 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Answers to Boolean Questions Need Explanations? Yes
Paper and Code
Dec 14, 2021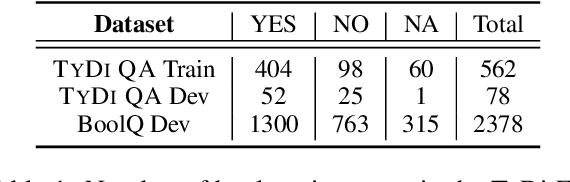


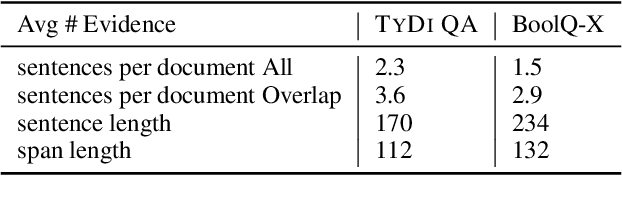
Existing datasets that contain boolean questions, such as BoolQ and TYDI QA , provide the user with a YES/NO response to the question. However, a one word response is not sufficient for an explainable system. We promote explainability by releasing a new set of annotations marking the evidence in existing TyDi QA and BoolQ datasets. We show that our annotations can be used to train a model that extracts improved evidence spans compared to models that rely on existing resources. We confirm our findings with a user study which shows that our extracted evidence spans enhance the user experience. We also provide further insight into the challenges of answering boolean questions, such as passages containing conflicting YES and NO answers, and varying degrees of relevance of the predicted evidence.