 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Triangulation for Deep Learning-based 3D Reconstruction of Objects of Arbitrary Topology from Single RGB Images
Paper and Code
Sep 24, 2021
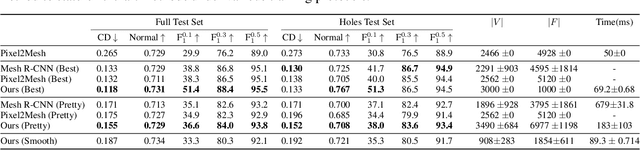
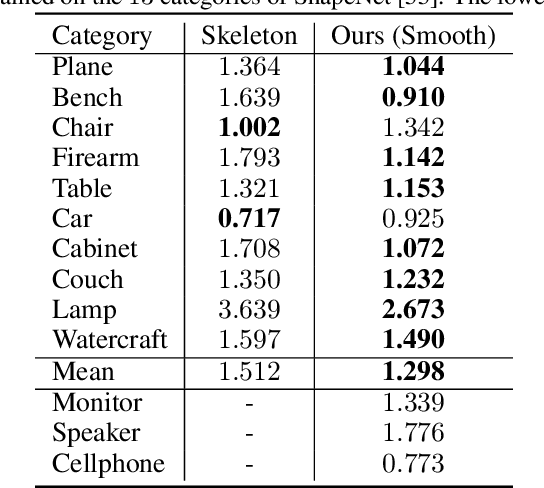

We propose a novel deep reinforcement learning-based approach for 3D object reconstruction from monocular images. Prior works that use mesh representations are template based. Thus, they are limited to the reconstruction of objects that have the same topology as the template. Methods that use volumetric grids as intermediate representations are computationally expensive, which limits their application in real-time scenarios. In this paper, we propose a novel end-to-end method that reconstructs 3D objects of arbitrary topology from a monocular image. It is composed of of (1) a Vertex Generation Network (VGN), which predicts the initial 3D locations of the object's vertices from an input RGB image, (2) a differentiable triangulation layer, which learns in a non-supervised manner, using a novel reinforcement learning algorithm, the best triangulation of the object's vertices, and finally, (3) a hierarchical mesh refinement network that uses graph convolutions to refine the initial mesh. Our key contribution is the learnable triangulation process, which recovers in an unsupervised manner the topology of the input shape. Our experiments on ShapeNet and Pix3D benchmarks show that the proposed method outperforms the state-of-the-art in terms of visual quality, reconstruction accuracy, and computational time.