 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSRIM: A Deep Neural Information Retrieval Model Enhanced by a Knowledge Resource Driven Representation of Documents
Jul 27, 2017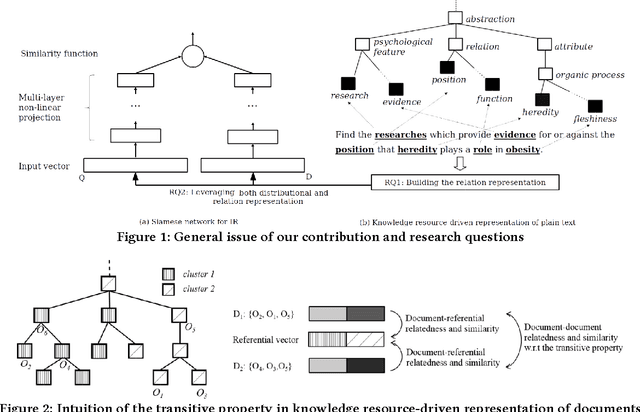

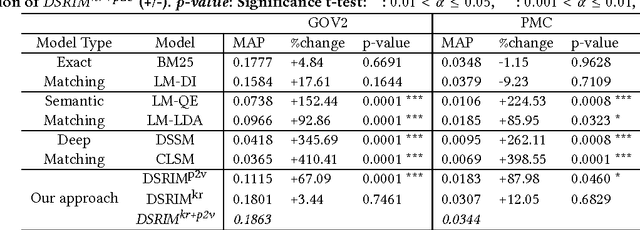
The state-of-the-art solutions to the vocabulary mismatch in information retrieval (IR) mainly aim at leveraging either the relational semantics provided by external resources or the distributional semantics, recently investigated by deep neural approaches. Guided by the intuition that the relational semantics might improve the effectiveness of deep neural approaches, we propose the Deep Semantic Resource Inference Model (DSRIM) that relies on: 1) a representation of raw-data that models the relational semantics of text by jointly considering objects and relations expressed in a knowledge resource, and 2) an end-to-end neural architecture that learns the query-document relevance by leveraging the distributional and relational semantics of documents and queries. The experimental evaluation carried out on two TREC datasets from TREC Terabyte and TREC CDS tracks relying respectively on WordNet and MeSH resources, indicates that our model outperforms state-of-the-art semantic and deep neural IR models.
Toward a Deep Neural Approach for Knowledge-Based IR
Jun 23, 2016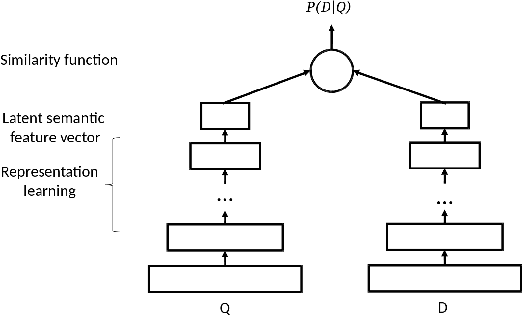
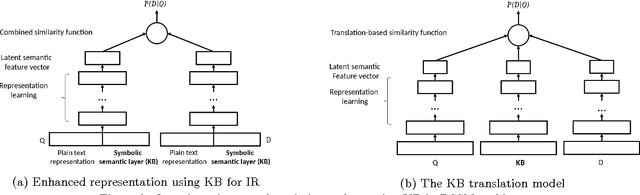
This paper tackles the problem of the semantic gap between a document and a query within an ad-hoc information retrieval task. In this context, knowledge bases (KBs) have already been acknowledged as valuable means since they allow the representation of explicit relations between entities. However, they do not necessarily represent implicit relations that could be hidden in a corpora. This latter issue is tackled by recent works dealing with deep representation learn ing of texts. With this in mind, we argue that embedding KBs within deep neural architectures supporting documentquery matching would give rise to fine-grained latent representations of both words and their semantic relations. In this paper, we review the main approaches of neural-based document ranking as well as those approaches for latent representation of entities and relations via KBs. We then propose some avenues to incorporate KBs in deep neural approaches for document ranking. More particularly, this paper advocates that KBs can be used either to support enhanced latent representations of queries and documents based on both distributional and relational semantics or to serve as a semantic translator between their latent distributional representations.