 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual Adaptive Assignment Approach for Robust Graph-Based Clustering
Oct 29, 2024



Graph clustering is an essential aspect of network analysis that involves grouping nodes into separate clusters. Recent developments in deep learning have resulted in advanced deep graph clustering techniques, which have proven effective in many applications. Nonetheless, these methods often encounter difficulties when dealing with the complexities of real-world graphs, particularly in the presence of noisy edges. Additionally, many denoising graph clustering strategies tend to suffer from lower performance compared to their non-denoised counterparts, training instability, and challenges in scaling to large datasets. To tackle these issues, we introduce a new framework called the Dual Adaptive Assignment Approach for Robust Graph-Based Clustering (RDSA). RDSA consists of three key components: (i) a node embedding module that effectively integrates the graph's topological features and node attributes; (ii) a structure-based soft assignment module that improves graph modularity by utilizing an affinity matrix for node assignments; and (iii) a node-based soft assignment module that identifies community landmarks and refines node assignments to enhance the model's robustness. We assess RDSA on various real-world datasets, demonstrating its superior performance relative to existing state-of-the-art methods. Our findings indicate that RDSA provides robust clustering across different graph types, excelling in clustering effectiveness and robustness, including adaptability to noise, stability, and scalability.
An EcoSage Assistant: Towards Building A Multimodal Plant Care Dialogue Assistant
Jan 10, 2024In recent times, there has been an increasing awareness about imminent environmental challenges, resulting in people showing a stronger dedication to taking care of the environment and nurturing green life. The current $19.6 billion indoor gardening industry, reflective of this growing sentiment, not only signifies a monetary value but also speaks of a profound human desire to reconnect with the natural world. However, several recent surveys cast a revealing light on the fate of plants within our care, with more than half succumbing primarily due to the silent menace of improper care. Thus, the need for accessible expertise capable of assisting and guiding individuals through the intricacies of plant care has become paramount more than ever. In this work, we make the very first attempt at building a plant care assistant, which aims to assist people with plant(-ing) concerns through conversations. We propose a plant care conversational dataset named Plantational, which contains around 1K dialogues between users and plant care experts. Our end-to-end proposed approach is two-fold : (i) We first benchmark the dataset with the help of various large language models (LLMs) and visual language model (VLM) by studying the impact of instruction tuning (zero-shot and few-shot prompting) and fine-tuning techniques on this task; (ii) finally, we build EcoSage, a multi-modal plant care assisting dialogue generation framework, incorporating an adapter-based modality infusion using a gated mechanism. We performed an extensive examination (both automated and manual evaluation) of the performance exhibited by various LLMs and VLM in the generation of the domain-specific dialogue responses to underscore the respective strengths and weaknesses of these diverse models.
GRETEL: Graph Contrastive Topic Enhanced Language Model for Long Document Extractive Summarization
Aug 21, 2022

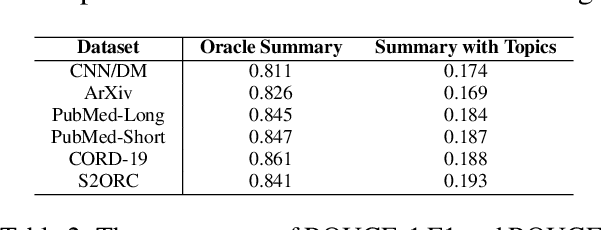

Recently, neural topic models (NTMs) have been incorporated into pre-trained language models (PLMs), to capture the global semantic information for text summarization. However, in these methods, there remain limitations in the way they capture and integrate the global semantic information. In this paper, we propose a novel model, the graph contrastive topic enhanced language model (GRETEL), that incorporates the graph contrastive topic model with the pre-trained language model, to fully leverage both the global and local contextual semantics for long document extractive summarization. To better capture and incorporate the global semantic information into PLMs, the graph contrastive topic model integrates the hierarchical transformer encoder and the graph contrastive learning to fuse the semantic information from the global document context and the gold summary. To this end, GRETEL encourages the model to efficiently extract salient sentences that are topically related to the gold summary, rather than redundant sentences that cover sub-optimal topics. Experimental results on both general domain and biomedical datasets demonstrate that our proposed method outperforms SOTA methods.