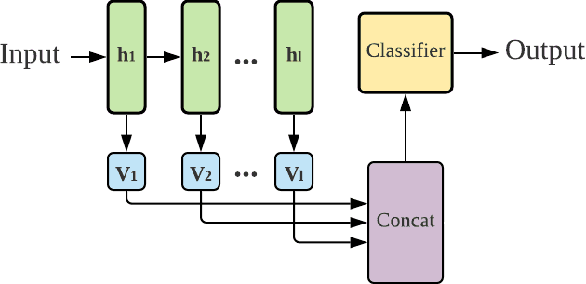
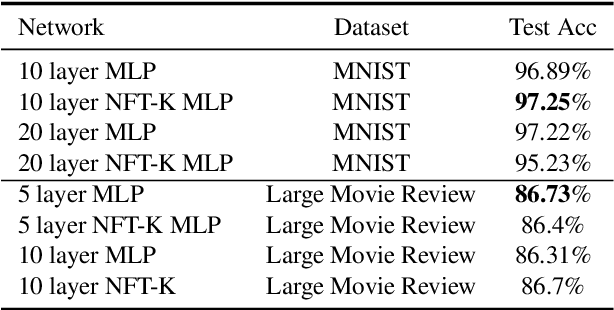
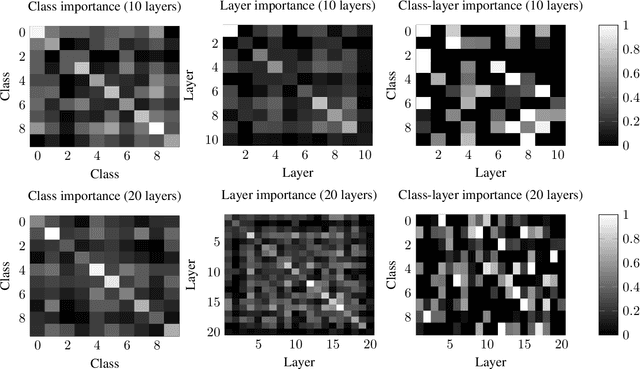
Deep neural networks have become essential for numerous applications due to their strong empirical performance such as vision, RL, and classification. Unfortunately, these networks are quite difficult to interpret, and this limits their applicability in settings where interpretability is important for safety, such as medical imaging. One type of deep neural network is neural tangent kernel that is similar to a kernel machine that provides some aspect of interpretability. To further contribute interpretability with respect to classification and the layers, we develop a new network as a combination of multiple neural tangent kernels, one to model each layer of the deep neural network individually as opposed to past work which attempts to represent the entire network via a single neural tangent kernel. We demonstrate the interpretability of this model on two datasets, showing that the multiple kernels model elucidates the interplay between the layers and predictions.