 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWAY: A Counterfactual Computational Linguistic Approach to Measuring and Mitigating Sycophancy
Apr 02, 2026Large language models exhibit sycophancy: the tendency to shift outputs toward user-expressed stances, regardless of correctness or consistency. While prior work has studied this issue and its impacts, rigorous computational linguistic metrics are needed to identify when models are being sycophantic. Here, we introduce SWAY, an unsupervised computational linguistic measure of sycophancy. We develop a counterfactual prompting mechanism to identify how much a model's agreement shifts under positive versus negative linguistic pressure, isolating framing effects from content. Applying this metric to benchmark 6 models, we find that sycophancy increases with epistemic commitment. Leveraging our metric, we introduce a counterfactual mitigation strategy teaching models to consider what the answer would be if opposite assumptions were suggested. While baseline mitigation instructing to be explicitly anti-sycophantic yields moderate reductions, and can backfire, our counterfactual CoT mitigation drives sycophancy to near zero across models, commitment levels, and clause types, while not suppressing responsiveness to genuine evidence. Overall, we contribute a metric for benchmarking sycophancy and a mitigation informed by it.
Multi-Perspective LLM Annotations for Valid Analyses in Subjective Tasks
Mar 22, 2026Large language models are increasingly used to annotate texts, but their outputs reflect some human perspectives better than others. Existing methods for correcting LLM annotation error assume a single ground truth. However, this assumption fails in subjective tasks where disagreement across demographic groups is meaningful. Here we introduce Perspective-Driven Inference, a method that treats the distribution of annotations across groups as the quantity of interest, and estimates it using a small human annotation budget. We contribute an adaptive sampling strategy that concentrates human annotation effort on groups where LLM proxies are least accurate. We evaluate on politeness and offensiveness rating tasks, showing targeted improvements for harder-to-model demographic groups relative to uniform sampling baselines, while maintaining coverage.
Can Unconfident LLM Annotations Be Used for Confident Conclusions?
Aug 27, 2024Large language models (LLMs) have shown high agreement with human raters across a variety of tasks, demonstrating potential to ease the challenges of human data collection. In computational social science (CSS), researchers are increasingly leveraging LLM annotations to complement slow and expensive human annotations. Still, guidelines for collecting and using LLM annotations, without compromising the validity of downstream conclusions, remain limited. We introduce Confidence-Driven Inference: a method that combines LLM annotations and LLM confidence indicators to strategically select which human annotations should be collected, with the goal of producing accurate statistical estimates and provably valid confidence intervals while reducing the number of human annotations needed. Our approach comes with safeguards against LLM annotations of poor quality, guaranteeing that the conclusions will be both valid and no less accurate than if we only relied on human annotations. We demonstrate the effectiveness of Confidence-Driven Inference over baselines in statistical estimation tasks across three CSS settings--text politeness, stance, and bias--reducing the needed number of human annotations by over 25% in each. Although we use CSS settings for demonstration, Confidence-Driven Inference can be used to estimate most standard quantities across a broad range of NLP problems.
Grounding or Guesswork? Large Language Models are Presumptive Grounders
Nov 15, 2023Effective conversation requires common ground: a shared understanding between the participants. Common ground, however, does not emerge spontaneously in conversation. Speakers and listeners work together to both identify and construct a shared basis while avoiding misunderstanding. To accomplish grounding, humans rely on a range of dialogue acts, like clarification (What do you mean?) and acknowledgment (I understand.). In domains like teaching and emotional support, carefully constructing grounding prevents misunderstanding. However, it is unclear whether large language models (LLMs) leverage these dialogue acts in constructing common ground. To this end, we curate a set of grounding acts and propose corresponding metrics that quantify attempted grounding. We study whether LLMs use these grounding acts, simulating them taking turns from several dialogue datasets, and comparing the results to humans. We find that current LLMs are presumptive grounders, biased towards assuming common ground without using grounding acts. To understand the roots of this behavior, we examine the role of instruction tuning and reinforcement learning with human feedback (RLHF), finding that RLHF leads to less grounding. Altogether, our work highlights the need for more research investigating grounding in human-AI interaction.
Othering and low prestige framing of immigrant cuisines in US restaurant reviews and large language models
Jul 14, 2023
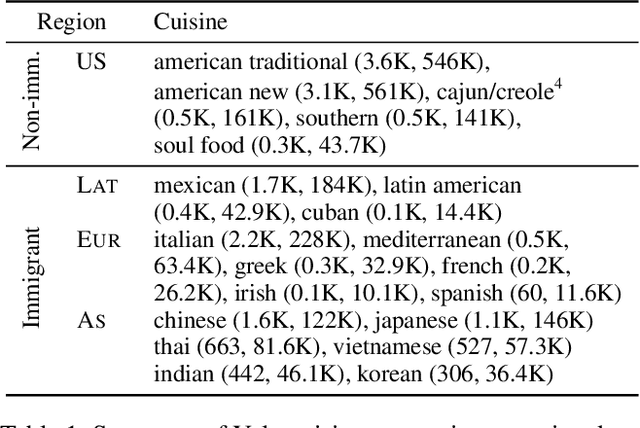
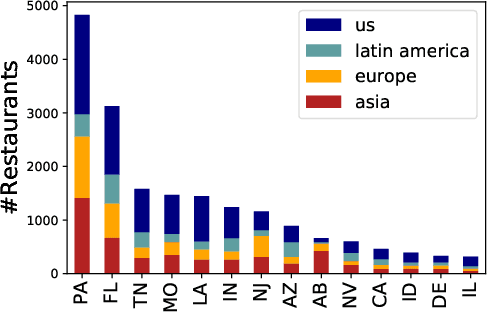
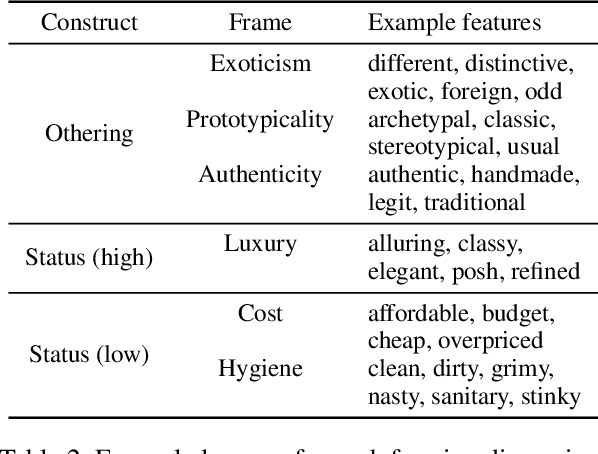
Identifying and understanding implicit attitudes toward food can help efforts to mitigate social prejudice due to food's pervasive role as a marker of cultural and ethnic identity. Stereotypes about food are a form of microaggression that contribute to harmful public discourse that may in turn perpetuate prejudice toward ethnic groups and negatively impact economic outcomes for restaurants. Through careful linguistic analyses, we evaluate social theories about attitudes toward immigrant cuisine in a large-scale study of framing differences in 2.1M English language Yelp reviews of restaurants in 14 US states. Controlling for factors such as restaurant price and neighborhood racial diversity, we find that immigrant cuisines are more likely to be framed in objectifying and othering terms of authenticity (e.g., authentic, traditional), exoticism (e.g., exotic, different), and prototypicality (e.g., typical, usual), but that non-Western immigrant cuisines (e.g., Indian, Mexican) receive more othering than European cuisines (e.g., French, Italian). We further find that non-Western immigrant cuisines are framed less positively and as lower status, being evaluated in terms of affordability and hygiene. Finally, we show that reviews generated by large language models (LLMs) reproduce many of the same framing tendencies. Our results empirically corroborate social theories of taste and gastronomic stereotyping, and reveal linguistic processes by which such attitudes are reified.
Laughing Heads: Can Transformers Detect What Makes a Sentence Funny?
May 19, 2021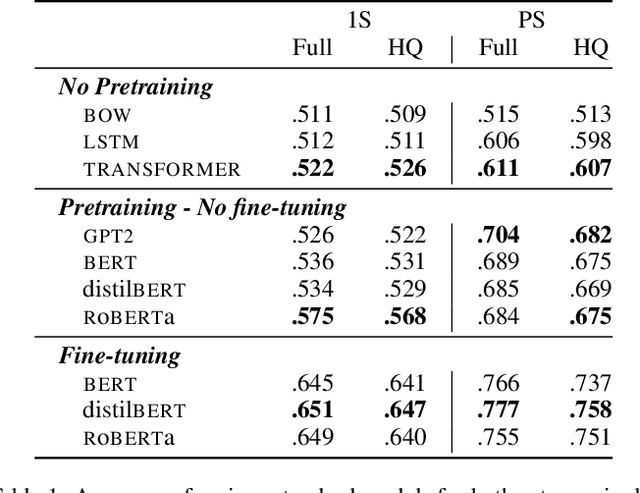
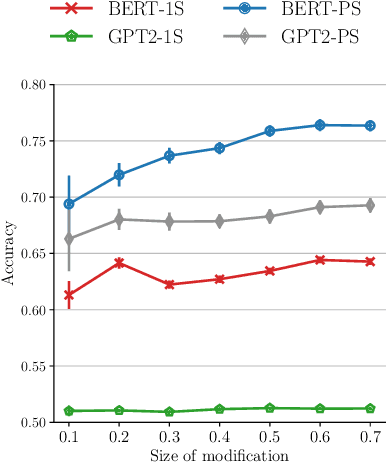
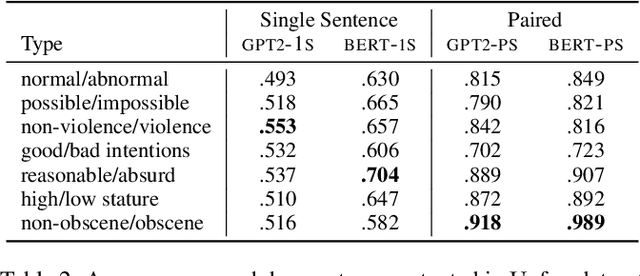
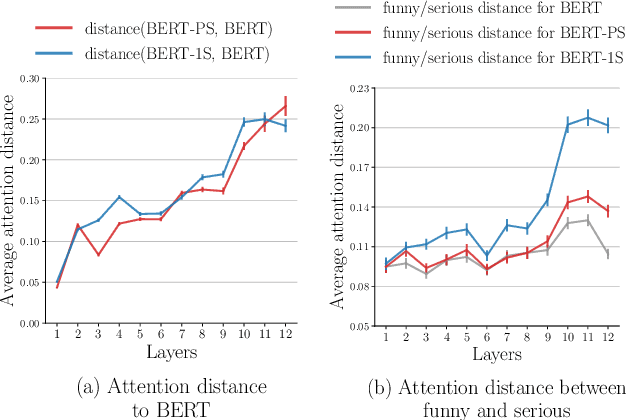
The automatic detection of humor poses a grand challenge for natural language processing. Transformer-based systems have recently achieved remarkable results on this task, but they usually (1)~were evaluated in setups where serious vs humorous texts came from entirely different sources, and (2)~focused on benchmarking performance without providing insights into how the models work. We make progress in both respects by training and analyzing transformer-based humor recognition models on a recently introduced dataset consisting of minimal pairs of aligned sentences, one serious, the other humorous. We find that, although our aligned dataset is much harder than previous datasets, transformer-based models recognize the humorous sentence in an aligned pair with high accuracy (78%). In a careful error analysis, we characterize easy vs hard instances. Finally, by analyzing attention weights, we obtain important insights into the mechanisms by which transformers recognize humor. Most remarkably, we find clear evidence that one single attention head learns to recognize the words that make a test sentence humorous, even without access to this information at training time.
Formation of Social Ties Influences Food Choice: A Campus-Wide Longitudinal Study
Feb 17, 2021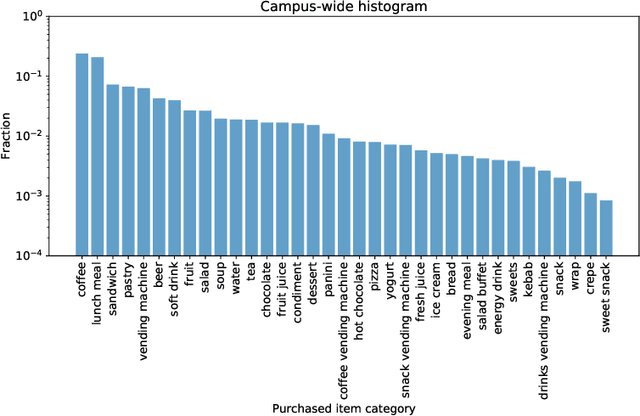
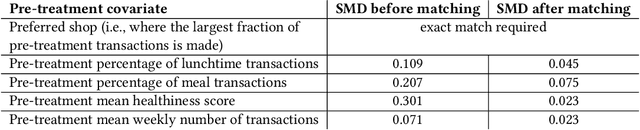
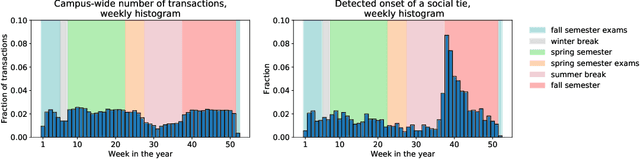
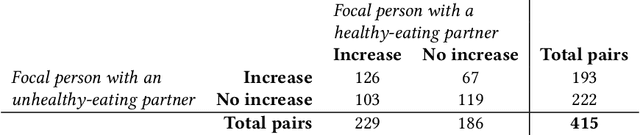
Nutrition is a key determinant of long-term health, and social influence has long been theorized to be a key determinant of nutrition. It has been difficult to quantify the postulated role of social influence on nutrition using traditional methods such as surveys, due to the typically small scale and short duration of studies. To overcome these limitations, we leverage a novel source of data: logs of 38 million food purchases made over an 8-year period on the Ecole Polytechnique Federale de Lausanne (EPFL) university campus, linked to anonymized individuals via the smartcards used to make on-campus purchases. In a longitudinal observational study, we ask: How is a person's food choice affected by eating with someone else whose own food choice is healthy vs. unhealthy? To estimate causal effects from the passively observed log data, we control confounds in a matched quasi-experimental design: we identify focal users who at first do not have any regular eating partners but then start eating with a fixed partner regularly, and we match focal users into comparison pairs such that paired users are nearly identical with respect to covariates measured before acquiring the partner, where the two focal users' new eating partners diverge in the healthiness of their respective food choice. A difference-in-differences analysis of the paired data yields clear evidence of social influence: focal users acquiring a healthy-eating partner change their habits significantly more toward healthy foods than focal users acquiring an unhealthy-eating partner. We further identify foods whose purchase frequency is impacted significantly by the eating partner's healthiness of food choice. Beyond the main results, the work demonstrates the utility of passively sensed food purchase logs for deriving insights, with the potential of informing the design of public health interventions and food offerings.
Adoption of Twitter's New Length Limit: Is 280 the New 140?
Sep 16, 2020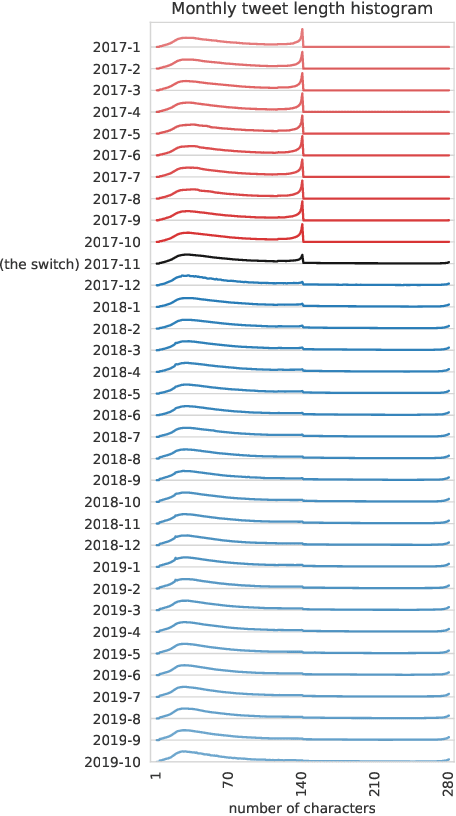
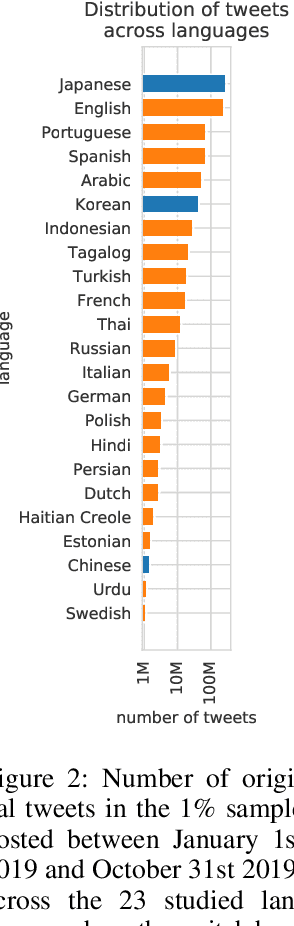
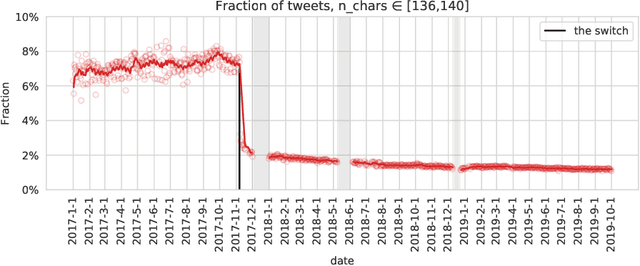
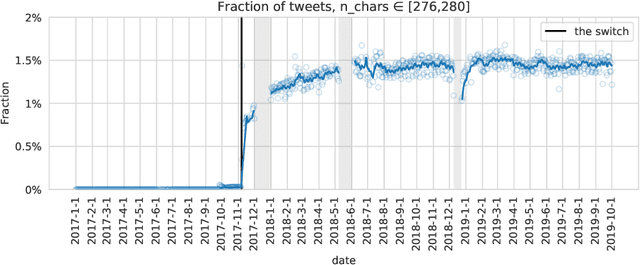
In November 2017, Twitter doubled the maximum allowed tweet length from 140 to 280 characters, a drastic switch on one of the world's most influential social media platforms. In the first long-term study of how the new length limit was adopted by Twitter users, we ask: Does the effect of the new length limit resemble that of the old one? Or did the doubling of the limit fundamentally change how Twitter is shaped by the limited length of posted content? By analyzing Twitter's publicly available 1% sample over a period of around 3 years, we find that, when the length limit was raised from 140 to 280 characters, the prevalence of tweets around 140 characters dropped immediately, while the prevalence of tweets around 280 characters rose steadily for about 6 months. Despite this rise, tweets approaching the length limit have been far less frequent after than before the switch. We find widely different adoption rates across languages and client-device types. The prevalence of tweets around 140 characters before the switch in a given language is strongly correlated with the prevalence of tweets around 280 characters after the switch in the same language, and very long tweets are vastly more popular on Web clients than on mobile clients. Moreover, tweets of around 280 characters after the switch are syntactically and semantically similar to tweets of around 140 characters before the switch, manifesting patterns of message squeezing in both cases. Taken together, these findings suggest that the new 280-character limit constitutes a new, less intrusive version of the old 140-character limit. The length limit remains an important factor that should be considered in all studies using Twitter data.