 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSRIM: A Deep Neural Information Retrieval Model Enhanced by a Knowledge Resource Driven Representation of Documents
Paper and Code
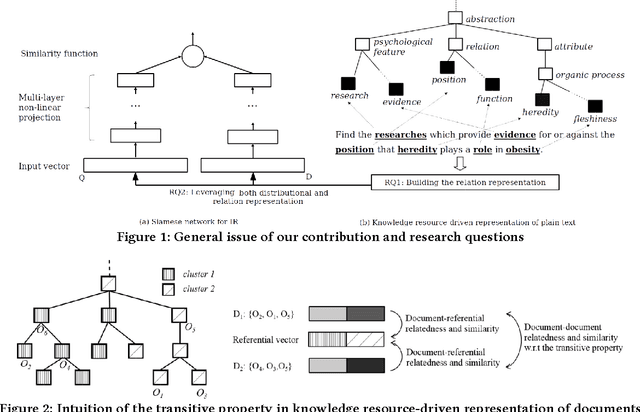

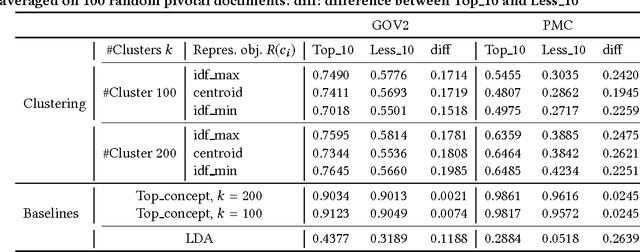
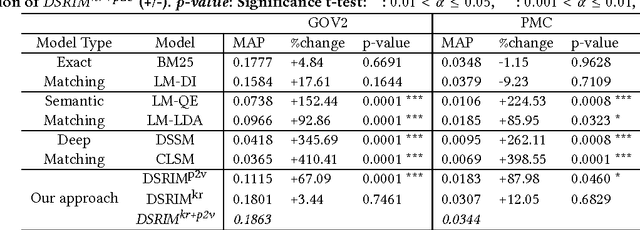
The state-of-the-art solutions to the vocabulary mismatch in information retrieval (IR) mainly aim at leveraging either the relational semantics provided by external resources or the distributional semantics, recently investigated by deep neural approaches. Guided by the intuition that the relational semantics might improve the effectiveness of deep neural approaches, we propose the Deep Semantic Resource Inference Model (DSRIM) that relies on: 1) a representation of raw-data that models the relational semantics of text by jointly considering objects and relations expressed in a knowledge resource, and 2) an end-to-end neural architecture that learns the query-document relevance by leveraging the distributional and relational semantics of documents and queries. The experimental evaluation carried out on two TREC datasets from TREC Terabyte and TREC CDS tracks relying respectively on WordNet and MeSH resources, indicates that our model outperforms state-of-the-art semantic and deep neural IR models.