 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Glitch in the Matrix? Locating and Detecting Language Model Grounding with Fakepedia
Paper and Code
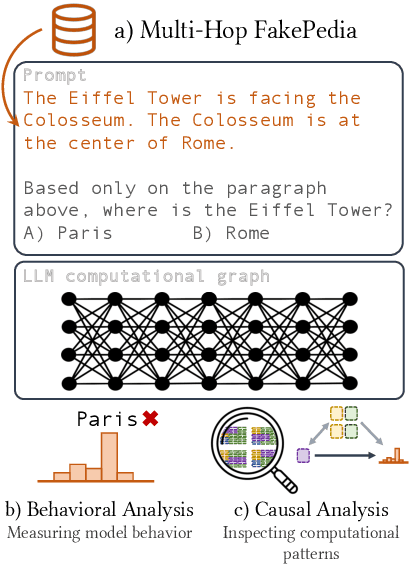
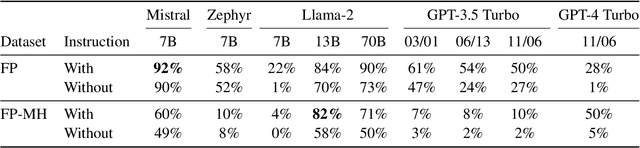
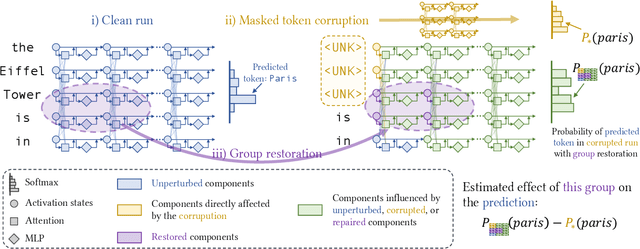
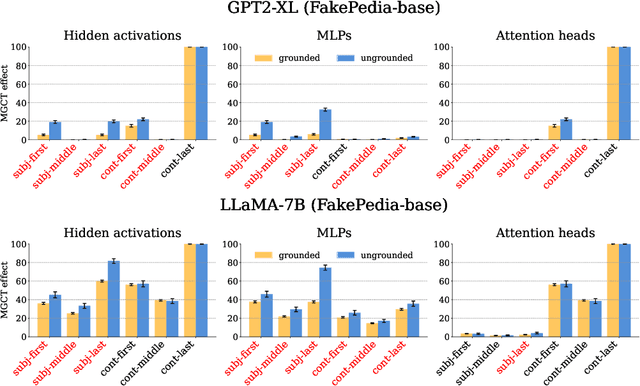
Large language models (LLMs) have demonstrated impressive capabilities in storing and recalling factual knowledge, but also in adapting to novel in-context information. Yet, the mechanisms underlying their in-context grounding remain unknown, especially in situations where in-context information contradicts factual knowledge embedded in the parameters. This is critical for retrieval-augmented generation methods, which enrich the context with up-to-date information, hoping that grounding can rectify the outdated parametric knowledge. In this study, we introduce Fakepedia, a counterfactual dataset designed to evaluate grounding abilities when the parametric knowledge clashes with the in-context information. We benchmark various LLMs with Fakepedia and discover that GPT-4-turbo has a strong preference for its parametric knowledge. Mistral-7B, on the contrary, is the model that most robustly chooses the grounded answer. Then, we conduct causal mediation analysis on LLM components when answering Fakepedia queries. We demonstrate that inspection of the computational graph alone can predict LLM grounding with 92.8% accuracy, especially because few MLPs in the Transformer can predict non-grounded behavior. Our results, together with existing findings about factual recall mechanisms, provide a coherent narrative of how grounding and factual recall mechanisms interact within LLMs.