 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Posology Structuration : What role for LLMs?
Jun 24, 2025Automatically structuring posology instructions is essential for improving medication safety and enabling clinical decision support. In French prescriptions, these instructions are often ambiguous, irregular, or colloquial, limiting the effectiveness of classic ML pipelines. We explore the use of Large Language Models (LLMs) to convert free-text posologies into structured formats, comparing prompt-based methods and fine-tuning against a "pre-LLM" system based on Named Entity Recognition and Linking (NERL). Our results show that while prompting improves performance, only fine-tuned LLMs match the accuracy of the baseline. Through error analysis, we observe complementary strengths: NERL offers structural precision, while LLMs better handle semantic nuances. Based on this, we propose a hybrid pipeline that routes low-confidence cases from NERL (<0.8) to the LLM, selecting outputs based on confidence scores. This strategy achieves 91% structuration accuracy while minimizing latency and compute. Our results show that this hybrid approach improves structuration accuracy while limiting computational cost, offering a scalable solution for real-world clinical use.
Multilingual Transformer Encoders: a Word-Level Task-Agnostic Evaluation
Jul 19, 2022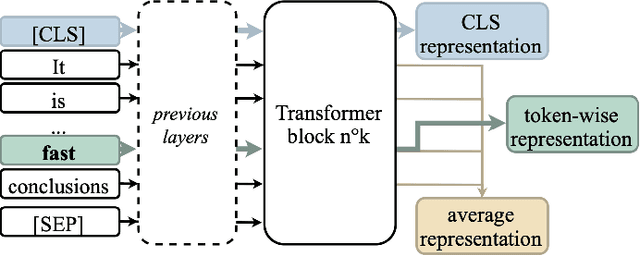
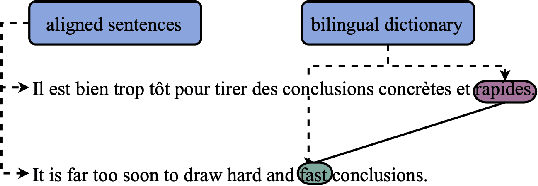

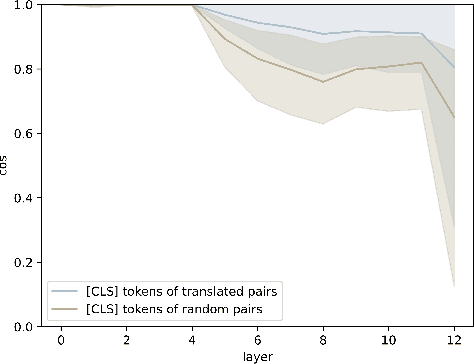
Some Transformer-based models can perform cross-lingual transfer learning: those models can be trained on a specific task in one language and give relatively good results on the same task in another language, despite having been pre-trained on monolingual tasks only. But, there is no consensus yet on whether those transformer-based models learn universal patterns across languages. We propose a word-level task-agnostic method to evaluate the alignment of contextualized representations built by such models. We show that our method provides more accurate translated word pairs than previous methods to evaluate word-level alignment. And our results show that some inner layers of multilingual Transformer-based models outperform other explicitly aligned representations, and even more so according to a stricter definition of multilingual alignment.
Visual Relationship Detection Based on Guided Proposals and Semantic Knowledge Distillation
May 28, 2018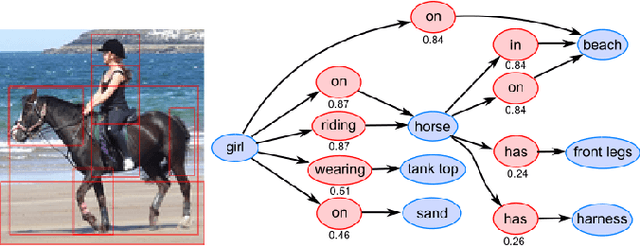

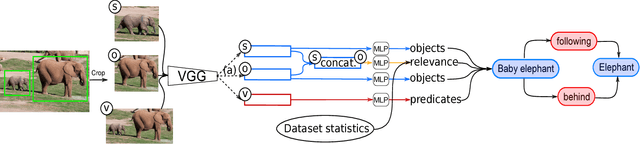

A thorough comprehension of image content demands a complex grasp of the interactions that may occur in the natural world. One of the key issues is to describe the visual relationships between objects. When dealing with real world data, capturing these very diverse interactions is a difficult problem. It can be alleviated by incorporating common sense in a network. For this, we propose a framework that makes use of semantic knowledge and estimates the relevance of object pairs during both training and test phases. Extracted from precomputed models and training annotations, this information is distilled into the neural network dedicated to this task. Using this approach, we observe a significant improvement on all classes of Visual Genome, a challenging visual relationship dataset. A 68.5% relative gain on the recall at 100 is directly related to the relevance estimate and a 32.7% gain to the knowledge distillation.