 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem-Mediated Attention Imbalances Make Vision-Language Models Say Yes
Jan 18, 2026Vision-language model (VLM) hallucination is commonly linked to imbalanced allocation of attention across input modalities: system, image and text. However, existing mitigation strategies tend towards an image-centric interpretation of these imbalances, often prioritising increased image attention while giving less consideration to the roles of the other modalities. In this study, we evaluate a more holistic, system-mediated account, which attributes these imbalances to functionally redundant system weights that reduce attention to image and textual inputs. We show that this framework offers a useful empirical perspective on the yes-bias, a common form of hallucination in which VLMs indiscriminately respond 'yes'. Causally redistributing attention from the system modality to image and textual inputs substantially suppresses this bias, often outperforming existing approaches. We further present evidence suggesting that system-mediated attention imbalances contribute to the yes-bias by encouraging a default reliance on coarse input representations, which are effective for some tasks but ill-suited to others. Taken together, these findings firmly establish system attention as a key factor in VLM hallucination and highlight its potential as a lever for mitigation.
Wisdom of the Crowds in Forecasting: Forecast Summarization for Supporting Future Event Prediction
Feb 12, 2025Future Event Prediction (FEP) is an essential activity whose demand and application range across multiple domains. While traditional methods like simulations, predictive and time-series forecasting have demonstrated promising outcomes, their application in forecasting complex events is not entirely reliable due to the inability of numerical data to accurately capture the semantic information related to events. One forecasting way is to gather and aggregate collective opinions on the future to make predictions as cumulative perspectives carry the potential to help estimating the likelihood of upcoming events. In this work, we organize the existing research and frameworks that aim to support future event prediction based on crowd wisdom through aggregating individual forecasts. We discuss the challenges involved, available datasets, as well as the scope of improvement and future research directions for this task. We also introduce a novel data model to represent individual forecast statements.
Two eyes, Two views, and finally, One summary! Towards Multi-modal Multi-tasking Knowledge-Infused Medical Dialogue Summarization
Jul 21, 2024

We often summarize a multi-party conversation in two stages: chunking with homogeneous units and summarizing the chunks. Thus, we hypothesize that there exists a correlation between homogeneous speaker chunking and overall summarization tasks. In this work, we investigate the effectiveness of a multi-faceted approach that simultaneously produces summaries of medical concerns, doctor impressions, and an overall view. We introduce a multi-modal, multi-tasking, knowledge-infused medical dialogue summary generation (MMK-Summation) model, which is incorporated with adapter-based fine-tuning through a gated mechanism for multi-modal information integration. The model, MMK-Summation, takes dialogues as input, extracts pertinent external knowledge based on the context, integrates the knowledge and visual cues from the dialogues into the textual content, and ultimately generates concise summaries encompassing medical concerns, doctor impressions, and a comprehensive overview. The introduced model surpasses multiple baselines and traditional summarization models across all evaluation metrics (including human evaluation), which firmly demonstrates the efficacy of the knowledge-guided multi-tasking, multimodal medical conversation summarization. The code is available at https://github.com/NLP-RL/MMK-Summation.
Experience and Evidence are the eyes of an excellent summarizer! Towards Knowledge Infused Multi-modal Clinical Conversation Summarization
Sep 27, 2023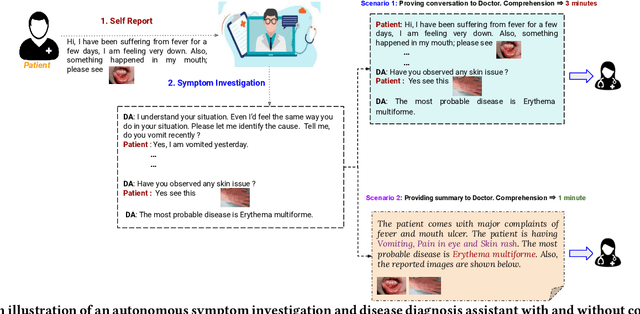

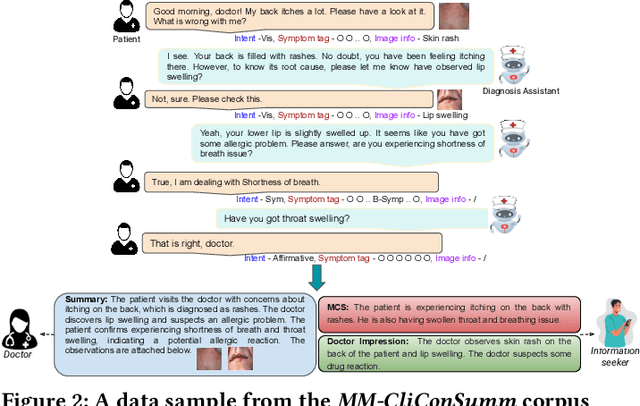
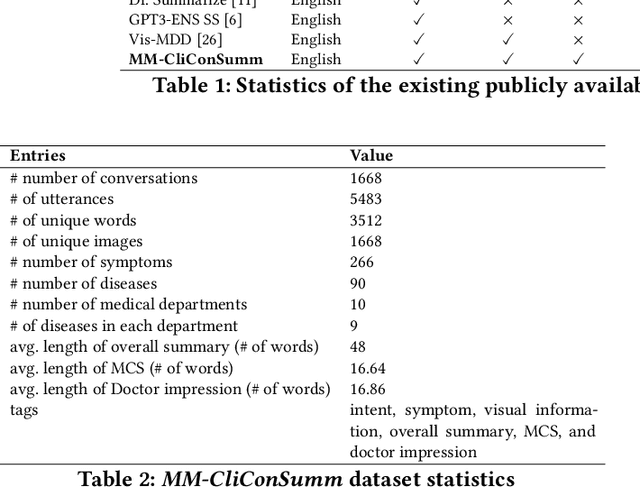
With the advancement of telemedicine, both researchers and medical practitioners are working hand-in-hand to develop various techniques to automate various medical operations, such as diagnosis report generation. In this paper, we first present a multi-modal clinical conversation summary generation task that takes a clinician-patient interaction (both textual and visual information) and generates a succinct synopsis of the conversation. We propose a knowledge-infused, multi-modal, multi-tasking medical domain identification and clinical conversation summary generation (MM-CliConSummation) framework. It leverages an adapter to infuse knowledge and visual features and unify the fused feature vector using a gated mechanism. Furthermore, we developed a multi-modal, multi-intent clinical conversation summarization corpus annotated with intent, symptom, and summary. The extensive set of experiments, both quantitatively and qualitatively, led to the following findings: (a) critical significance of visuals, (b) more precise and medical entity preserving summary with additional knowledge infusion, and (c) a correlation between medical department identification and clinical synopsis generation. Furthermore, the dataset and source code are available at https://github.com/NLP-RL/MM-CliConSummation.