 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying User Coherence: A Unified Framework for Cross-Domain Recommendation Analysis
Oct 03, 2024



The effectiveness of Recommender Systems (RS) is closely tied to the quality and distinctiveness of user profiles, yet despite many advancements in raw performance, the sensitivity of RS to user profile quality remains under-researched. This paper introduces novel information-theoretic measures for understanding recommender systems: a "surprise" measure quantifying users' deviations from popular choices, and a "conditional surprise" measure capturing user interaction coherence. We evaluate 7 recommendation algorithms across 9 datasets, revealing the relationships between our measures and standard performance metrics. Using a rigorous statistical framework, our analysis quantifies how much user profile density and information measures impact algorithm performance across domains. By segmenting users based on these measures, we achieve improved performance with reduced data and show that simpler algorithms can match complex ones for low-coherence users. Additionally, we employ our measures to analyze how well different recommendation algorithms maintain the coherence and diversity of user preferences in their predictions, providing insights into algorithm behavior. This work advances the theoretical understanding of user behavior and practical heuristics for personalized recommendation systems, promoting more efficient and adaptive architectures.
An Analysis of Initial Training Strategies for Exemplar-Free Class-Incremental Learning
Aug 22, 2023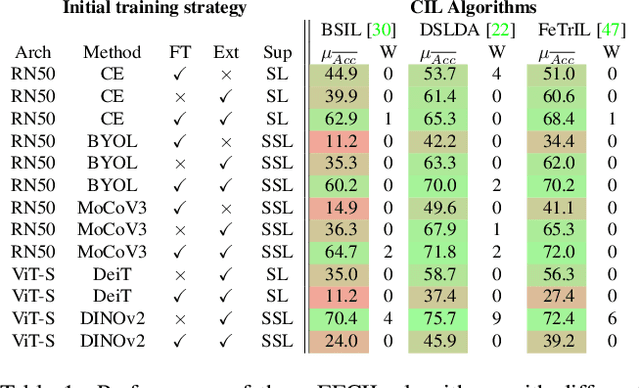
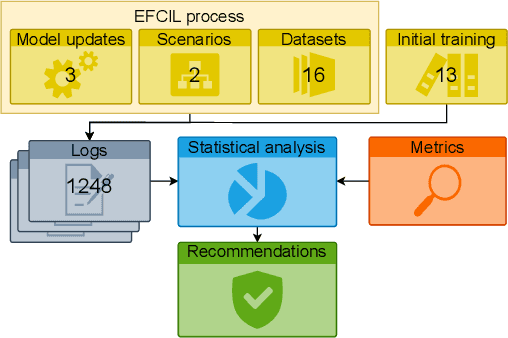

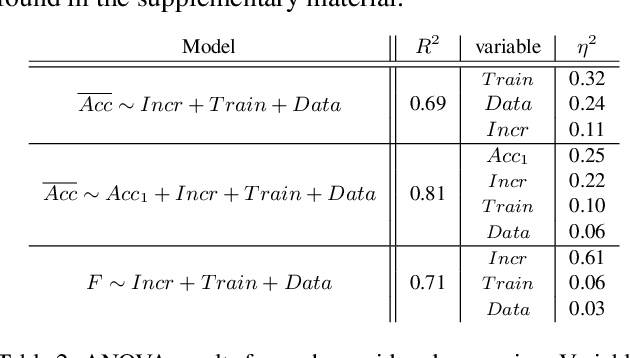
Class-Incremental Learning (CIL) aims to build classification models from data streams. At each step of the CIL process, new classes must be integrated into the model. Due to catastrophic forgetting, CIL is particularly challenging when examples from past classes cannot be stored, the case on which we focus here. To date, most approaches are based exclusively on the target dataset of the CIL process. However, the use of models pre-trained in a self-supervised way on large amounts of data has recently gained momentum. The initial model of the CIL process may only use the first batch of the target dataset, or also use pre-trained weights obtained on an auxiliary dataset. The choice between these two initial learning strategies can significantly influence the performance of the incremental learning model, but has not yet been studied in depth. Performance is also influenced by the choice of the CIL algorithm, the neural architecture, the nature of the target task, the distribution of classes in the stream and the number of examples available for learning. We conduct a comprehensive experimental study to assess the roles of these factors. We present a statistical analysis framework that quantifies the relative contribution of each factor to incremental performance. Our main finding is that the initial training strategy is the dominant factor influencing the average incremental accuracy, but that the choice of CIL algorithm is more important in preventing forgetting. Based on this analysis, we propose practical recommendations for choosing the right initial training strategy for a given incremental learning use case. These recommendations are intended to facilitate the practical deployment of incremental learning.
FeTrIL: Feature Translation for Exemplar-Free Class-Incremental Learning
Nov 23, 2022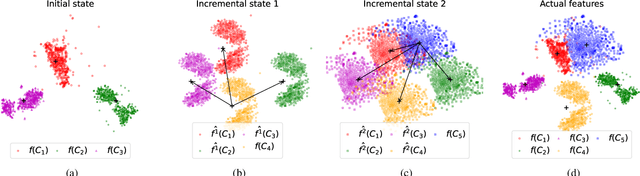



Exemplar-free class-incremental learning is very challenging due to the negative effect of catastrophic forgetting. A balance between stability and plasticity of the incremental process is needed in order to obtain good accuracy for past as well as new classes. Existing exemplar-free class-incremental methods focus either on successive fine tuning of the model, thus favoring plasticity, or on using a feature extractor fixed after the initial incremental state, thus favoring stability. We introduce a method which combines a fixed feature extractor and a pseudo-features generator to improve the stability-plasticity balance. The generator uses a simple yet effective geometric translation of new class features to create representations of past classes, made of pseudo-features. The translation of features only requires the storage of the centroid representations of past classes to produce their pseudo-features. Actual features of new classes and pseudo-features of past classes are fed into a linear classifier which is trained incrementally to discriminate between all classes. The incremental process is much faster with the proposed method compared to mainstream ones which update the entire deep model. Experiments are performed with three challenging datasets, and different incremental settings. A comparison with ten existing methods shows that our method outperforms the others in most cases.
PlaStIL: Plastic and Stable Memory-Free Class-Incremental Learning
Sep 14, 2022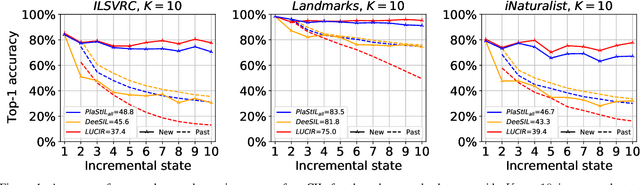
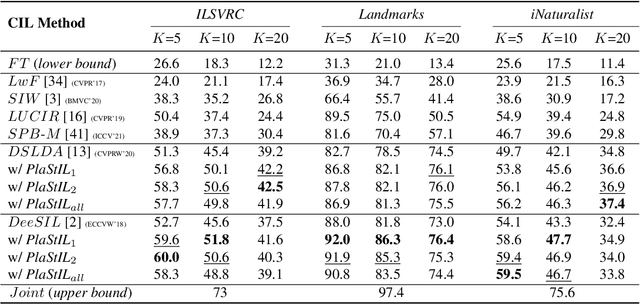
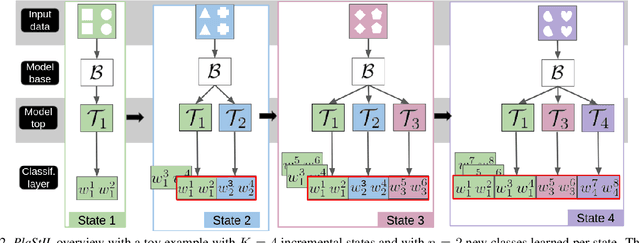
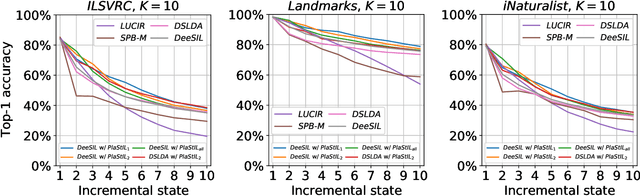
Plasticity and stability are needed in class-incremental learning in order to learn from new data while preserving past knowledge. Due to catastrophic forgetting, finding a compromise between these two properties is particularly challenging when no memory buffer is available. Mainstream methods need to store two deep models since they integrate new classes using fine tuning with knowledge distillation from the previous incremental state. We propose a method which has similar number of parameters but distributes them differently in order to find a better balance between plasticity and stability. Following an approach already deployed by transfer-based incremental methods, we freeze the feature extractor after the initial state. Classes in the oldest incremental states are trained with this frozen extractor to ensure stability. Recent classes are predicted using partially fine-tuned models in order to introduce plasticity. Our proposed plasticity layer can be incorporated to any transfer-based method designed for memory-free incremental learning, and we apply it to two such methods. Evaluation is done with three large-scale datasets. Results show that performance gains are obtained in all tested configurations compared to existing methods.
Visual Relationship Detection Based on Guided Proposals and Semantic Knowledge Distillation
May 28, 2018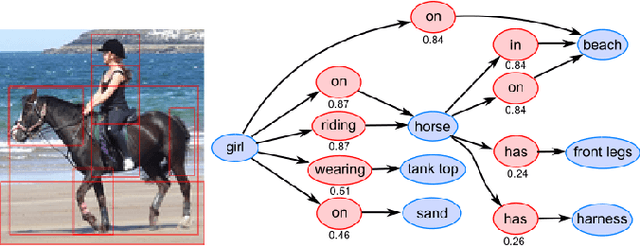

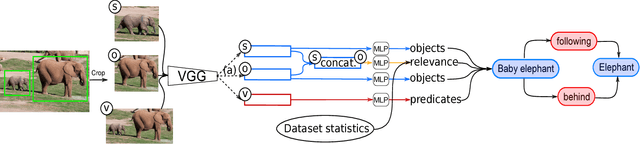

A thorough comprehension of image content demands a complex grasp of the interactions that may occur in the natural world. One of the key issues is to describe the visual relationships between objects. When dealing with real world data, capturing these very diverse interactions is a difficult problem. It can be alleviated by incorporating common sense in a network. For this, we propose a framework that makes use of semantic knowledge and estimates the relevance of object pairs during both training and test phases. Extracted from precomputed models and training annotations, this information is distilled into the neural network dedicated to this task. Using this approach, we observe a significant improvement on all classes of Visual Genome, a challenging visual relationship dataset. A 68.5% relative gain on the recall at 100 is directly related to the relevance estimate and a 32.7% gain to the knowledge distillation.