 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Posology Structuration : What role for LLMs?
Jun 24, 2025Automatically structuring posology instructions is essential for improving medication safety and enabling clinical decision support. In French prescriptions, these instructions are often ambiguous, irregular, or colloquial, limiting the effectiveness of classic ML pipelines. We explore the use of Large Language Models (LLMs) to convert free-text posologies into structured formats, comparing prompt-based methods and fine-tuning against a "pre-LLM" system based on Named Entity Recognition and Linking (NERL). Our results show that while prompting improves performance, only fine-tuned LLMs match the accuracy of the baseline. Through error analysis, we observe complementary strengths: NERL offers structural precision, while LLMs better handle semantic nuances. Based on this, we propose a hybrid pipeline that routes low-confidence cases from NERL (<0.8) to the LLM, selecting outputs based on confidence scores. This strategy achieves 91% structuration accuracy while minimizing latency and compute. Our results show that this hybrid approach improves structuration accuracy while limiting computational cost, offering a scalable solution for real-world clinical use.
AlignFreeze: Navigating the Impact of Realignment on the Layers of Multilingual Models Across Diverse Languages
Feb 18, 2025Realignment techniques are often employed to enhance cross-lingual transfer in multilingual language models, still, they can sometimes degrade performance in languages that differ significantly from the fine-tuned source language. This paper introduces AlignFreeze, a method that freezes either the layers' lower half or upper half during realignment. Through controlled experiments on 4 tasks, 3 models, and in 35 languages, we find that realignment affects all the layers but can be the most detrimental to the lower ones. Freezing the lower layers can prevent performance degradation. Particularly, AlignFreeze improves Part-of-Speech (PoS) tagging performances in languages where full realignment fails: with XLM-R, it provides improvements of more than one standard deviation in accuracy in seven more languages than full realignment.
Multilingual Clinical NER: Translation or Cross-lingual Transfer?
Jun 07, 2023



Natural language tasks like Named Entity Recognition (NER) in the clinical domain on non-English texts can be very time-consuming and expensive due to the lack of annotated data. Cross-lingual transfer (CLT) is a way to circumvent this issue thanks to the ability of multilingual large language models to be fine-tuned on a specific task in one language and to provide high accuracy for the same task in another language. However, other methods leveraging translation models can be used to perform NER without annotated data in the target language, by either translating the training set or test set. This paper compares cross-lingual transfer with these two alternative methods, to perform clinical NER in French and in German without any training data in those languages. To this end, we release MedNERF a medical NER test set extracted from French drug prescriptions and annotated with the same guidelines as an English dataset. Through extensive experiments on this dataset and on a German medical dataset (Frei and Kramer, 2021), we show that translation-based methods can achieve similar performance to CLT but require more care in their design. And while they can take advantage of monolingual clinical language models, those do not guarantee better results than large general-purpose multilingual models, whether with cross-lingual transfer or translation.
Exploring the Relationship between Alignment and Cross-lingual Transfer in Multilingual Transformers
Jun 05, 2023



Without any explicit cross-lingual training data, multilingual language models can achieve cross-lingual transfer. One common way to improve this transfer is to perform realignment steps before fine-tuning, i.e., to train the model to build similar representations for pairs of words from translated sentences. But such realignment methods were found to not always improve results across languages and tasks, which raises the question of whether aligned representations are truly beneficial for cross-lingual transfer. We provide evidence that alignment is actually significantly correlated with cross-lingual transfer across languages, models and random seeds. We show that fine-tuning can have a significant impact on alignment, depending mainly on the downstream task and the model. Finally, we show that realignment can, in some instances, improve cross-lingual transfer, and we identify conditions in which realignment methods provide significant improvements. Namely, we find that realignment works better on tasks for which alignment is correlated with cross-lingual transfer when generalizing to a distant language and with smaller models, as well as when using a bilingual dictionary rather than FastAlign to extract realignment pairs. For example, for POS-tagging, between English and Arabic, realignment can bring a +15.8 accuracy improvement on distilmBERT, even outperforming XLM-R Large by 1.7. We thus advocate for further research on realignment methods for smaller multilingual models as an alternative to scaling.
Multilingual Transformer Encoders: a Word-Level Task-Agnostic Evaluation
Jul 19, 2022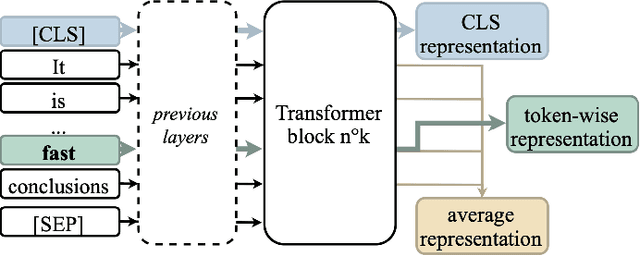
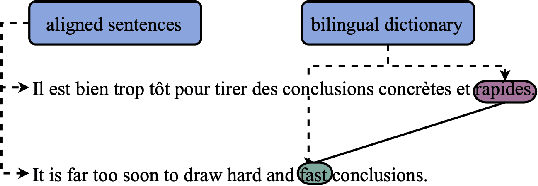

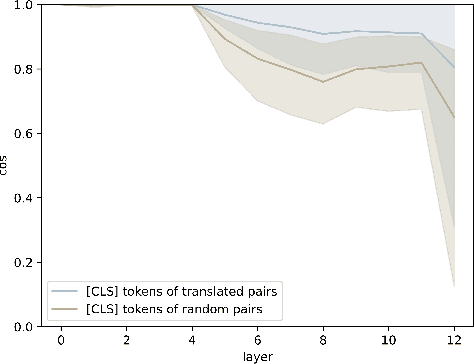
Some Transformer-based models can perform cross-lingual transfer learning: those models can be trained on a specific task in one language and give relatively good results on the same task in another language, despite having been pre-trained on monolingual tasks only. But, there is no consensus yet on whether those transformer-based models learn universal patterns across languages. We propose a word-level task-agnostic method to evaluate the alignment of contextualized representations built by such models. We show that our method provides more accurate translated word pairs than previous methods to evaluate word-level alignment. And our results show that some inner layers of multilingual Transformer-based models outperform other explicitly aligned representations, and even more so according to a stricter definition of multilingual alignment.