 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Reference Need Assessment System for Wikipedia
Mar 17, 2026Wikipedia is a critical source of information for millions of users across the Web. It serves as a key resource for large language models, search engines, question-answering systems, and other Web-based applications. In Wikipedia, content needs to be verifiable, meaning that readers can check that claims are backed by references to reliable sources. This depends on manual verification by editors, an effective but labor-intensive process, especially given the high volume of daily edits. To address this challenge, we introduce a multilingual machine learning system to assist editors in identifying claims requiring citations. Our approach is tested in 10 language editions of Wikipedia, outperforming existing benchmarks for reference need assessment. We not only consider machine learning evaluation metrics but also system requirements, allowing us to explore the trade-offs between model accuracy and computational efficiency under real-world infrastructure constraints. We deploy our system in production and release data and code to support further research.
* Accepted for publication at the Proceedings of the ACM Web Conference 2026 (WWW '26). Author's copy
Hidden Persuasion: Detecting Manipulative Narratives on Social Media During the 2022 Russian Invasion of Ukraine
May 29, 2025This paper presents one of the top-performing solutions to the UNLP 2025 Shared Task on Detecting Manipulation in Social Media. The task focuses on detecting and classifying rhetorical and stylistic manipulation techniques used to influence Ukrainian Telegram users. For the classification subtask, we fine-tuned the Gemma 2 language model with LoRA adapters and applied a second-level classifier leveraging meta-features and threshold optimization. For span detection, we employed an XLM-RoBERTa model trained for multi-target, including token binary classification. Our approach achieved 2nd place in classification and 3rd place in span detection.
Graph-Linguistic Fusion: Using Language Models for Wikidata Vandalism Detection
May 23, 2025
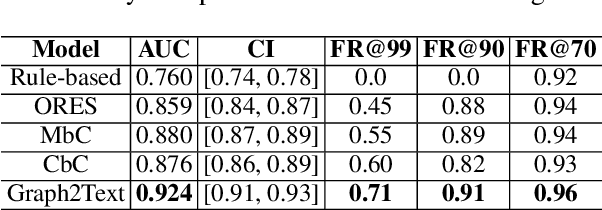

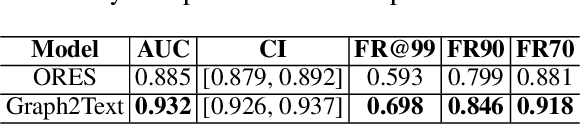
We introduce a next-generation vandalism detection system for Wikidata, one of the largest open-source structured knowledge bases on the Web. Wikidata is highly complex: its items incorporate an ever-expanding universe of factual triples and multilingual texts. While edits can alter both structured and textual content, our approach converts all edits into a single space using a method we call Graph2Text. This allows for evaluating all content changes for potential vandalism using a single multilingual language model. This unified approach improves coverage and simplifies maintenance. Experiments demonstrate that our solution outperforms the current production system. Additionally, we are releasing the code under an open license along with a large dataset of various human-generated knowledge alterations, enabling further research.
Characterizing Knowledge Manipulation in a Russian Wikipedia Fork
Apr 14, 2025Wikipedia is powered by MediaWiki, a free and open-source software that is also the infrastructure for many other wiki-based online encyclopedias. These include the recently launched website Ruwiki, which has copied and modified the original Russian Wikipedia content to conform to Russian law. To identify practices and narratives that could be associated with different forms of knowledge manipulation, this article presents an in-depth analysis of this Russian Wikipedia fork. We propose a methodology to characterize the main changes with respect to the original version. The foundation of this study is a comprehensive comparative analysis of more than 1.9M articles from Russian Wikipedia and its fork. Using meta-information and geographical, temporal, categorical, and textual features, we explore the changes made by Ruwiki editors. Furthermore, we present a classification of the main topics of knowledge manipulation in this fork, including a numerical estimation of their scope. This research not only sheds light on significant changes within Ruwiki, but also provides a methodology that could be applied to analyze other Wikipedia forks and similar collaborative projects.
An Open Multilingual System for Scoring Readability of Wikipedia
Jun 03, 2024



With over 60M articles, Wikipedia has become the largest platform for open and freely accessible knowledge. While it has more than 15B monthly visits, its content is believed to be inaccessible to many readers due to the lack of readability of its text. However, previous investigations of the readability of Wikipedia have been restricted to English only, and there are currently no systems supporting the automatic readability assessment of the 300+ languages in Wikipedia. To bridge this gap, we develop a multilingual model to score the readability of Wikipedia articles. To train and evaluate this model, we create a novel multilingual dataset spanning 14 languages, by matching articles from Wikipedia to simplified Wikipedia and online children encyclopedias. We show that our model performs well in a zero-shot scenario, yielding a ranking accuracy of more than 80% across 14 languages and improving upon previous benchmarks. These results demonstrate the applicability of the model at scale for languages in which there is no ground-truth data available for model fine-tuning. Furthermore, we provide the first overview on the state of readability in Wikipedia beyond English.
Fair multilingual vandalism detection system for Wikipedia
Jun 02, 2023



This paper presents a novel design of the system aimed at supporting the Wikipedia community in addressing vandalism on the platform. To achieve this, we collected a massive dataset of 47 languages, and applied advanced filtering and feature engineering techniques, including multilingual masked language modeling to build the training dataset from human-generated data. The performance of the system was evaluated through comparison with the one used in production in Wikipedia, known as ORES. Our research results in a significant increase in the number of languages covered, making Wikipedia patrolling more efficient to a wider range of communities. Furthermore, our model outperforms ORES, ensuring that the results provided are not only more accurate but also less biased against certain groups of contributors.