 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRPrompt: Bootstrapping Query-Aware Prompt Optimization from Textual Rewards
Jul 24, 2025Prompt optimization improves the reasoning abilities of large language models (LLMs) without requiring parameter updates to the target model. Following heuristic-based "Think step by step" approaches, the field has evolved in two main directions: while one group of methods uses textual feedback to elicit improved prompts from general-purpose LLMs in a training-free way, a concurrent line of research relies on numerical rewards to train a special prompt model, tailored for providing optimal prompts to the target model. In this paper, we introduce the Textual Reward Prompt framework (TRPrompt), which unifies these approaches by directly incorporating textual feedback into training of the prompt model. Our framework does not require prior dataset collection and is being iteratively improved with the feedback on the generated prompts. When coupled with the capacity of an LLM to internalize the notion of what a "good" prompt is, the high-resolution signal provided by the textual rewards allows us to train a prompt model yielding state-of-the-art query-specific prompts for the problems from the challenging math datasets GSMHard and MATH.
Generating Structured Outputs from Language Models: Benchmark and Studies
Jan 18, 2025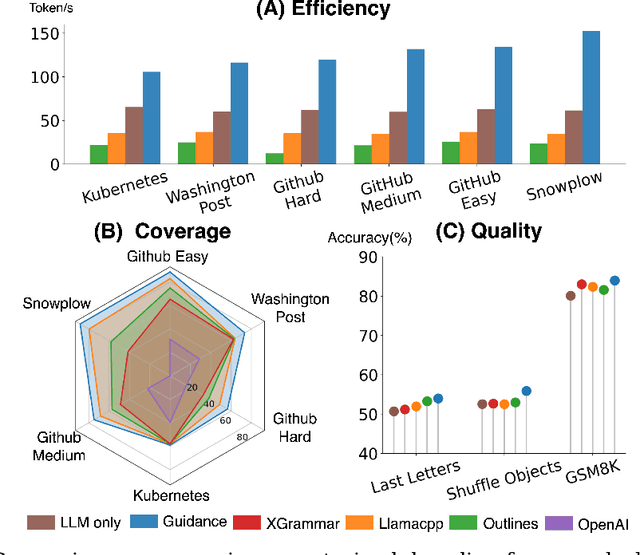
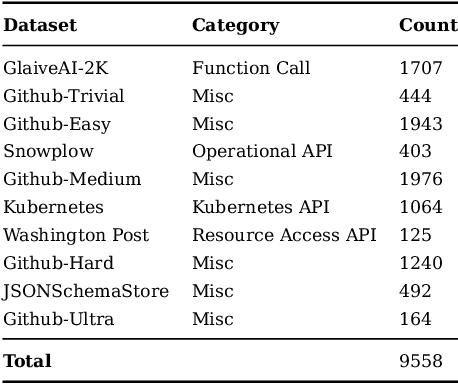
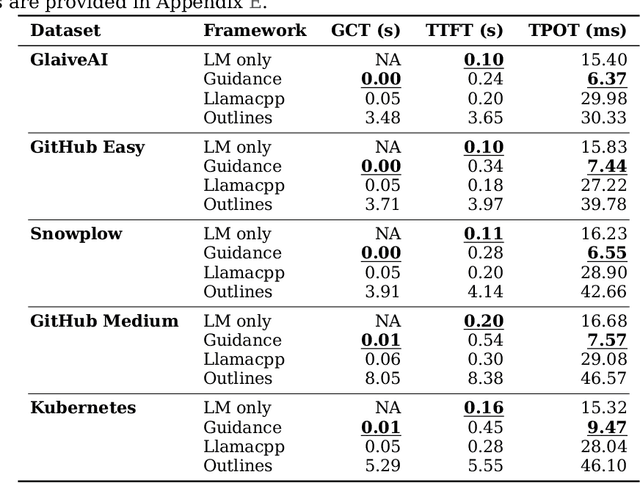
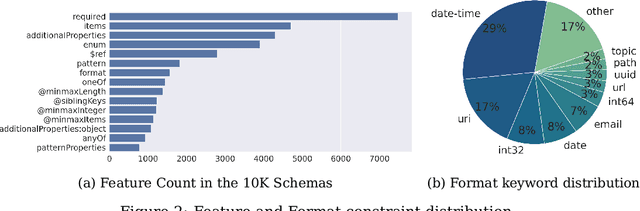
Reliably generating structured outputs has become a critical capability for modern language model (LM) applications. Constrained decoding has emerged as the dominant technology across sectors for enforcing structured outputs during generation. Despite its growing adoption, little has been done with the systematic evaluation of the behaviors and performance of constrained decoding. Constrained decoding frameworks have standardized around JSON Schema as a structured data format, with most uses guaranteeing constraint compliance given a schema. However, there is poor understanding of the effectiveness of the methods in practice. We present an evaluation framework to assess constrained decoding approaches across three critical dimensions: efficiency in generating constraint-compliant outputs, coverage of diverse constraint types, and quality of the generated outputs. To facilitate this evaluation, we introduce JSONSchemaBench, a benchmark for constrained decoding comprising 10K real-world JSON schemas that encompass a wide range of constraints with varying complexity. We pair the benchmark with the existing official JSON Schema Test Suite and evaluate six state-of-the-art constrained decoding frameworks, including Guidance, Outlines, Llamacpp, XGrammar, OpenAI, and Gemini. Through extensive experiments, we gain insights into the capabilities and limitations of constrained decoding on structured generation with real-world JSON schemas. Our work provides actionable insights for improving constrained decoding frameworks and structured generation tasks, setting a new standard for evaluating constrained decoding and structured generation. We release JSONSchemaBench at https://github.com/guidance-ai/jsonschemabench
Byte BPE Tokenization as an Inverse string Homomorphism
Dec 04, 2024



Tokenization is an important preprocessing step in the training and inference of large language models (LLMs). While there has been extensive research on the expressive power of the neural achitectures used in LLMs, the impact of tokenization has not been well understood. In this work, we demonstrate that tokenization, irrespective of the algorithm used, acts as an inverse homomorphism between strings and tokens. This suggests that the character space of the source language and the token space of the tokenized language are homomorphic, preserving the structural properties of the source language. Additionally, we explore the concept of proper tokenization, which refers to an unambiguous tokenization returned from the tokenizer. Our analysis reveals that the expressiveness of neural architectures in recognizing context-free languages is not affected by tokenization.
Sketch-Guided Constrained Decoding for Boosting Blackbox Large Language Models without Logit Access
Jan 18, 2024



Constrained decoding, a technique for enforcing constraints on language model outputs, offers a way to control text generation without retraining or architectural modifications. Its application is, however, typically restricted to models that give users access to next-token distributions (usually via softmax logits), which poses a limitation with blackbox large language models (LLMs). This paper introduces sketch-guided constrained decoding (SGCD), a novel approach to constrained decoding for blackbox LLMs, which operates without access to the logits of the blackbox LLM. SGCD utilizes a locally hosted auxiliary model to refine the output of an unconstrained blackbox LLM, effectively treating this initial output as a "sketch" for further elaboration. This approach is complementary to traditional logit-based techniques and enables the application of constrained decoding in settings where full model transparency is unavailable. We demonstrate the efficacy of SGCD through experiments in closed information extraction and constituency parsing, showing how it enhances the utility and flexibility of blackbox LLMs for complex NLP tasks.
Flows: Building Blocks of Reasoning and Collaborating AI
Aug 02, 2023



Recent advances in artificial intelligence (AI) have produced highly capable and controllable systems. This creates unprecedented opportunities for structured reasoning as well as collaboration among multiple AI systems and humans. To fully realize this potential, it is essential to develop a principled way of designing and studying such structured interactions. For this purpose, we introduce the conceptual framework of Flows: a systematic approach to modeling complex interactions. Flows are self-contained building blocks of computation, with an isolated state, communicating through a standardized message-based interface. This modular design allows Flows to be recursively composed into arbitrarily nested interactions, with a substantial reduction of complexity. Crucially, any interaction can be implemented using this framework, including prior work on AI--AI and human--AI interactions, prompt engineering schemes, and tool augmentation. We demonstrate the potential of Flows on the task of competitive coding, a challenging task on which even GPT-4 struggles. Our results suggest that structured reasoning and collaboration substantially improve generalization, with AI-only Flows adding +$21$ and human--AI Flows adding +$54$ absolute points in terms of solve rate. To support rapid and rigorous research, we introduce the aiFlows library. The library comes with a repository of Flows that can be easily used, extended, and composed into novel, more complex Flows. The aiFlows library is available at https://github.com/epfl-dlab/aiflows. Data and Flows for reproducing our experiments are available at https://github.com/epfl-dlab/cc_flows.
Flexible Grammar-Based Constrained Decoding for Language Models
May 24, 2023



LLMs have shown impressive few-shot performance across many tasks. However, they still struggle when it comes to reliably generating complex output structures, such as those required for information extraction. This limitation stems from the fact that LLMs, without fine-tuning, tend to generate free text rather than structures precisely following a specific grammar. In this work, we propose to enrich the decoding with formal grammar constraints. More concretely, given Context-Free Grammar(CFG), our framework ensures that the token generated in each decoding step would lead to a valid continuation compliant with the grammar production rules. This process guarantees the generation of valid sequences. Importantly, our framework can be readily combined with any CFG or decoding algorithm. We demonstrate that the outputs of many NLP tasks can be represented as formal languages, making them suitable for direct use in our framework. We conducted experiments with two challenging tasks involving large alphabets in their grammar (Wikidata entities and relations): information extraction and entity disambiguation. Our results with LLaMA models indicate that grammar-constrained decoding substantially outperforms unconstrained decoding and even competes with task-specific fine-tuned models. These findings suggest that integrating grammar-based constraints during decoding holds great promise in making LLMs reliably produce structured outputs, especially in setting where training data is scarce and fine-tuning is expensive.
Legal Transformer Models May Not Always Help
Sep 15, 2021
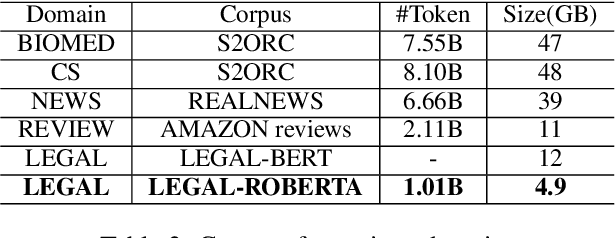


Deep learning-based Natural Language Processing methods, especially transformers, have achieved impressive performance in the last few years. Applying those state-of-the-art NLP methods to legal activities to automate or simplify some simple work is of great value. This work investigates the value of domain adaptive pre-training and language adapters in legal NLP tasks. By comparing the performance of language models with domain adaptive pre-training on different tasks and different dataset splits, we show that domain adaptive pre-training is only helpful with low-resource downstream tasks, thus far from being a panacea. We also benchmark the performance of adapters in a typical legal NLP task and show that they can yield similar performance to full model tuning with much smaller training costs. As an additional result, we release LegalRoBERTa, a RoBERTa model further pre-trained on legal corpora.
An Enhanced MeanSum Method For Generating Hotel Multi-Review Summarizations
Dec 07, 2020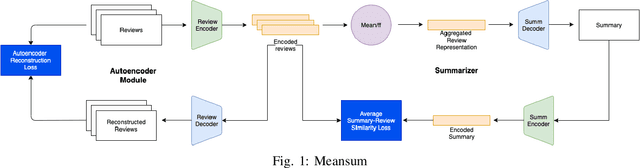


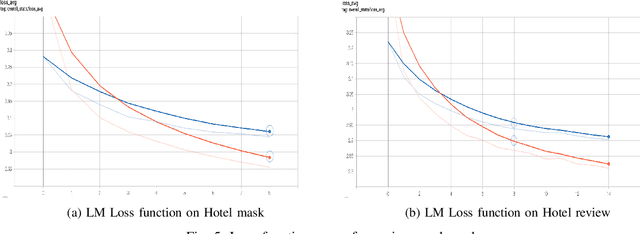
Multi-document summaritazion is the process of taking multiple texts as input and producing a short summary text based on the content of input texts. Up until recently, multi-document summarizers are mostly supervised extractive. However, supervised methods require datasets of large, paired document-summary examples which are rare and expensive to produce. In 2018, an unsupervised multi-document abstractive summarization method(Meansum) was proposed by Chu and Liu, and demonstrated competitive performances comparing to extractive methods. Despite good evaluation results on automatic metrics, Meansum has multiple limitations, notably the inability of dealing with multiple aspects. The aim of this work was to use Multi-Aspect Masker(MAM) as content selector to address the issue with multi-aspect. Moreover, we propose a regularizer to control the length of the generated summaries. Through a series of experiments on the hotel dataset from Trip Advisor, we validate our assumption and show that our improved model achieves higher ROUGE, Sentiment Accuracy than the original Meansum method and also beats/ comprarable/close to the supervised baseline.