 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Experimental Data to Evaluate Methods for Observational Causal Inference
Oct 06, 2020

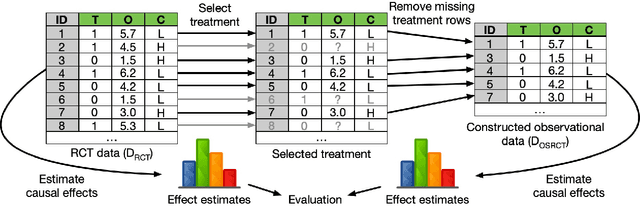
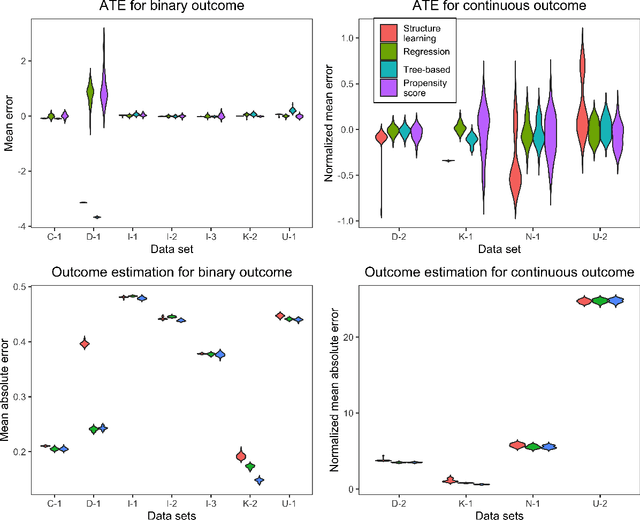
Methods that infer causal dependence from observational data are central to many areas of science, including medicine, economics, and the social sciences. A variety of theoretical properties of these methods have been proven, but empirical evaluation remains a challenge, largely due to the lack of observational data sets for which treatment effect is known. We propose and analyze observational sampling from randomized controlled trials (OSRCT), a method for evaluating causal inference methods using data from randomized controlled trials (RCTs). This method can be used to create constructed observational data sets with corresponding unbiased estimates of treatment effect, substantially increasing the number of data sets available for evaluating causal inference methods. We show that, in expectation, OSRCT creates data sets that are equivalent to those produced by randomly sampling from empirical data sets in which all potential outcomes are available. We analyze several properties of OSRCT theoretically and empirically, and we demonstrate its use by comparing the performance of four causal inference methods using data from eleven RCTs.
The Case for Evaluating Causal Models Using Interventional Measures and Empirical Data
Nov 01, 2019



Causal inference is central to many areas of artificial intelligence, including complex reasoning, planning, knowledge-base construction, robotics, explanation, and fairness. An active community of researchers develops and enhances algorithms that learn causal models from data, and this work has produced a series of impressive technical advances. However, evaluation techniques for causal modeling algorithms have remained somewhat primitive, limiting what we can learn from experimental studies of algorithm performance, constraining the types of algorithms and model representations that researchers consider, and creating a gap between theory and practice. We argue for more frequent use of evaluation techniques that examine interventional measures rather than structural or observational measures, and that evaluate those measures on empirical data rather than synthetic data. We survey the current practice in evaluation and show that the techniques we recommend are rarely used in practice. We show that such techniques are feasible and that data sets are available to conduct such evaluations. We also show that these techniques produce substantially different results than using structural measures and synthetic data.