 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Cross-Validated Targeted Maximum Likelihood Estimation
Sep 18, 2024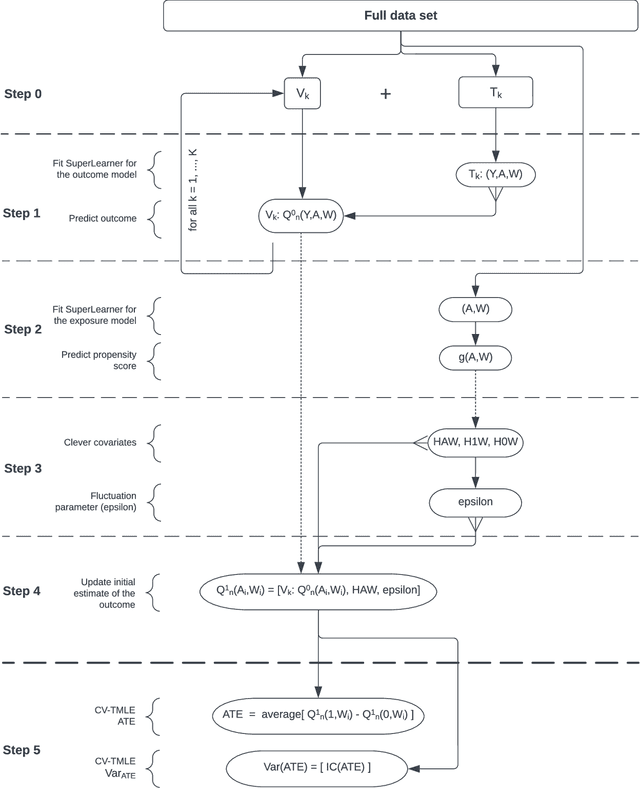
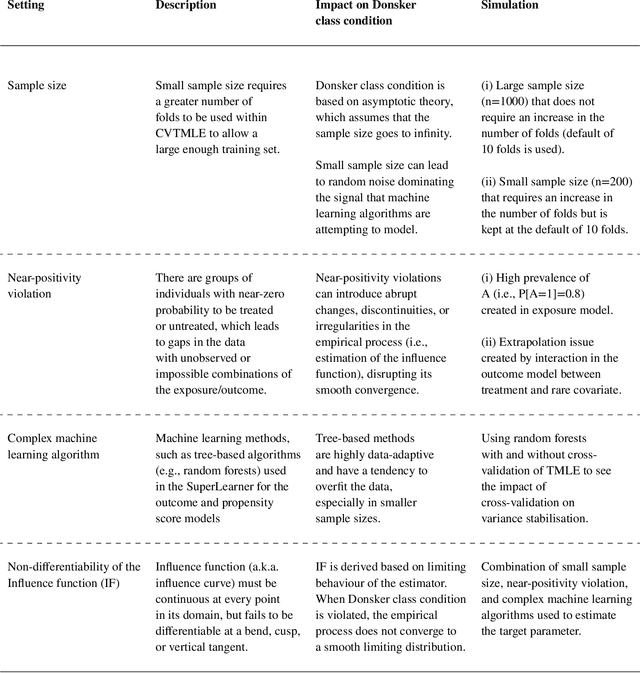
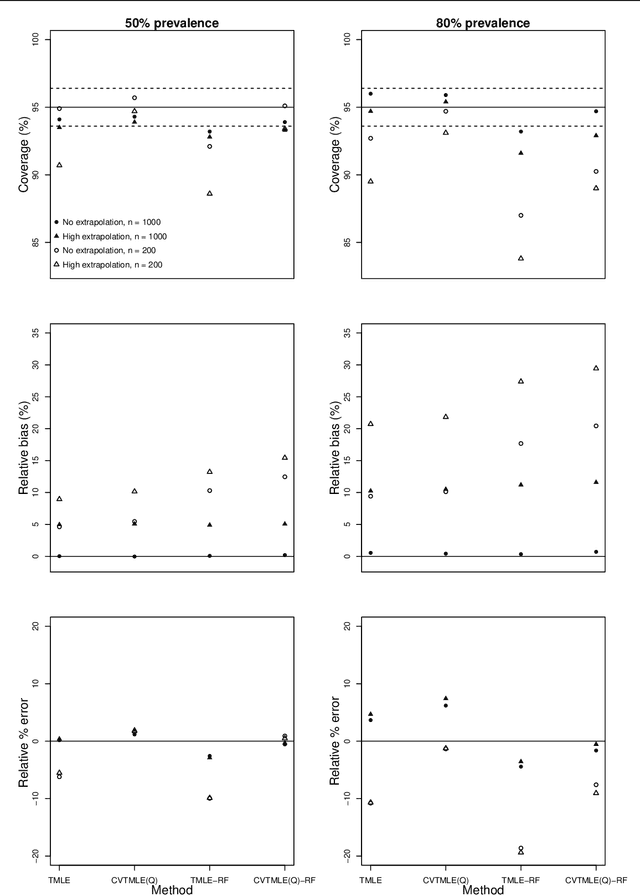
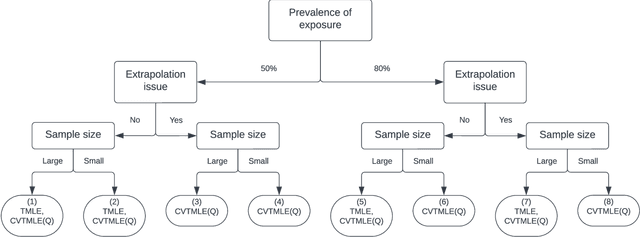
Background: Advanced methods for causal inference, such as targeted maximum likelihood estimation (TMLE), require certain conditions for statistical inference. However, in situations where there is not differentiability due to data sparsity or near-positivity violations, the Donsker class condition is violated. In such situations, TMLE variance can suffer from inflation of the type I error and poor coverage, leading to conservative confidence intervals. Cross-validation of the TMLE algorithm (CVTMLE) has been suggested to improve on performance compared to TMLE in settings of positivity or Donsker class violations. We aim to investigate the performance of CVTMLE compared to TMLE in various settings. Methods: We utilised the data-generating mechanism as described in Leger et al. (2022) to run a Monte Carlo experiment under different Donsker class violations. Then, we evaluated the respective statistical performances of TMLE and CVTMLE with different super learner libraries, with and without regression tree methods. Results: We found that CVTMLE vastly improves confidence interval coverage without adversely affecting bias, particularly in settings with small sample sizes and near-positivity violations. Furthermore, incorporating regression trees using standard TMLE with ensemble super learner-based initial estimates increases bias and variance leading to invalid statistical inference. Conclusions: It has been shown that when using CVTMLE the Donsker class condition is no longer necessary to obtain valid statistical inference when using regression trees and under either data sparsity or near-positivity violations. We show through simulations that CVTMLE is much less sensitive to the choice of the super learner library and thereby provides better estimation and inference in cases where the super learner library uses more flexible candidates and is prone to overfitting.
Application of targeted maximum likelihood estimation in public health and epidemiological studies: a systematic review
Mar 13, 2023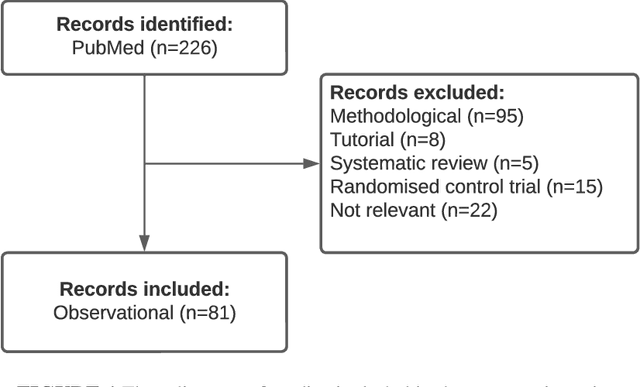
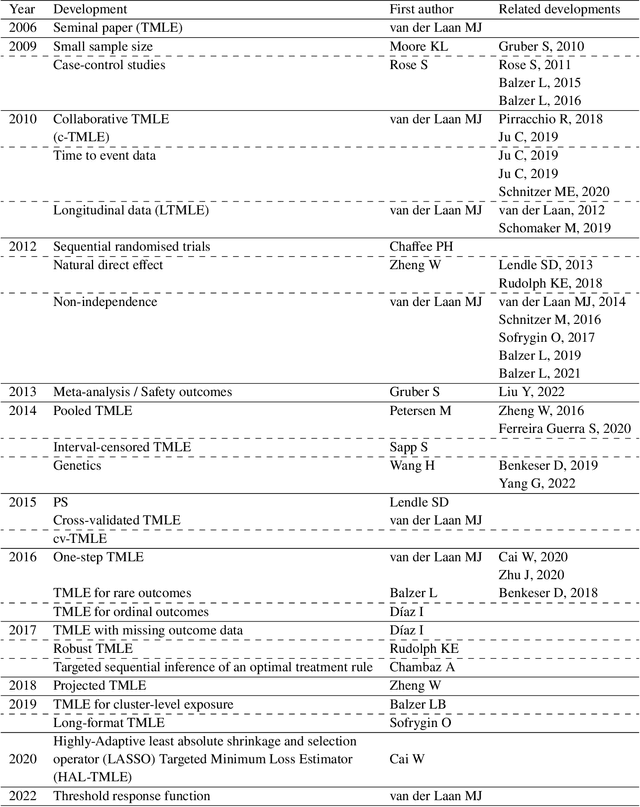
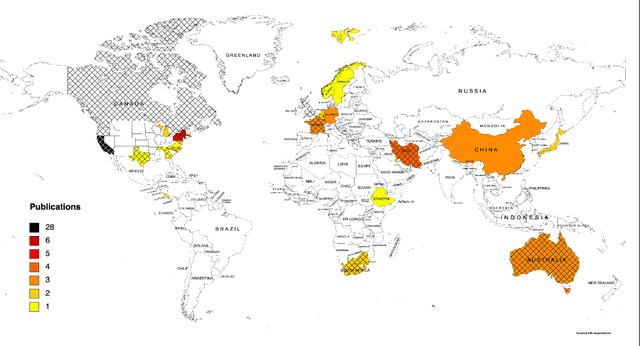
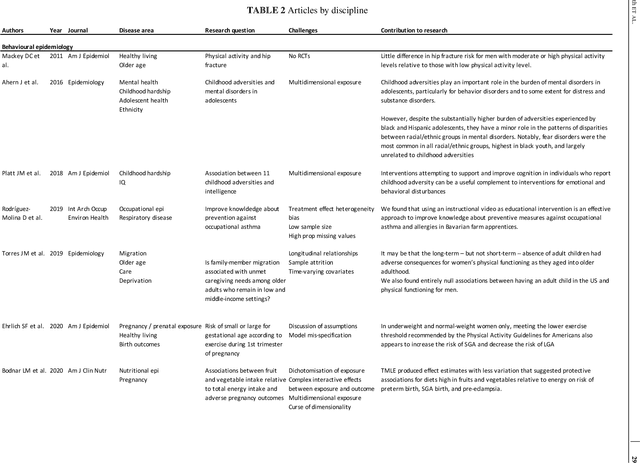
The Targeted Maximum Likelihood Estimation (TMLE) statistical data analysis framework integrates machine learning, statistical theory, and statistical inference to provide a least biased, efficient and robust strategy for estimation and inference of a variety of statistical and causal parameters. We describe and evaluate the epidemiological applications that have benefited from recent methodological developments. We conducted a systematic literature review in PubMed for articles that applied any form of TMLE in observational studies. We summarised the epidemiological discipline, geographical location, expertise of the authors, and TMLE methods over time. We used the Roadmap of Targeted Learning and Causal Inference to extract key methodological aspects of the publications. We showcase the contributions to the literature of these TMLE results. Of the 81 publications included, 25% originated from the University of California at Berkeley, where the framework was first developed by Professor Mark van der Laan. By the first half of 2022, 70% of the publications originated from outside the United States and explored up to 7 different epidemiological disciplines in 2021-22. Double-robustness, bias reduction and model misspecification were the main motivations that drew researchers towards the TMLE framework. Through time, a wide variety of methodological, tutorial and software-specific articles were cited, owing to the constant growth of methodological developments around TMLE. There is a clear dissemination trend of the TMLE framework to various epidemiological disciplines and to increasing numbers of geographical areas. The availability of R packages, publication of tutorial papers, and involvement of methodological experts in applied publications have contributed to an exponential increase in the number of studies that understood the benefits, and adoption, of TMLE.