 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINDIC QA BENCHMARK: A Multilingual Benchmark to Evaluate Question Answering capability of LLMs for Indic Languages
Jul 18, 2024



Large Language Models (LLMs) have demonstrated remarkable zero-shot and few-shot capabilities in unseen tasks, including context-grounded question answering (QA) in English. However, the evaluation of LLMs' capabilities in non-English languages for context-based QA is limited by the scarcity of benchmarks in non-English languages. To address this gap, we introduce Indic-QA, the largest publicly available context-grounded question-answering dataset for 11 major Indian languages from two language families. The dataset comprises both extractive and abstractive question-answering tasks and includes existing datasets as well as English QA datasets translated into Indian languages. Additionally, we generate a synthetic dataset using the Gemini model to create question-answer pairs given a passage, which is then manually verified for quality assurance. We evaluate various multilingual Large Language Models and their instruction-fine-tuned variants on the benchmark and observe that their performance is subpar, particularly for low-resource languages. We hope that the release of this dataset will stimulate further research on the question-answering abilities of LLMs for low-resource languages.
FashionSD-X: Multimodal Fashion Garment Synthesis using Latent Diffusion
Apr 26, 2024The rapid evolution of the fashion industry increasingly intersects with technological advancements, particularly through the integration of generative AI. This study introduces a novel generative pipeline designed to transform the fashion design process by employing latent diffusion models. Utilizing ControlNet and LoRA fine-tuning, our approach generates high-quality images from multimodal inputs such as text and sketches. We leverage and enhance state-of-the-art virtual try-on datasets, including Multimodal Dress Code and VITON-HD, by integrating sketch data. Our evaluation, utilizing metrics like FID, CLIP Score, and KID, demonstrates that our model significantly outperforms traditional stable diffusion models. The results not only highlight the effectiveness of our model in generating fashion-appropriate outputs but also underscore the potential of diffusion models in revolutionizing fashion design workflows. This research paves the way for more interactive, personalized, and technologically enriched methodologies in fashion design and representation, bridging the gap between creative vision and practical application.
Optimizing Reconfigurable Antenna MIMO Systems with Coherent Ising Machines
Mar 19, 2024Reconfigurable antenna multiple-input multiple-output (MIMO) is a promising technology for upcoming 6G communication systems. In this paper, we deal with the problem of configuration selection for reconfigurable antenna MIMO by leveraging Coherent Ising Machines (CIMs). By adopting the CIM as a heuristic solver for the Ising problem, the optimal antenna configuration that maximizes the received signal-to-noise ratio is investigated. A mathematical framework that converts the selection problem into a CIM-compatible unconstrained quadratic formulation is presented. Numerical studies show that the proposed CIM-based design outperforms classical counterparts and achieves near-optimal performance (similar to exponentially complex exhaustive searching) while ensuring polynomial complexity.
Using network metrics to explore the community structure that underlies movement patterns
Sep 14, 2023This work aims to explore the community structure of Santiago de Chile by analyzing the movement patterns of its residents. We use a dataset containing the approximate locations of home and work places for a subset of anonymized residents to construct a network that represents the movement patterns within the city. Through the analysis of this network, we aim to identify the communities or sub-cities that exist within Santiago de Chile and gain insights into the factors that drive the spatial organization of the city. We employ modularity optimization algorithms and clustering techniques to identify the communities within the network. Our results present that the novelty of combining community detection algorithms with segregation tools provides new insights to further the understanding of the complex geography of segregation during working hours.
Uplink MIMO Detection using Ising Machines: A Multi-Stage Ising Approach
Apr 25, 2023Multiple-Input-Multiple-Output~(MIMO) signal detection is central to every state-of-the-art communication system, and enhancements in error performance and computation complexity of MIMO detection would significantly enhance data rate and latency experienced by the users. Theoretically, the optimal MIMO detector is the maximum-likelihood (ML) MIMO detector; however, due to its extremely high complexity, it is not feasible for large real-world communication systems. Over the past few years, algorithms based on physics-inspired Ising solvers, like Coherent Ising machines and Quantum Annealers, have shown significant performance improvements for the MIMO detection problem. However, the current state-of-the-art is limited to low-order modulations or systems with few users. In this paper, we propose an adaptive multi-stage Ising machine-based MIMO detector that extends the performance gains of physics-inspired computation to Large and Massive MIMO systems with a large number of users and very high modulation schemes~(up to 256-QAM). We enhance our previously proposed delta Ising formulation and develop a heuristic that adaptively optimizes the performance and complexity of our proposed method. We perform extensive micro-benchmarking to optimize several free parameters of the system and evaluate our methods' BER and spectral efficiency for Large and Massive MIMO systems (up to 32 users and 256 QAM modulation).
Hybrid MemNet for Extractive Summarization
Dec 25, 2019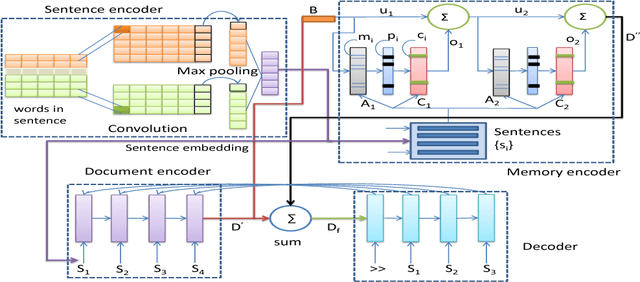
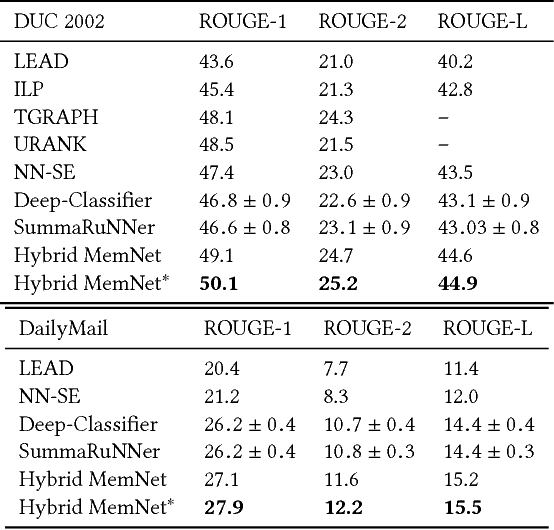
Extractive text summarization has been an extensive research problem in the field of natural language understanding. While the conventional approaches rely mostly on manually compiled features to generate the summary, few attempts have been made in developing data-driven systems for extractive summarization. To this end, we present a fully data-driven end-to-end deep network which we call as Hybrid MemNet for single document summarization task. The network learns the continuous unified representation of a document before generating its summary. It jointly captures local and global sentential information along with the notion of summary worthy sentences. Experimental results on two different corpora confirm that our model shows significant performance gains compared with the state-of-the-art baselines.
* Accepted in CIKM '17 Proceedings of the 2017 ACM on Conference on Information and Knowledge Management
Unity in Diversity: Learning Distributed Heterogeneous Sentence Representation for Extractive Summarization
Dec 25, 2019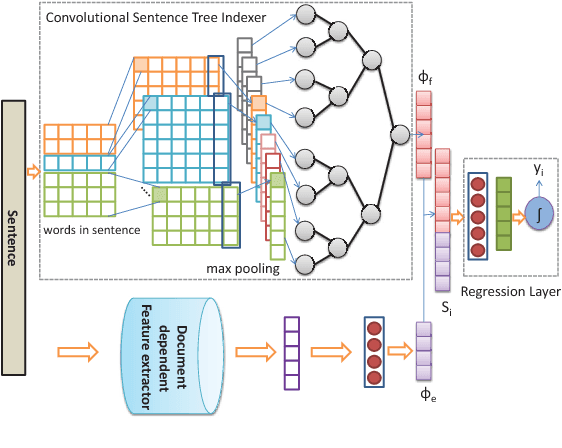

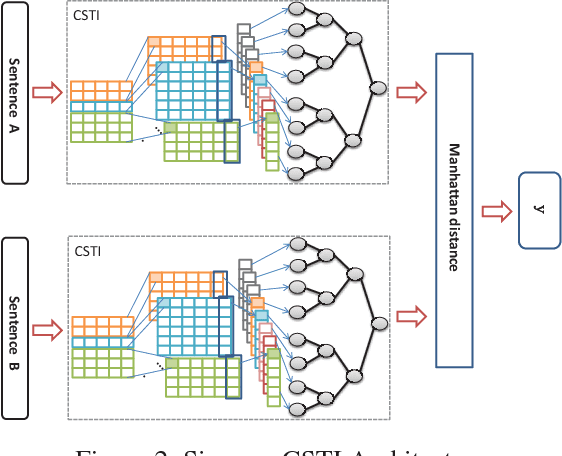
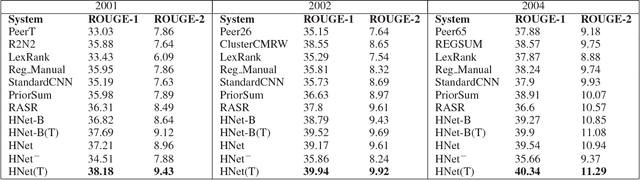
Automated multi-document extractive text summarization is a widely studied research problem in the field of natural language understanding. Such extractive mechanisms compute in some form the worthiness of a sentence to be included into the summary. While the conventional approaches rely on human crafted document-independent features to generate a summary, we develop a data-driven novel summary system called HNet, which exploits the various semantic and compositional aspects latent in a sentence to capture document independent features. The network learns sentence representation in a way that, salient sentences are closer in the vector space than non-salient sentences. This semantic and compositional feature vector is then concatenated with the document-dependent features for sentence ranking. Experiments on the DUC benchmark datasets (DUC-2001, DUC-2002 and DUC-2004) indicate that our model shows significant performance gain of around 1.5-2 points in terms of ROUGE score compared with the state-of-the-art baselines.