 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Automation of Neural Network Design: A Survey on Differentiable Neural Architecture Search
May 01, 2023



In the past few years, Differentiable Neural Architecture Search (DNAS) rapidly imposed itself as the trending approach to automate the discovery of deep neural network architectures. This rise is mainly due to the popularity of DARTS, one of the first major DNAS methods. In contrast with previous works based on Reinforcement Learning or Evolutionary Algorithms, DNAS is faster by several orders of magnitude and uses fewer computational resources. In this comprehensive survey, we focus specifically on DNAS and review recent approaches in this field. Furthermore, we propose a novel challenge-based taxonomy to classify DNAS methods. We also discuss the contributions brought to DNAS in the past few years and its impact on the global NAS field. Finally, we conclude by giving some insights into future research directions for the DNAS field.
NASiam: Efficient Representation Learning using Neural Architecture Search for Siamese Networks
Jan 31, 2023



Siamese networks are one of the most trending methods to achieve self-supervised visual representation learning (SSL). Since hand labeling is costly, SSL can play a crucial part by allowing deep learning to train on large unlabeled datasets. Meanwhile, Neural Architecture Search (NAS) is becoming increasingly important as a technique to discover novel deep learning architectures. However, early NAS methods based on reinforcement learning or evolutionary algorithms suffered from ludicrous computational and memory costs. In contrast, differentiable NAS, a gradient-based approach, has the advantage of being much more efficient and has thus retained most of the attention in the past few years. In this article, we present NASiam, a novel approach that uses for the first time differentiable NAS to improve the multilayer perceptron projector and predictor (encoder/predictor pair) architectures inside siamese-networks-based contrastive learning frameworks (e.g., SimCLR, SimSiam, and MoCo) while preserving the simplicity of previous baselines. We crafted a search space designed explicitly for multilayer perceptrons, inside which we explored several alternatives to the standard ReLU activation function. We show that these new architectures allow ResNet backbone convolutional models to learn strong representations efficiently. NASiam reaches competitive performance in both small-scale (i.e., CIFAR-10/CIFAR-100) and large-scale (i.e., ImageNet) image classification datasets while costing only a few GPU hours. We discuss the composition of the NAS-discovered architectures and emit hypotheses on why they manage to prevent collapsing behavior. Our code is available at https://github.com/aheuillet/NASiam.
D-DARTS: Distributed Differentiable Architecture Search
Aug 20, 2021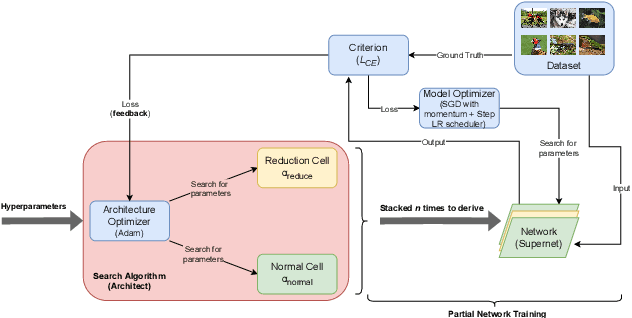
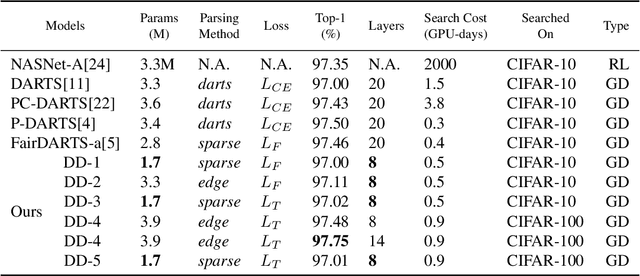
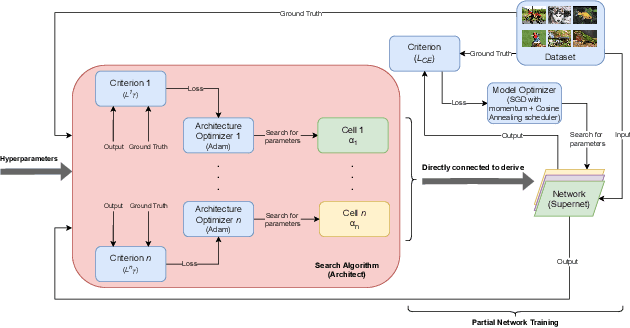
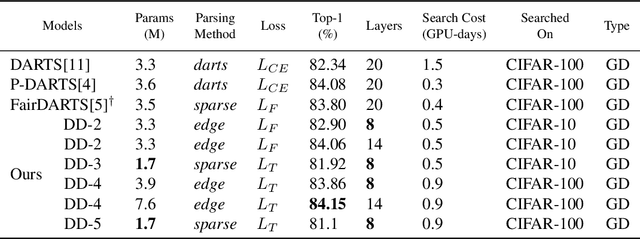
Differentiable ARchiTecture Search (DARTS) is one of the most trending Neural Architecture Search (NAS) methods, drastically reducing search cost by resorting to Stochastic Gradient Descent (SGD) and weight-sharing. However, it also greatly reduces the search space, thus excluding potential promising architectures from being discovered. In this paper, we propose D-DARTS, a novel solution that addresses this problem by nesting several neural networks at cell-level instead of using weight-sharing to produce more diversified and specialized architectures. Moreover, we introduce a novel algorithm which can derive deeper architectures from a few trained cells, increasing performance and saving computation time. Our solution is able to provide state-of-the-art results on CIFAR-10, CIFAR-100 and ImageNet while using significantly less parameters than previous baselines, resulting in more hardware-efficient neural networks.