 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOintGS: Joint Optimization of Cameras, Bodies and 3D Gaussians for In-the-Wild Monocular Reconstruction
Feb 04, 2026Reconstructing high-fidelity animatable 3D human avatars from monocular RGB videos remains challenging, particularly in unconstrained in-the-wild scenarios where camera parameters and human poses from off-the-shelf methods (e.g., COLMAP, HMR2.0) are often inaccurate. Splatting (3DGS) advances demonstrate impressive rendering quality and real-time performance, they critically depend on precise camera calibration and pose annotations, limiting their applicability in real-world settings. We present JOintGS, a unified framework that jointly optimizes camera extrinsics, human poses, and 3D Gaussian representations from coarse initialization through a synergistic refinement mechanism. Our key insight is that explicit foreground-background disentanglement enables mutual reinforcement: static background Gaussians anchor camera estimation via multi-view consistency; refined cameras improve human body alignment through accurate temporal correspondence; optimized human poses enhance scene reconstruction by removing dynamic artifacts from static constraints. We further introduce a temporal dynamics module to capture fine-grained pose-dependent deformations and a residual color field to model illumination variations. Extensive experiments on NeuMan and EMDB datasets demonstrate that JOintGS achieves superior reconstruction quality, with 2.1~dB PSNR improvement over state-of-the-art methods on NeuMan dataset, while maintaining real-time rendering. Notably, our method shows significantly enhanced robustness to noisy initialization compared to the baseline.Our source code is available at https://github.com/MiliLab/JOintGS.
InpaintHuman: Reconstructing Occluded Humans with Multi-Scale UV Mapping and Identity-Preserving Diffusion Inpainting
Jan 05, 2026Reconstructing complete and animatable 3D human avatars from monocular videos remains challenging, particularly under severe occlusions. While 3D Gaussian Splatting has enabled photorealistic human rendering, existing methods struggle with incomplete observations, often producing corrupted geometry and temporal inconsistencies. We present InpaintHuman, a novel method for generating high-fidelity, complete, and animatable avatars from occluded monocular videos. Our approach introduces two key innovations: (i) a multi-scale UV-parameterized representation with hierarchical coarse-to-fine feature interpolation, enabling robust reconstruction of occluded regions while preserving geometric details; and (ii) an identity-preserving diffusion inpainting module that integrates textual inversion with semantic-conditioned guidance for subject-specific, temporally coherent completion. Unlike SDS-based methods, our approach employs direct pixel-level supervision to ensure identity fidelity. Experiments on synthetic benchmarks (PeopleSnapshot, ZJU-MoCap) and real-world scenarios (OcMotion) demonstrate competitive performance with consistent improvements in reconstruction quality across diverse poses and viewpoints.
FMGS-Avatar: Mesh-Guided 2D Gaussian Splatting with Foundation Model Priors for 3D Monocular Avatar Reconstruction
Sep 18, 2025Reconstructing high-fidelity animatable human avatars from monocular videos remains challenging due to insufficient geometric information in single-view observations. While recent 3D Gaussian Splatting methods have shown promise, they struggle with surface detail preservation due to the free-form nature of 3D Gaussian primitives. To address both the representation limitations and information scarcity, we propose a novel method, \textbf{FMGS-Avatar}, that integrates two key innovations. First, we introduce Mesh-Guided 2D Gaussian Splatting, where 2D Gaussian primitives are attached directly to template mesh faces with constrained position, rotation, and movement, enabling superior surface alignment and geometric detail preservation. Second, we leverage foundation models trained on large-scale datasets, such as Sapiens, to complement the limited visual cues from monocular videos. However, when distilling multi-modal prior knowledge from foundation models, conflicting optimization objectives can emerge as different modalities exhibit distinct parameter sensitivities. We address this through a coordinated training strategy with selective gradient isolation, enabling each loss component to optimize its relevant parameters without interference. Through this combination of enhanced representation and coordinated information distillation, our approach significantly advances 3D monocular human avatar reconstruction. Experimental evaluation demonstrates superior reconstruction quality compared to existing methods, with notable gains in geometric accuracy and appearance fidelity while providing rich semantic information. Additionally, the distilled prior knowledge within a shared canonical space naturally enables spatially and temporally consistent rendering under novel views and poses.
Advances in Radiance Field for Dynamic Scene: From Neural Field to Gaussian Field
May 15, 2025Dynamic scene representation and reconstruction have undergone transformative advances in recent years, catalyzed by breakthroughs in neural radiance fields and 3D Gaussian splatting techniques. While initially developed for static environments, these methodologies have rapidly evolved to address the complexities inherent in 4D dynamic scenes through an expansive body of research. Coupled with innovations in differentiable volumetric rendering, these approaches have significantly enhanced the quality of motion representation and dynamic scene reconstruction, thereby garnering substantial attention from the computer vision and graphics communities. This survey presents a systematic analysis of over 200 papers focused on dynamic scene representation using radiance field, spanning the spectrum from implicit neural representations to explicit Gaussian primitives. We categorize and evaluate these works through multiple critical lenses: motion representation paradigms, reconstruction techniques for varied scene dynamics, auxiliary information integration strategies, and regularization approaches that ensure temporal consistency and physical plausibility. We organize diverse methodological approaches under a unified representational framework, concluding with a critical examination of persistent challenges and promising research directions. By providing this comprehensive overview, we aim to establish a definitive reference for researchers entering this rapidly evolving field while offering experienced practitioners a systematic understanding of both conceptual principles and practical frontiers in dynamic scene reconstruction.
GP-GS: Gaussian Processes for Enhanced Gaussian Splatting
Feb 05, 2025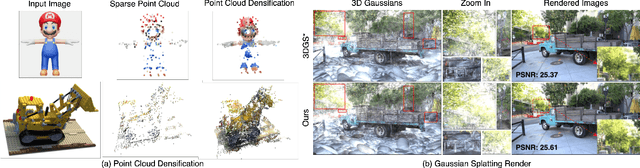
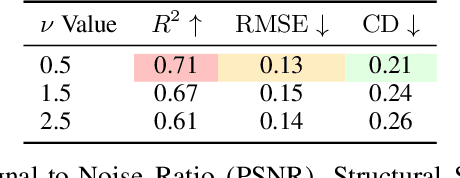
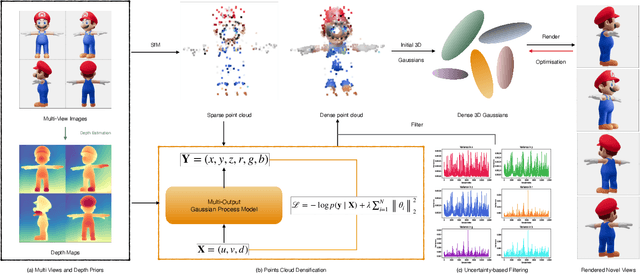
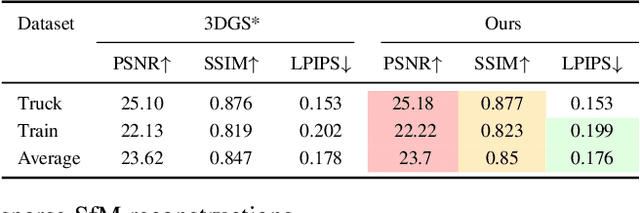
3D Gaussian Splatting has emerged as an efficient photorealistic novel view synthesis method. However, its reliance on sparse Structure-from-Motion (SfM) point clouds consistently compromises the scene reconstruction quality. To address these limitations, this paper proposes a novel 3D reconstruction framework Gaussian Processes Gaussian Splatting (GP-GS), where a multi-output Gaussian Process model is developed to achieve adaptive and uncertainty-guided densification of sparse SfM point clouds. Specifically, we propose a dynamic sampling and filtering pipeline that adaptively expands the SfM point clouds by leveraging GP-based predictions to infer new candidate points from the input 2D pixels and depth maps. The pipeline utilizes uncertainty estimates to guide the pruning of high-variance predictions, ensuring geometric consistency and enabling the generation of dense point clouds. The densified point clouds provide high-quality initial 3D Gaussians to enhance reconstruction performance. Extensive experiments conducted on synthetic and real-world datasets across various scales validate the effectiveness and practicality of the proposed framework.
UVA: Towards Unified Volumetric Avatar for View Synthesis, Pose rendering, Geometry and Texture Editing
Apr 14, 2023Neural radiance field (NeRF) has become a popular 3D representation method for human avatar reconstruction due to its high-quality rendering capabilities, e.g., regarding novel views and poses. However, previous methods for editing the geometry and appearance of the avatar only allow for global editing through body shape parameters and 2D texture maps. In this paper, we propose a new approach named \textbf{U}nified \textbf{V}olumetric \textbf{A}vatar (\textbf{UVA}) that enables local and independent editing of both geometry and texture, while retaining the ability to render novel views and poses. UVA transforms each observation point to a canonical space using a skinning motion field and represents geometry and texture in separate neural fields. Each field is composed of a set of structured latent codes that are attached to anchor nodes on a deformable mesh in canonical space and diffused into the entire space via interpolation, allowing for local editing. To address spatial ambiguity in code interpolation, we use a local signed height indicator. We also replace the view-dependent radiance color with a pose-dependent shading factor to better represent surface illumination in different poses. Experiments on multiple human avatars demonstrate that our UVA achieves competitive results in novel view synthesis and novel pose rendering while enabling local and independent editing of geometry and appearance. The source code will be released.
AniPixel: Towards Animatable Pixel-Aligned Human Avatar
Feb 07, 2023Neural radiance field using pixel-aligned features can render photo-realistic novel views. However, when pixel-aligned features are directly introduced to human avatar reconstruction, the rendering can only be conducted for still humans, rather than animatable avatars. In this paper, we propose AniPixel, a novel animatable and generalizable human avatar reconstruction method that leverages pixel-aligned features for body geometry prediction and RGB color blending. Technically, to align the canonical space with the target space and the observation space, we propose a bidirectional neural skinning field based on skeleton-driven deformation to establish the target-to-canonical and canonical-to-observation correspondences. Then, we disentangle the canonical body geometry into a normalized neutral-sized body and a subject-specific residual for better generalizability. As the geometry and appearance are closely related, we introduce pixel-aligned features to facilitate the body geometry prediction and detailed surface normals to reinforce the RGB color blending. Moreover, we devise a pose-dependent and view direction-related shading module to represent the local illumination variance. Experiments show that our AniPixel renders comparable novel views while delivering better novel pose animation results than state-of-the-art methods. The code will be released.
SIR: Self-supervised Image Rectification via Seeing the Same Scene from Multiple Different Lenses
Nov 30, 2020Deep learning has demonstrated its power in image rectification by leveraging the representation capacity of deep neural networks via supervised training based on a large-scale synthetic dataset. However, the model may overfit the synthetic images and generalize not well on real-world fisheye images due to the limited universality of a specific distortion model and the lack of explicitly modeling the distortion and rectification process. In this paper, we propose a novel self-supervised image rectification (SIR) method based on an important insight that the rectified results of distorted images of the same scene from different lens should be the same. Specifically, we devise a new network architecture with a shared encoder and several prediction heads, each of which predicts the distortion parameter of a specific distortion model. We further leverage a differentiable warping module to generate the rectified images and re-distorted images from the distortion parameters and exploit the intra- and inter-model consistency between them during training, thereby leading to a self-supervised learning scheme without the need for ground-truth distortion parameters or normal images. Experiments on synthetic dataset and real-world fisheye images demonstrate that our method achieves comparable or even better performance than the supervised baseline method and representative state-of-the-art methods. Self-supervised learning also improves the universality of distortion models while keeping their self-consistency.