 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Clinical NER: Translation or Cross-lingual Transfer?
Jun 07, 2023



Natural language tasks like Named Entity Recognition (NER) in the clinical domain on non-English texts can be very time-consuming and expensive due to the lack of annotated data. Cross-lingual transfer (CLT) is a way to circumvent this issue thanks to the ability of multilingual large language models to be fine-tuned on a specific task in one language and to provide high accuracy for the same task in another language. However, other methods leveraging translation models can be used to perform NER without annotated data in the target language, by either translating the training set or test set. This paper compares cross-lingual transfer with these two alternative methods, to perform clinical NER in French and in German without any training data in those languages. To this end, we release MedNERF a medical NER test set extracted from French drug prescriptions and annotated with the same guidelines as an English dataset. Through extensive experiments on this dataset and on a German medical dataset (Frei and Kramer, 2021), we show that translation-based methods can achieve similar performance to CLT but require more care in their design. And while they can take advantage of monolingual clinical language models, those do not guarantee better results than large general-purpose multilingual models, whether with cross-lingual transfer or translation.
Exploring the Relationship between Alignment and Cross-lingual Transfer in Multilingual Transformers
Jun 05, 2023



Without any explicit cross-lingual training data, multilingual language models can achieve cross-lingual transfer. One common way to improve this transfer is to perform realignment steps before fine-tuning, i.e., to train the model to build similar representations for pairs of words from translated sentences. But such realignment methods were found to not always improve results across languages and tasks, which raises the question of whether aligned representations are truly beneficial for cross-lingual transfer. We provide evidence that alignment is actually significantly correlated with cross-lingual transfer across languages, models and random seeds. We show that fine-tuning can have a significant impact on alignment, depending mainly on the downstream task and the model. Finally, we show that realignment can, in some instances, improve cross-lingual transfer, and we identify conditions in which realignment methods provide significant improvements. Namely, we find that realignment works better on tasks for which alignment is correlated with cross-lingual transfer when generalizing to a distant language and with smaller models, as well as when using a bilingual dictionary rather than FastAlign to extract realignment pairs. For example, for POS-tagging, between English and Arabic, realignment can bring a +15.8 accuracy improvement on distilmBERT, even outperforming XLM-R Large by 1.7. We thus advocate for further research on realignment methods for smaller multilingual models as an alternative to scaling.
Multilingual Transformer Encoders: a Word-Level Task-Agnostic Evaluation
Jul 19, 2022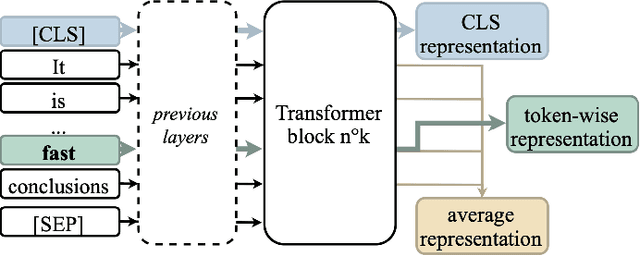
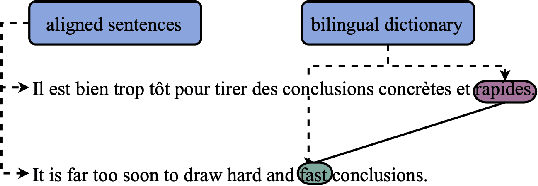

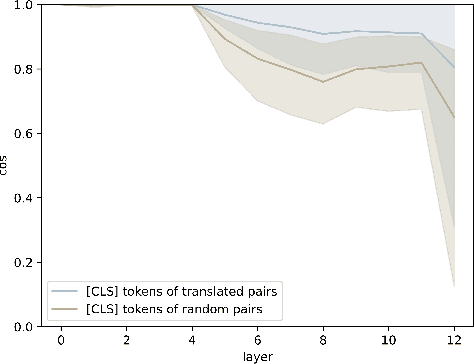
Some Transformer-based models can perform cross-lingual transfer learning: those models can be trained on a specific task in one language and give relatively good results on the same task in another language, despite having been pre-trained on monolingual tasks only. But, there is no consensus yet on whether those transformer-based models learn universal patterns across languages. We propose a word-level task-agnostic method to evaluate the alignment of contextualized representations built by such models. We show that our method provides more accurate translated word pairs than previous methods to evaluate word-level alignment. And our results show that some inner layers of multilingual Transformer-based models outperform other explicitly aligned representations, and even more so according to a stricter definition of multilingual alignment.
Experiments on transfer learning architectures for biomedical relation extraction
Nov 24, 2020
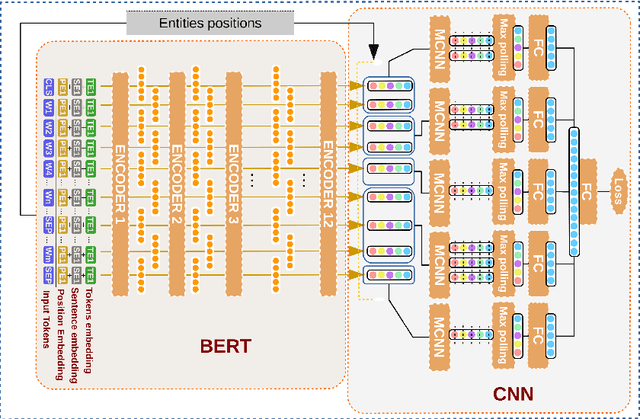
Relation extraction (RE) consists in identifying and structuring automatically relations of interest from texts. Recently, BERT improved the top performances for several NLP tasks, including RE. However, the best way to use BERT, within a machine learning architecture, and within a transfer learning strategy is still an open question since it is highly dependent on each specific task and domain. Here, we explore various BERT-based architectures and transfer learning strategies (i.e., frozen or fine-tuned) for the task of biomedical RE on two corpora. Among tested architectures and strategies, our *BERT-segMCNN with finetuning reaches performances higher than the state-of-the-art on the two corpora (1.73 % and 32.77 % absolute improvement on ChemProt and PGxCorpus corpora respectively). More generally, our experiments illustrate the expected interest of fine-tuning with BERT, but also the unexplored advantage of using structural information (with sentence segmentation), in addition to the context classically leveraged by BERT.
Mining for adverse drug events with formal concept analysis
Jan 26, 2009
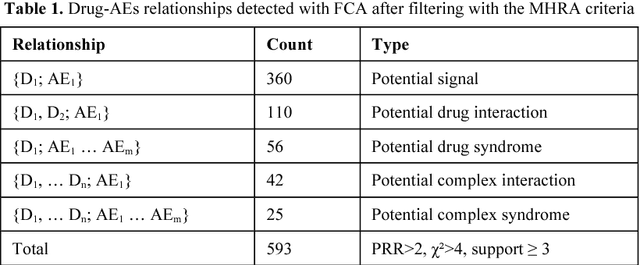


The pharmacovigilance databases consist of several case reports involving drugs and adverse events (AEs). Some methods are applied consistently to highlight all signals, i.e. all statistically significant associations between a drug and an AE. These methods are appropriate for verification of more complex relationships involving one or several drug(s) and AE(s) (e.g; syndromes or interactions) but do not address the identification of them. We propose a method for the extraction of these relationships based on Formal Concept Analysis (FCA) associated with disproportionality measures. This method identifies all sets of drugs and AEs which are potential signals, syndromes or interactions. Compared to a previous experience of disproportionality analysis without FCA, the addition of FCA was more efficient for identifying false positives related to concomitant drugs.
Hiérarchisation des règles d'association en fouille de textes
Oct 14, 2005



Extraction of association rules is widely used as a data mining method. However, one of the limit of this approach comes from the large number of extracted rules and the difficulty for a human expert to deal with the totality of these rules. We propose to solve this problem by structuring the set of rules into hierarchy. The expert can then therefore explore the rules, access from one rule to another one more general when we raise up in the hierarchy, and in other hand, or a more specific rules. Rules are structured at two levels. The global level aims at building a hierarchy from the set of rules extracted. Thus we define a first type of rule-subsomption relying on Galois lattices. The second level consists in a local and more detailed analysis of each rule. It generate for a given rule a set of generalization rules structured into a local hierarchy. This leads to the definition of a second type of subsomption. This subsomption comes from inductive logic programming and integrates a terminological model.