 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Debiasing Large Language Models for Decision-Making
Apr 10, 2025Large language models (LLMs) have shown potential in supporting decision-making applications, particularly as personal conversational assistants in the financial, healthcare, and legal domains. While prompt engineering strategies have enhanced the capabilities of LLMs in decision-making, cognitive biases inherent to LLMs present significant challenges. Cognitive biases are systematic patterns of deviation from norms or rationality in decision-making that can lead to the production of inaccurate outputs. Existing cognitive bias mitigation strategies assume that input prompts contain (exactly) one type of cognitive bias and therefore fail to perform well in realistic settings where there maybe any number of biases. To fill this gap, we propose a cognitive debiasing approach, called self-debiasing, that enhances the reliability of LLMs by iteratively refining prompts. Our method follows three sequential steps -- bias determination, bias analysis, and cognitive debiasing -- to iteratively mitigate potential cognitive biases in prompts. Experimental results on finance, healthcare, and legal decision-making tasks, using both closed-source and open-source LLMs, demonstrate that the proposed self-debiasing method outperforms both advanced prompt engineering methods and existing cognitive debiasing techniques in average accuracy under no-bias, single-bias, and multi-bias settings.
Unsupervised Classification for Polarimetric SAR Data Using Variational Bayesian Wishart Mixture Model with Inverse Gamma-Gamma Prior
Apr 04, 2021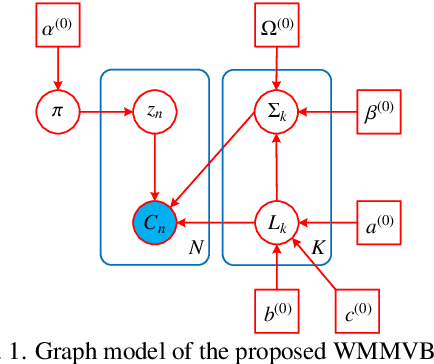
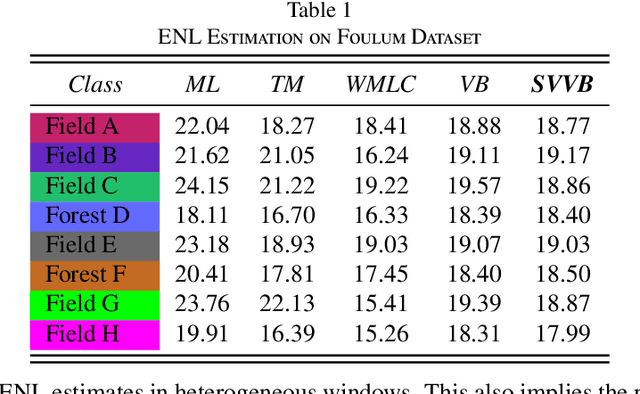
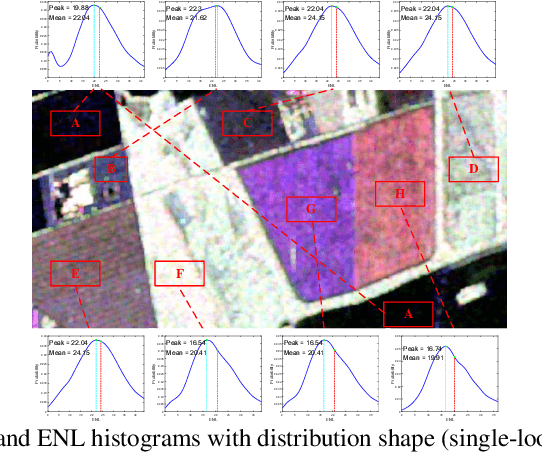
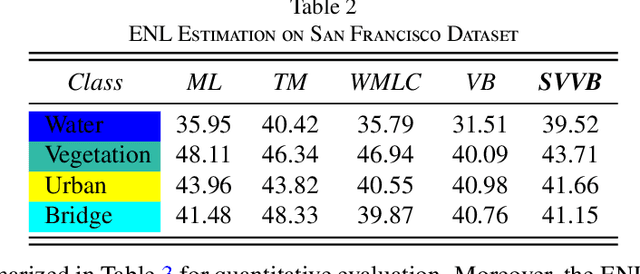
Although various clustering methods have been successfully applied to polarimetric synthetic aperture radar (PolSAR) image clustering tasks, most of the available approaches fail to realize automatic determination of cluster number, nor have they derived an exact distribution for the number of looks. To overcome these limitations and achieve robust unsupervised classification of PolSAR images, this paper proposes the variational Bayesian Wishart mixture model (VBWMM), where variational Bayesian expectation maximization (VBEM) technique is applied to estimate the variational posterior distribution of model parameters iteratively. Besides, covariance matrix similarity and geometric similarity are combined to incorporate spatial information of PolSAR images. Furthermore, we derive a new distribution named inverse gamma-gamma (IGG) prior that originates from the log-likelihood function of proposed model to enable efficient handling of number of looks. As a result, we obtain a closed-form variational lower bound, which can be used to evaluate the convergence of proposed model. We validate the superiority of proposed method in clustering performance on four real-measured datasets and demonstrate significant improvements towards conventional methods. As a by-product, the experiments show that our proposed IGG prior is effective in estimating the number of looks.