 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAULT: VAriable Unified Long Text Representation for Machine Reading Comprehension
Paper and Code
Jun 02, 2021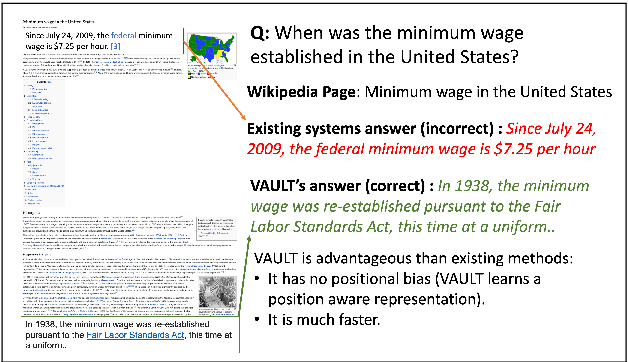
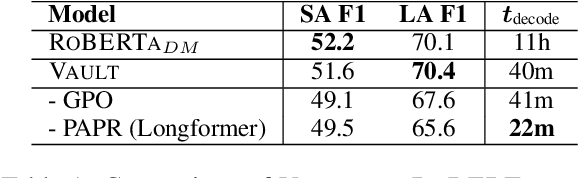
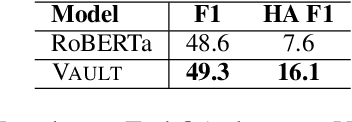
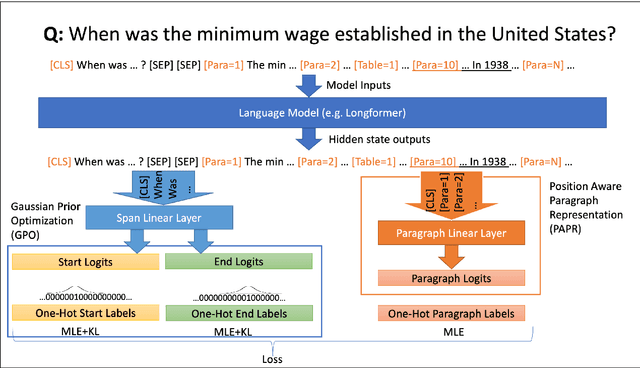
Existing models on Machine Reading Comprehension (MRC) require complex model architecture for effectively modeling long texts with paragraph representation and classification, thereby making inference computationally inefficient for production use. In this work, we propose VAULT: a light-weight and parallel-efficient paragraph representation for MRC based on contextualized representation from long document input, trained using a new Gaussian distribution-based objective that pays close attention to the partially correct instances that are close to the ground-truth. We validate our VAULT architecture showing experimental results on two benchmark MRC datasets that require long context modeling; one Wikipedia-based (Natural Questions (NQ)) and the other on TechNotes (TechQA). VAULT can achieve comparable performance on NQ with a state-of-the-art (SOTA) complex document modeling approach while being 16 times faster, demonstrating the efficiency of our proposed model. We also demonstrate that our model can also be effectively adapted to a completely different domain -- TechQA -- with large improvement over a model fine-tuned on a previously published large PLM.