 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrustratingly Easy Natural Question Answering
Paper and Code
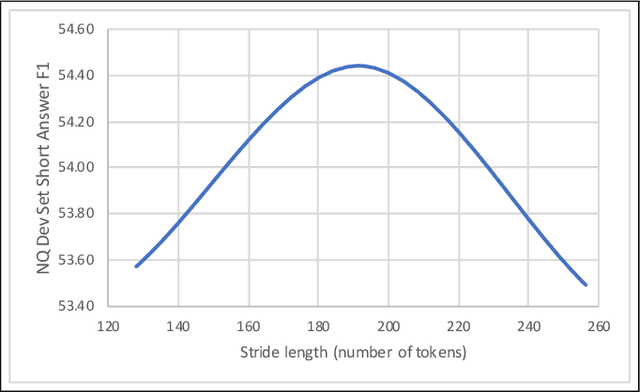
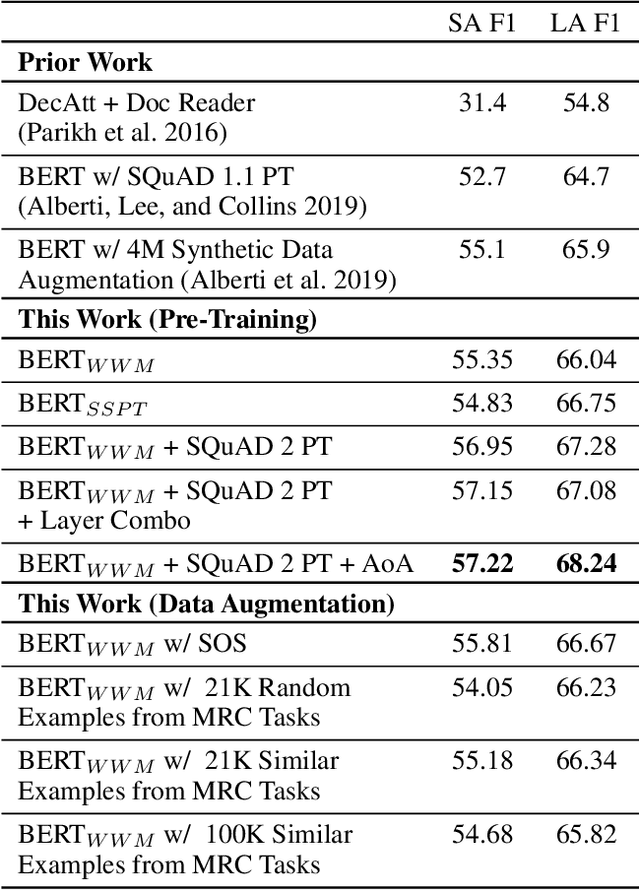
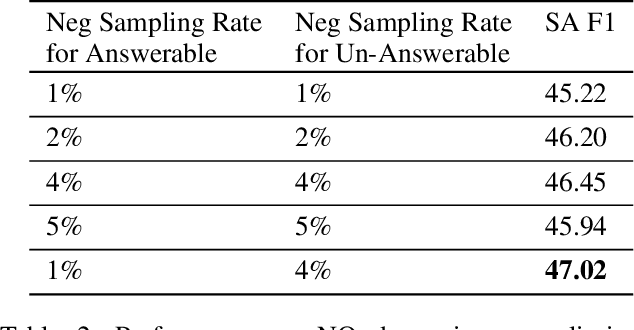
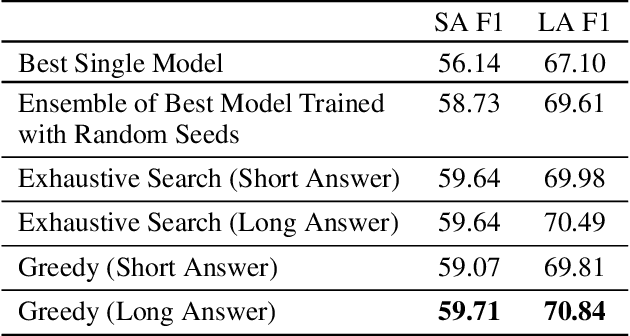
Existing literature on Question Answering (QA) mostly focuses on algorithmic novelty, data augmentation, or increasingly large pre-trained language models like XLNet and RoBERTa. Additionally, a lot of systems on the QA leaderboards do not have associated research documentation in order to successfully replicate their experiments. In this paper, we outline these algorithmic components such as Attention-over-Attention, coupled with data augmentation and ensembling strategies that have shown to yield state-of-the-art results on benchmark datasets like SQuAD, even achieving super-human performance. Contrary to these prior results, when we evaluate on the recently proposed Natural Questions benchmark dataset, we find that an incredibly simple approach of transfer learning from BERT outperforms the previous state-of-the-art system trained on 4 million more examples than ours by 1.9 F1 points. Adding ensembling strategies further improves that number by 2.3 F1 points.