 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Attention with Global Context: A Multipole Attention Mechanism for Vision and Physics
Jul 03, 2025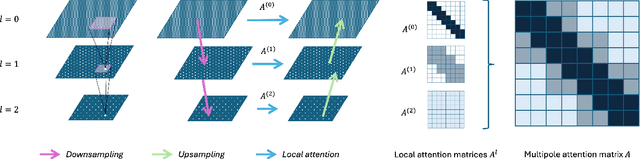


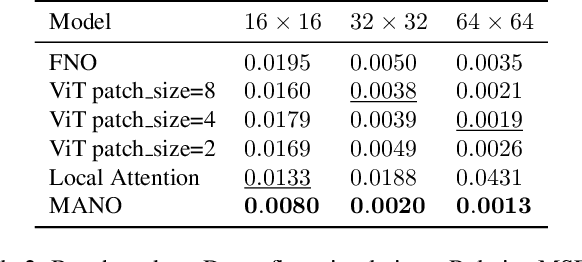
Transformers have become the de facto standard for a wide range of tasks, from image classification to physics simulations. Despite their impressive performance, the quadratic complexity of standard Transformers in both memory and time with respect to the input length makes them impractical for processing high-resolution inputs. Therefore, several variants have been proposed, the most successful relying on patchification, downsampling, or coarsening techniques, often at the cost of losing the finest-scale details. In this work, we take a different approach. Inspired by state-of-the-art techniques in $n$-body numerical simulations, we cast attention as an interaction problem between grid points. We introduce the Multipole Attention Neural Operator (MANO), which computes attention in a distance-based multiscale fashion. MANO maintains, in each attention head, a global receptive field and achieves linear time and memory complexity with respect to the number of grid points. Empirical results on image classification and Darcy flows demonstrate that MANO rivals state-of-the-art models such as ViT and Swin Transformer, while reducing runtime and peak memory usage by orders of magnitude. We open source our code for reproducibility at https://github.com/AlexColagrande/MANO.
Recommendation of data-free class-incremental learning algorithms by simulating future data
Mar 26, 2024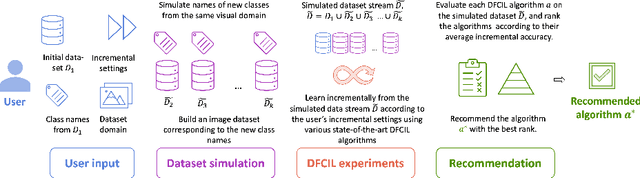
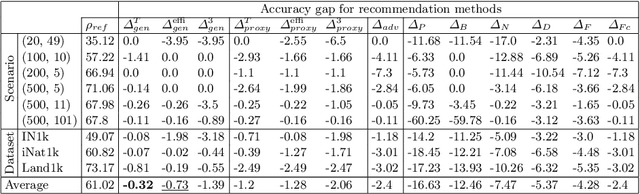


Class-incremental learning deals with sequential data streams composed of batches of classes. Various algorithms have been proposed to address the challenging case where samples from past classes cannot be stored. However, selecting an appropriate algorithm for a user-defined setting is an open problem, as the relative performance of these algorithms depends on the incremental settings. To solve this problem, we introduce an algorithm recommendation method that simulates the future data stream. Given an initial set of classes, it leverages generative models to simulate future classes from the same visual domain. We evaluate recent algorithms on the simulated stream and recommend the one which performs best in the user-defined incremental setting. We illustrate the effectiveness of our method on three large datasets using six algorithms and six incremental settings. Our method outperforms competitive baselines, and performance is close to that of an oracle choosing the best algorithm in each setting. This work contributes to facilitate the practical deployment of incremental learning.
An Analysis of Initial Training Strategies for Exemplar-Free Class-Incremental Learning
Aug 22, 2023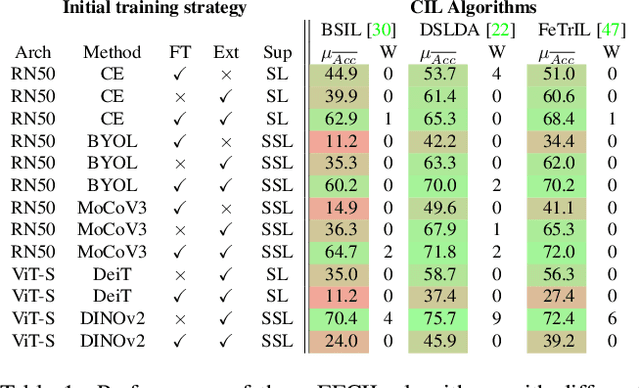
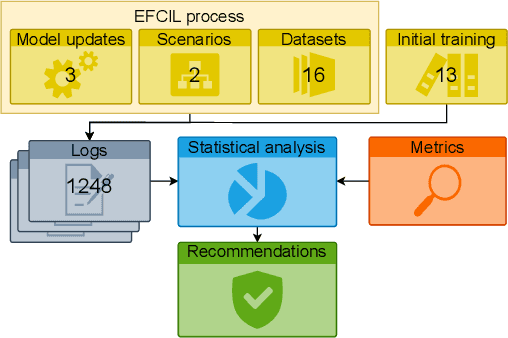

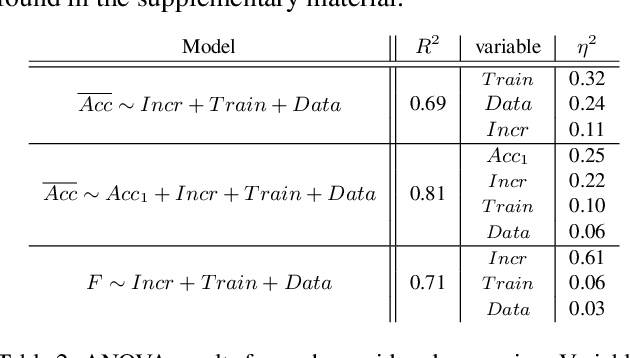
Class-Incremental Learning (CIL) aims to build classification models from data streams. At each step of the CIL process, new classes must be integrated into the model. Due to catastrophic forgetting, CIL is particularly challenging when examples from past classes cannot be stored, the case on which we focus here. To date, most approaches are based exclusively on the target dataset of the CIL process. However, the use of models pre-trained in a self-supervised way on large amounts of data has recently gained momentum. The initial model of the CIL process may only use the first batch of the target dataset, or also use pre-trained weights obtained on an auxiliary dataset. The choice between these two initial learning strategies can significantly influence the performance of the incremental learning model, but has not yet been studied in depth. Performance is also influenced by the choice of the CIL algorithm, the neural architecture, the nature of the target task, the distribution of classes in the stream and the number of examples available for learning. We conduct a comprehensive experimental study to assess the roles of these factors. We present a statistical analysis framework that quantifies the relative contribution of each factor to incremental performance. Our main finding is that the initial training strategy is the dominant factor influencing the average incremental accuracy, but that the choice of CIL algorithm is more important in preventing forgetting. Based on this analysis, we propose practical recommendations for choosing the right initial training strategy for a given incremental learning use case. These recommendations are intended to facilitate the practical deployment of incremental learning.