 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Cross-Validated Targeted Maximum Likelihood Estimation
Sep 18, 2024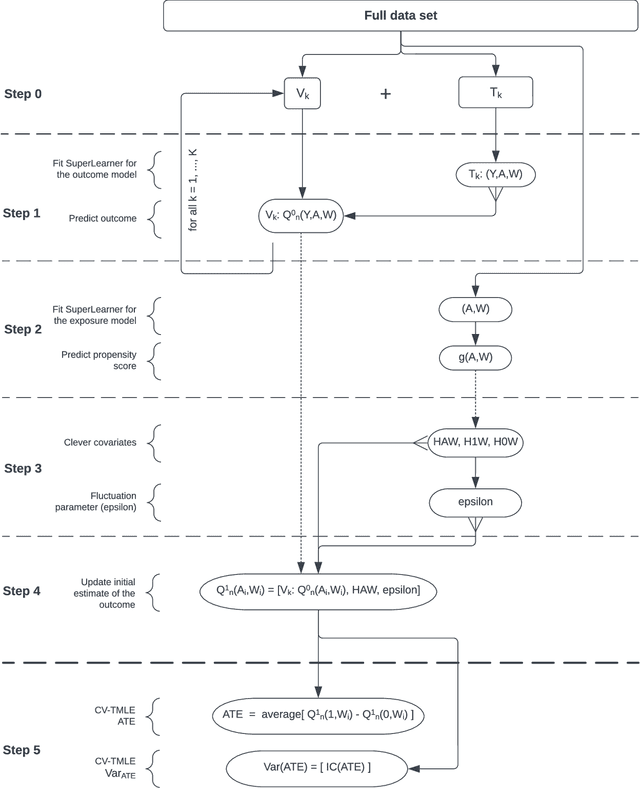
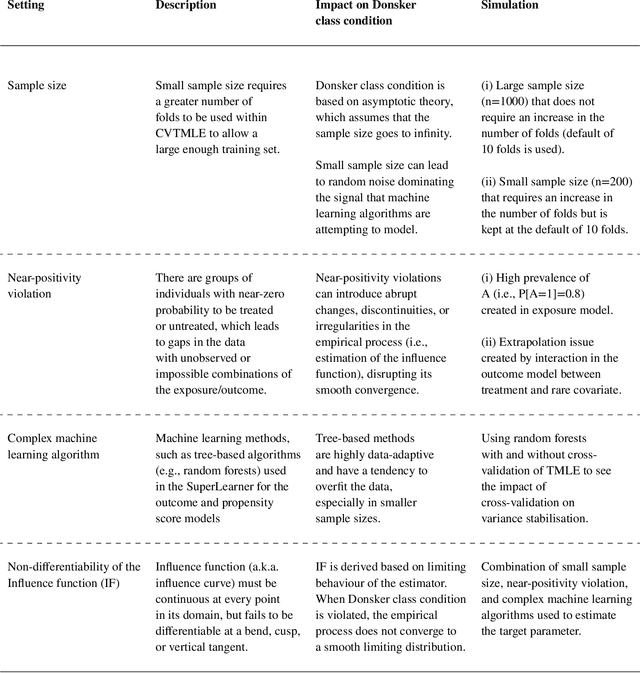
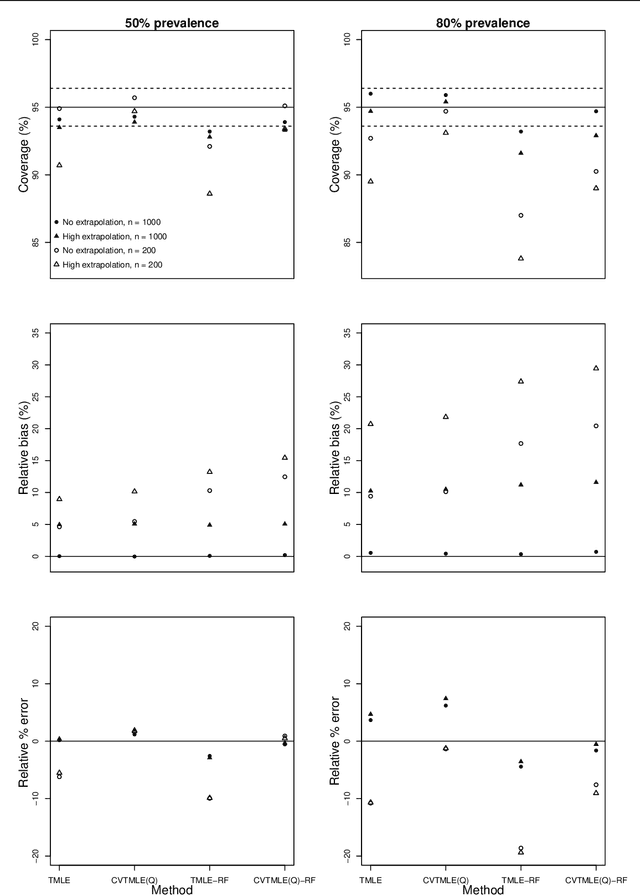
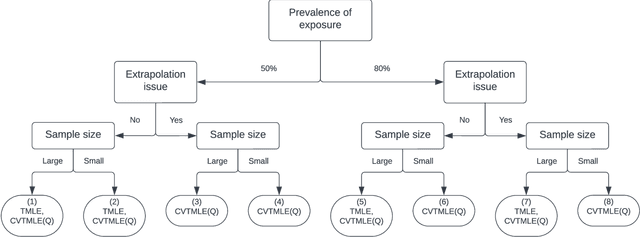
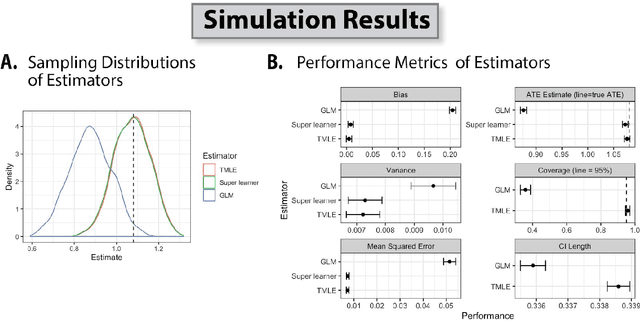
Background: Advanced methods for causal inference, such as targeted maximum likelihood estimation (TMLE), require certain conditions for statistical inference. However, in situations where there is not differentiability due to data sparsity or near-positivity violations, the Donsker class condition is violated. In such situations, TMLE variance can suffer from inflation of the type I error and poor coverage, leading to conservative confidence intervals. Cross-validation of the TMLE algorithm (CVTMLE) has been suggested to improve on performance compared to TMLE in settings of positivity or Donsker class violations. We aim to investigate the performance of CVTMLE compared to TMLE in various settings. Methods: We utilised the data-generating mechanism as described in Leger et al. (2022) to run a Monte Carlo experiment under different Donsker class violations. Then, we evaluated the respective statistical performances of TMLE and CVTMLE with different super learner libraries, with and without regression tree methods. Results: We found that CVTMLE vastly improves confidence interval coverage without adversely affecting bias, particularly in settings with small sample sizes and near-positivity violations. Furthermore, incorporating regression trees using standard TMLE with ensemble super learner-based initial estimates increases bias and variance leading to invalid statistical inference. Conclusions: It has been shown that when using CVTMLE the Donsker class condition is no longer necessary to obtain valid statistical inference when using regression trees and under either data sparsity or near-positivity violations. We show through simulations that CVTMLE is much less sensitive to the choice of the super learner library and thereby provides better estimation and inference in cases where the super learner library uses more flexible candidates and is prone to overfitting.
Large Language Models as Co-Pilots for Causal Inference in Medical Studies
Jul 26, 2024

The validity of medical studies based on real-world clinical data, such as observational studies, depends on critical assumptions necessary for drawing causal conclusions about medical interventions. Many published studies are flawed because they violate these assumptions and entail biases such as residual confounding, selection bias, and misalignment between treatment and measurement times. Although researchers are aware of these pitfalls, they continue to occur because anticipating and addressing them in the context of a specific study can be challenging without a large, often unwieldy, interdisciplinary team with extensive expertise. To address this expertise gap, we explore the use of large language models (LLMs) as co-pilot tools to assist researchers in identifying study design flaws that undermine the validity of causal inferences. We propose a conceptual framework for LLMs as causal co-pilots that encode domain knowledge across various fields, engaging with researchers in natural language interactions to provide contextualized assistance in study design. We provide illustrative examples of how LLMs can function as causal co-pilots, propose a structured framework for their grounding in existing causal inference frameworks, and highlight the unique challenges and opportunities in adapting LLMs for reliable use in epidemiological research.
Application of targeted maximum likelihood estimation in public health and epidemiological studies: a systematic review
Mar 13, 2023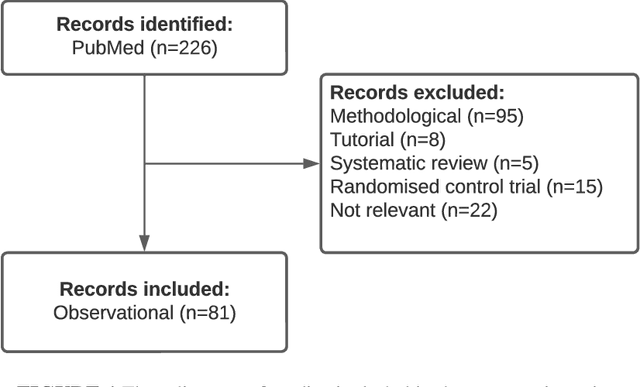
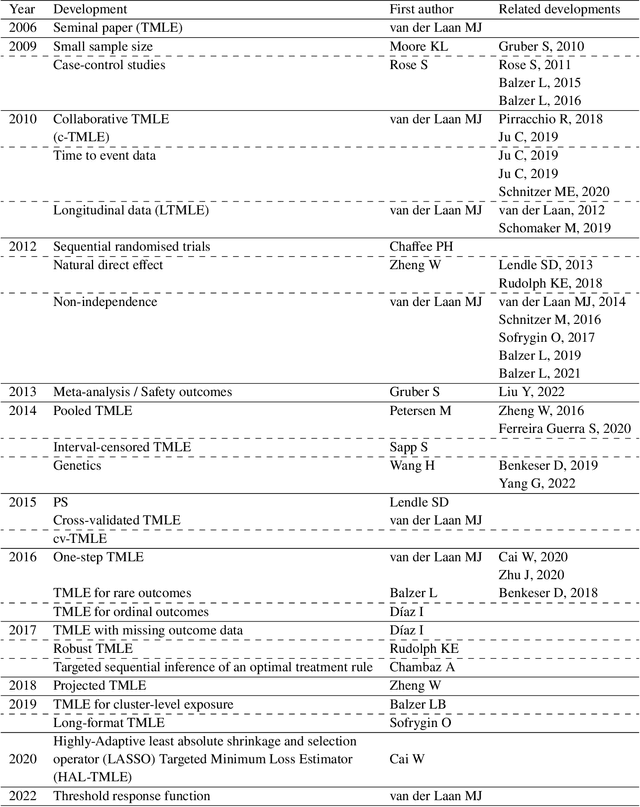
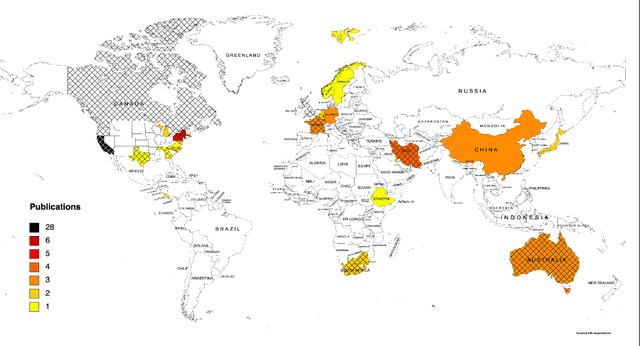
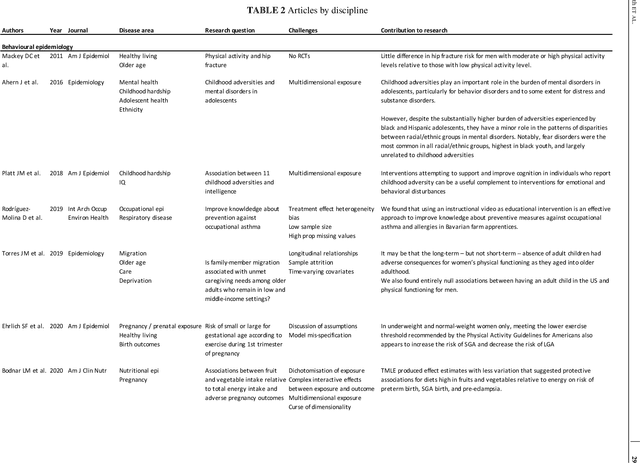
The Targeted Maximum Likelihood Estimation (TMLE) statistical data analysis framework integrates machine learning, statistical theory, and statistical inference to provide a least biased, efficient and robust strategy for estimation and inference of a variety of statistical and causal parameters. We describe and evaluate the epidemiological applications that have benefited from recent methodological developments. We conducted a systematic literature review in PubMed for articles that applied any form of TMLE in observational studies. We summarised the epidemiological discipline, geographical location, expertise of the authors, and TMLE methods over time. We used the Roadmap of Targeted Learning and Causal Inference to extract key methodological aspects of the publications. We showcase the contributions to the literature of these TMLE results. Of the 81 publications included, 25% originated from the University of California at Berkeley, where the framework was first developed by Professor Mark van der Laan. By the first half of 2022, 70% of the publications originated from outside the United States and explored up to 7 different epidemiological disciplines in 2021-22. Double-robustness, bias reduction and model misspecification were the main motivations that drew researchers towards the TMLE framework. Through time, a wide variety of methodological, tutorial and software-specific articles were cited, owing to the constant growth of methodological developments around TMLE. There is a clear dissemination trend of the TMLE framework to various epidemiological disciplines and to increasing numbers of geographical areas. The availability of R packages, publication of tutorial papers, and involvement of methodological experts in applied publications have contributed to an exponential increase in the number of studies that understood the benefits, and adoption, of TMLE.
Multi-task Highly Adaptive Lasso
Jan 27, 2023
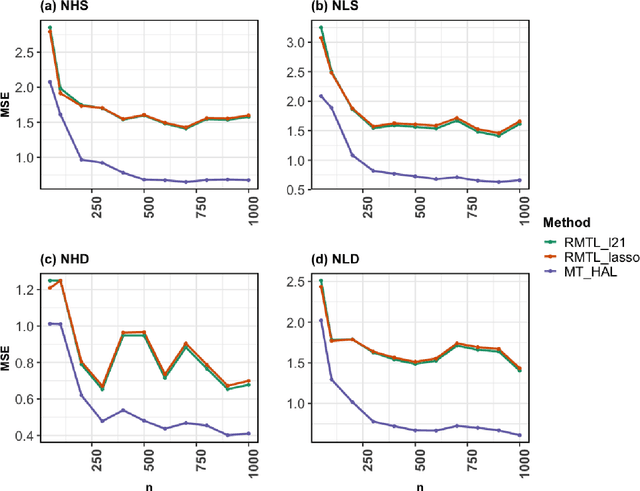


We propose a novel, fully nonparametric approach for the multi-task learning, the Multi-task Highly Adaptive Lasso (MT-HAL). MT-HAL simultaneously learns features, samples and task associations important for the common model, while imposing a shared sparse structure among similar tasks. Given multiple tasks, our approach automatically finds a sparse sharing structure. The proposed MTL algorithm attains a powerful dimension-free convergence rate of $o_p(n^{-1/4})$ or better. We show that MT-HAL outperforms sparsity-based MTL competitors across a wide range of simulation studies, including settings with nonlinear and linear relationships, varying levels of sparsity and task correlations, and different numbers of covariates and sample size.
Personalized Online Machine Learning
Sep 21, 2021
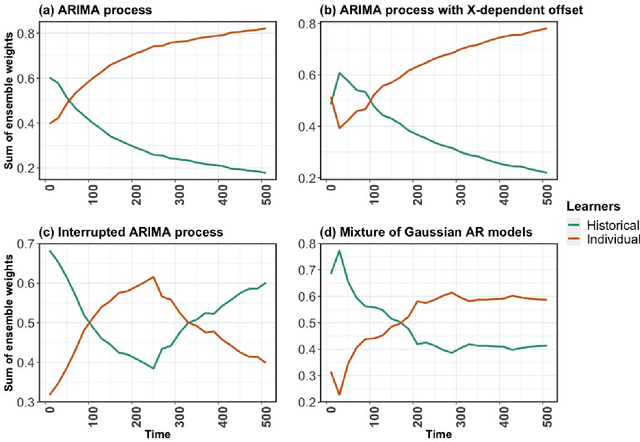
In this work, we introduce the Personalized Online Super Learner (POSL) -- an online ensembling algorithm for streaming data whose optimization procedure accommodates varying degrees of personalization. Namely, POSL optimizes predictions with respect to baseline covariates, so personalization can vary from completely individualized (i.e., optimization with respect to baseline covariate subject ID) to many individuals (i.e., optimization with respect to common baseline covariates). As an online algorithm, POSL learns in real-time. POSL can leverage a diversity of candidate algorithms, including online algorithms with different training and update times, fixed algorithms that are never updated during the procedure, pooled algorithms that learn from many individuals' time-series, and individualized algorithms that learn from within a single time-series. POSL's ensembling of this hybrid of base learning strategies depends on the amount of data collected, the stationarity of the time-series, and the mutual characteristics of a group of time-series. In essence, POSL decides whether to learn across samples, through time, or both, based on the underlying (unknown) structure in the data. For a wide range of simulations that reflect realistic forecasting scenarios, and in a medical data application, we examine the performance of POSL relative to other current ensembling and online learning methods. We show that POSL is able to provide reliable predictions for time-series data and adjust to changing data-generating environments. We further cultivate POSL's practicality by extending it to settings where time-series enter/exit dynamically over chronological time.
Targeting Learning: Robust Statistics for Reproducible Research
Jun 12, 2020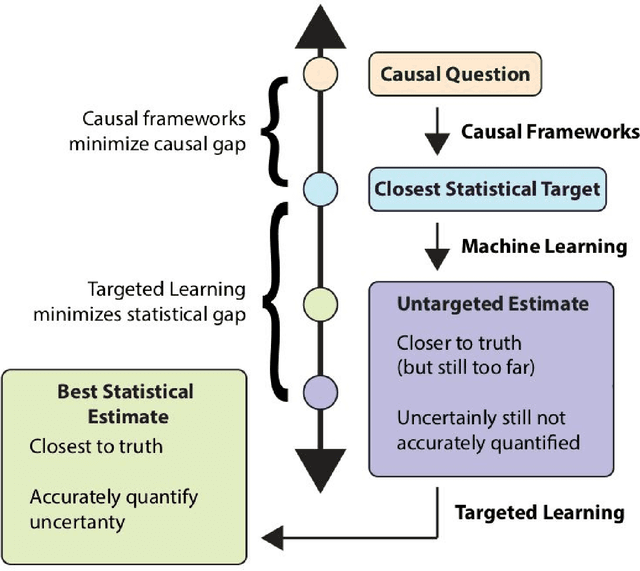
Targeted Learning is a subfield of statistics that unifies advances in causal inference, machine learning and statistical theory to help answer scientifically impactful questions with statistical confidence. Targeted Learning is driven by complex problems in data science and has been implemented in a diversity of real-world scenarios: observational studies with missing treatments and outcomes, personalized interventions, longitudinal settings with time-varying treatment regimes, survival analysis, adaptive randomized trials, mediation analysis, and networks of connected subjects. In contrast to the (mis)application of restrictive modeling strategies that dominate the current practice of statistics, Targeted Learning establishes a principled standard for statistical estimation and inference (i.e., confidence intervals and p-values). This multiply robust approach is accompanied by a guiding roadmap and a burgeoning software ecosystem, both of which provide guidance on the construction of estimators optimized to best answer the motivating question. The roadmap of Targeted Learning emphasizes tailoring statistical procedures so as to minimize their assumptions, carefully grounding them only in the scientific knowledge available. The end result is a framework that honestly reflects the uncertainty in both the background knowledge and the available data in order to draw reliable conclusions from statistical analyses - ultimately enhancing the reproducibility and rigor of scientific findings.