 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenge design roadmap
Jan 15, 2024Challenges can be seen as a type of game that motivates participants to solve serious tasks. As a result, competition organizers must develop effective game rules. However, these rules have multiple objectives beyond making the game enjoyable for participants. These objectives may include solving real-world problems, advancing scientific or technical areas, making scientific discoveries, and educating the public. In many ways, creating a challenge is similar to launching a product. It requires the same level of excitement and rigorous testing, and the goal is to attract ''customers'' in the form of participants. The process begins with a solid plan, such as a competition proposal that will eventually be submitted to an international conference and subjected to peer review. Although peer review does not guarantee quality, it does force organizers to consider the impact of their challenge, identify potential oversights, and generally improve its quality. This chapter provides guidelines for creating a strong plan for a challenge. The material draws on the preparation guidelines from organizations such as Kaggle 1 , ChaLearn 2 and Tailor 3 , as well as the NeurIPS proposal template, which some of the authors contributed to.
Advances in MetaDL: AAAI 2021 challenge and workshop
Feb 01, 2022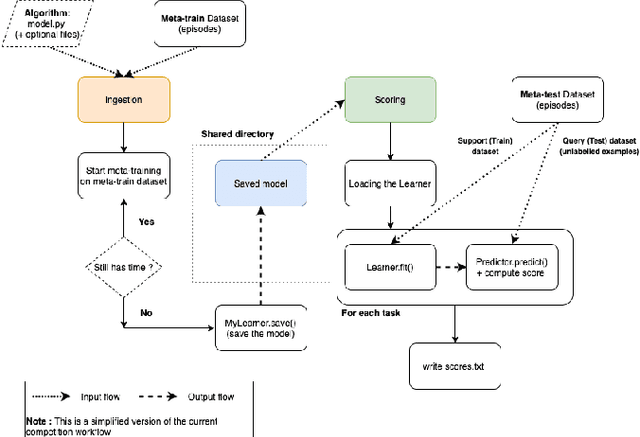


To stimulate advances in metalearning using deep learning techniques (MetaDL), we organized in 2021 a challenge and an associated workshop. This paper presents the design of the challenge and its results, and summarizes presentations made at the workshop. The challenge focused on few-shot learning classification tasks of small images. Participants' code submissions were run in a uniform manner, under tight computational constraints. This put pressure on solution designs to use existing architecture backbones and/or pre-trained networks. Winning methods featured various classifiers trained on top of the second last layer of popular CNN backbones, fined-tuned on the meta-training data (not necessarily in an episodic manner), then trained on the labeled support and tested on the unlabeled query sets of the meta-test data.
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Jan 11, 2022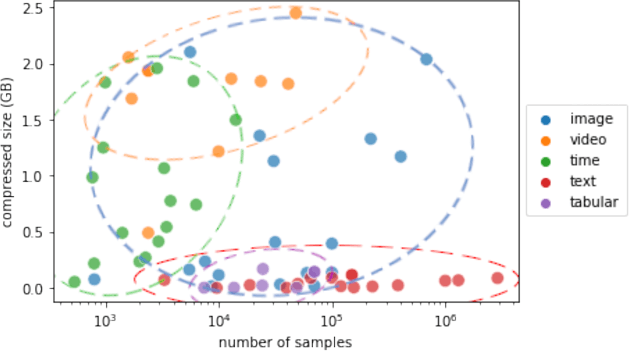
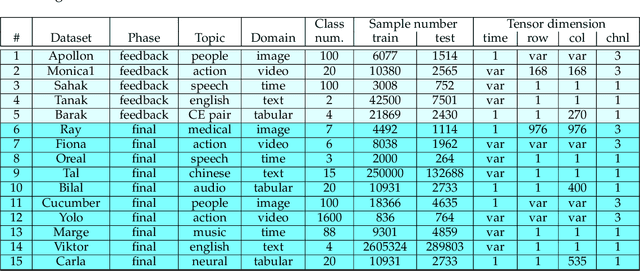
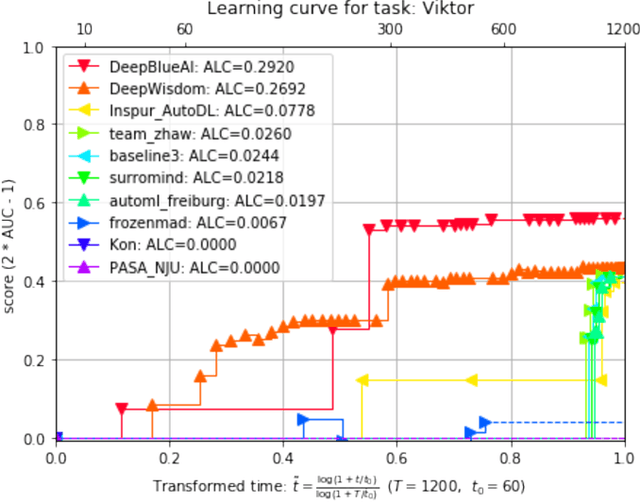
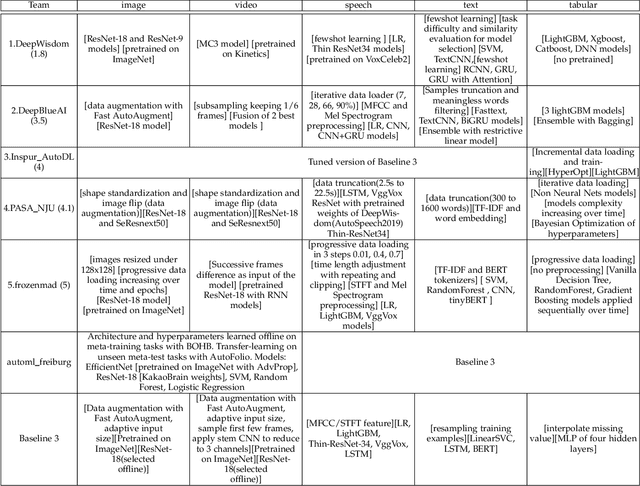
This paper reports the results and post-challenge analyses of ChaLearn's AutoDL challenge series, which helped sorting out a profusion of AutoML solutions for Deep Learning (DL) that had been introduced in a variety of settings, but lacked fair comparisons. All input data modalities (time series, images, videos, text, tabular) were formatted as tensors and all tasks were multi-label classification problems. Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly. In this setting, DL methods dominated, though popular Neural Architecture Search (NAS) was impractical. Solutions relied on fine-tuned pre-trained networks, with architectures matching data modality. Post-challenge tests did not reveal improvements beyond the imposed time limit. While no component is particularly original or novel, a high level modular organization emerged featuring a "meta-learner", "data ingestor", "model selector", "model/learner", and "evaluator". This modularity enabled ablation studies, which revealed the importance of (off-platform) meta-learning, ensembling, and efficient data management. Experiments on heterogeneous module combinations further confirm the (local) optimality of the winning solutions. Our challenge legacy includes an ever-lasting benchmark (http://autodl.chalearn.org), the open-sourced code of the winners, and a free "AutoDL self-service".
* The first three authors contributed equally; This is only a draft version