 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Fine-Tuning: Align then Refine
Feb 11, 2023



Fine-tuning large-scale pretrained models has led to tremendous progress in well-studied modalities such as vision and NLP. However, similar gains have not been observed in many other modalities due to a lack of relevant pretrained models. In this work, we propose ORCA, a general cross-modal fine-tuning framework that extends the applicability of a single large-scale pretrained model to diverse modalities. ORCA adapts to a target task via an align-then-refine workflow: given the target input, ORCA first learns an embedding network that aligns the embedded feature distribution with the pretraining modality. The pretrained model is then fine-tuned on the embedded data to exploit the knowledge shared across modalities. Through extensive experiments, we show that ORCA obtains state-of-the-art results on 3 benchmarks containing over 60 datasets from 12 modalities, outperforming a wide range of hand-designed, AutoML, general-purpose, and task-specific methods. We highlight the importance of data alignment via a series of ablation studies and demonstrate ORCA's utility in data-limited regimes.
Federated Hyperparameter Tuning: Challenges, Baselines, and Connections to Weight-Sharing
Jun 08, 2021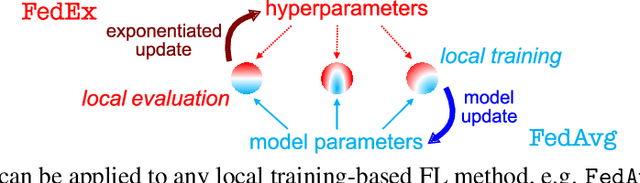
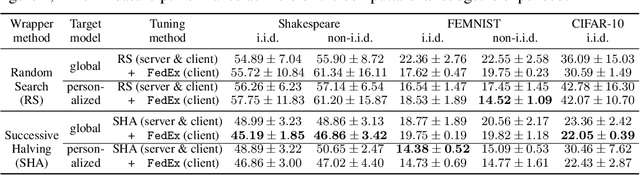
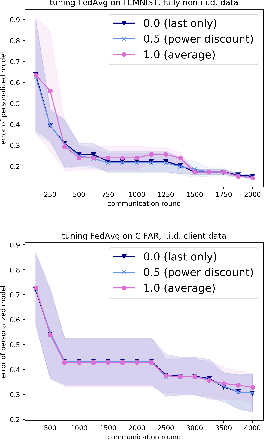

Tuning hyperparameters is a crucial but arduous part of the machine learning pipeline. Hyperparameter optimization is even more challenging in federated learning, where models are learned over a distributed network of heterogeneous devices; here, the need to keep data on device and perform local training makes it difficult to efficiently train and evaluate configurations. In this work, we investigate the problem of federated hyperparameter tuning. We first identify key challenges and show how standard approaches may be adapted to form baselines for the federated setting. Then, by making a novel connection to the neural architecture search technique of weight-sharing, we introduce a new method, FedEx, to accelerate federated hyperparameter tuning that is applicable to widely-used federated optimization methods such as FedAvg and recent variants. Theoretically, we show that a FedEx variant correctly tunes the on-device learning rate in the setting of online convex optimization across devices. Empirically, we show that FedEx can outperform natural baselines for federated hyperparameter tuning by several percentage points on the Shakespeare, FEMNIST, and CIFAR-10 benchmarks, obtaining higher accuracy using the same training budget.
Rethinking Neural Operations for Diverse Tasks
Mar 29, 2021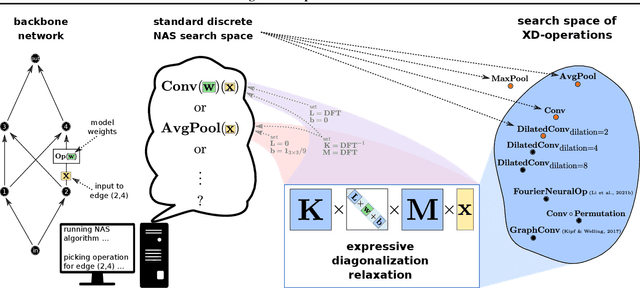

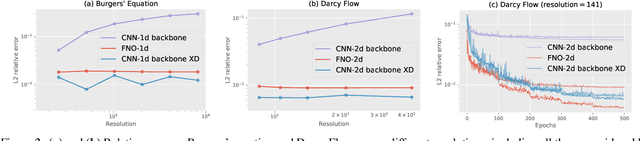

An important goal of neural architecture search (NAS) is to automate-away the design of neural networks on new tasks in under-explored domains. Motivated by this broader vision for NAS, we study the problem of enabling users to discover the right neural operations given data from their specific domain. We introduce a search space of neural operations called XD-Operations that mimic the inductive bias of standard multichannel convolutions while being much more expressive: we prove that XD-operations include many named operations across several application areas. Starting with any standard backbone network such as LeNet or ResNet, we show how to transform it into an architecture search space over XD-operations and how to traverse the space using a simple weight-sharing scheme. On a diverse set of applications--image classification, solving partial differential equations (PDEs), and sequence modeling--our approach consistently yields models with lower error than baseline networks and sometimes even lower error than expert-designed domain-specific approaches.
On Data Efficiency of Meta-learning
Jan 30, 2021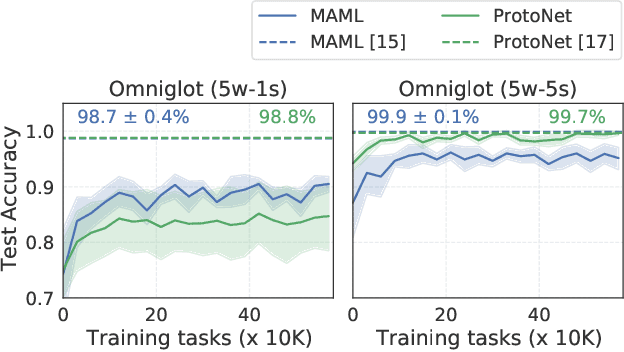
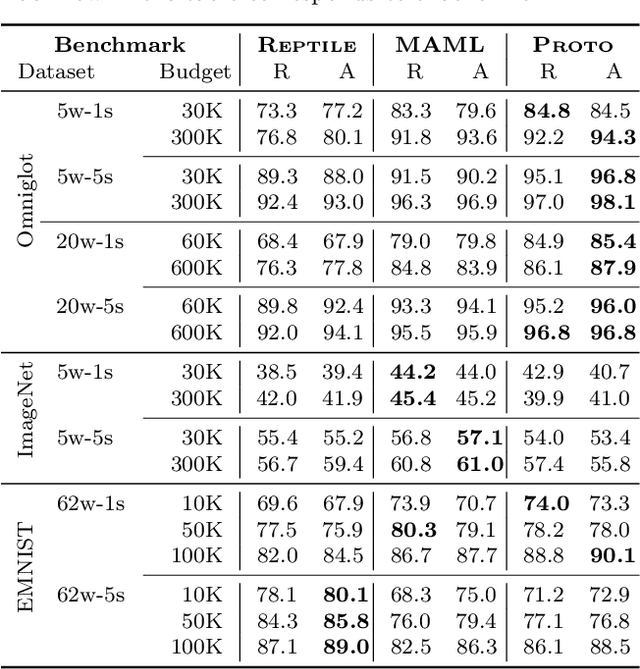

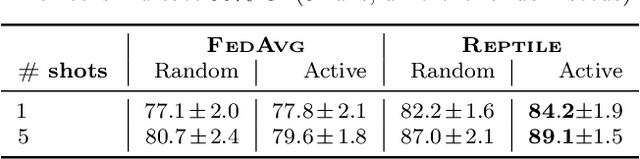
Meta-learning has enabled learning statistical models that can be quickly adapted to new prediction tasks. Motivated by use-cases in personalized federated learning, we study the often overlooked aspect of the modern meta-learning algorithms -- their data efficiency. To shed more light on which methods are more efficient, we use techniques from algorithmic stability to derive bounds on the transfer risk that have important practical implications, indicating how much supervision is needed and how it must be allocated for each method to attain the desired level of generalization. Further, we introduce a new simple framework for evaluating meta-learning methods under a limit on the available supervision, conduct an empirical study of MAML, Reptile, and Protonets, and demonstrate the differences in the behavior of these methods on few-shot and federated learning benchmarks. Finally, we propose active meta-learning, which incorporates active data selection into learning-to-learn, leading to better performance of all methods in the limited supervision regime.
Geometry-Aware Gradient Algorithms for Neural Architecture Search
Apr 16, 2020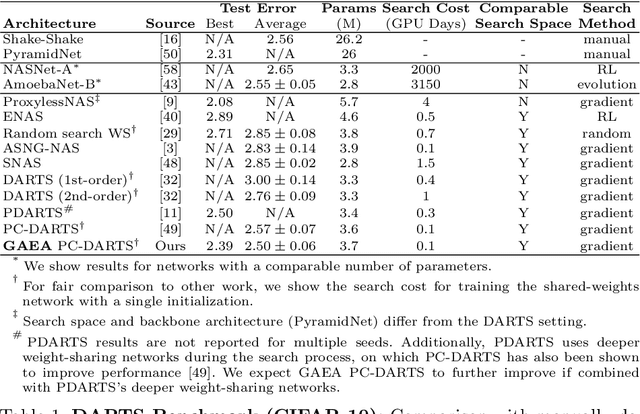

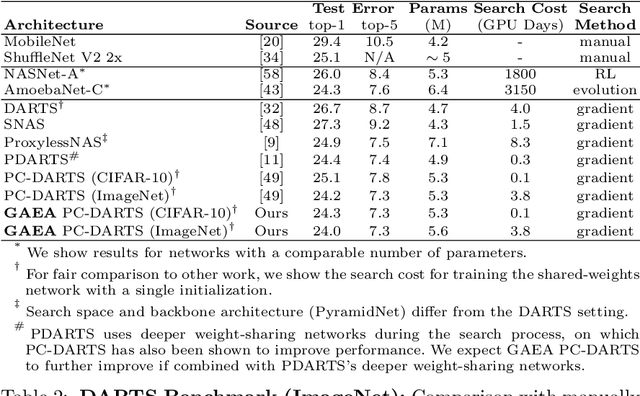

Many recent state-of-the-art methods for neural architecture search (NAS) relax the NAS problem into a joint continuous optimization over architecture parameters and their shared-weights, enabling the application of standard gradient-based optimizers. However, this training process remains poorly understood, as evidenced by the multitude of gradient-based heuristics that have been recently proposed. Invoking the theory of mirror descent, we present a unifying framework for designing and analyzing gradient-based NAS methods that exploit the underlying problem structure to quickly find high-performance architectures. Our geometry-aware framework leads to simple yet novel algorithms that (1) enjoy faster convergence guarantees than existing gradient-based methods and (2) achieve state-of-the-art accuracy on the latest NAS benchmarks in computer vision. Notably, we exceed the best published results for both CIFAR and ImageNet on both the DARTS search space and NAS-Bench-201; on the latter benchmark we achieve close to oracle-optimal performance on CIFAR-10 and CIFAR-100. Together, our theory and experiments demonstrate a principled way to co-design optimizers and continuous parameterizations of discrete NAS search spaces.
Exploiting Reuse in Pipeline-Aware Hyperparameter Tuning
Mar 12, 2019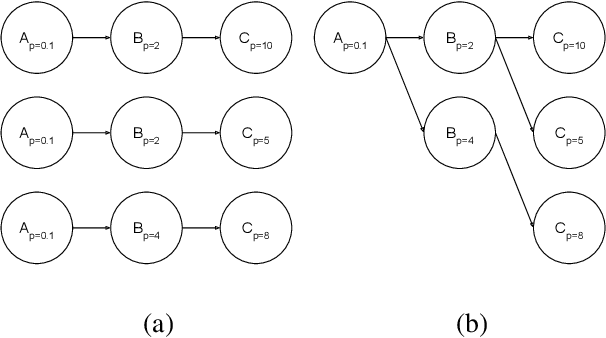
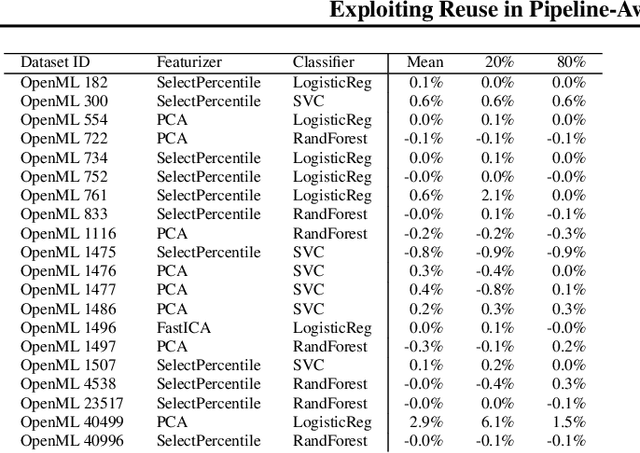
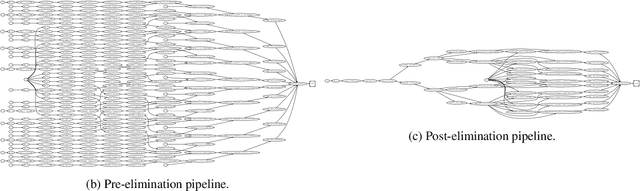
Hyperparameter tuning of multi-stage pipelines introduces a significant computational burden. Motivated by the observation that work can be reused across pipelines if the intermediate computations are the same, we propose a pipeline-aware approach to hyperparameter tuning. Our approach optimizes both the design and execution of pipelines to maximize reuse. We design pipelines amenable for reuse by (i) introducing a novel hybrid hyperparameter tuning method called gridded random search, and (ii) reducing the average training time in pipelines by adapting early-stopping hyperparameter tuning approaches. We then realize the potential for reuse during execution by introducing a novel caching problem for ML workloads which we pose as a mixed integer linear program (ILP), and subsequently evaluating various caching heuristics relative to the optimal solution of the ILP. We conduct experiments on simulated and real-world machine learning pipelines to show that a pipeline-aware approach to hyperparameter tuning can offer over an order-of-magnitude speedup over independently evaluating pipeline configurations.
Random Search and Reproducibility for Neural Architecture Search
Feb 20, 2019
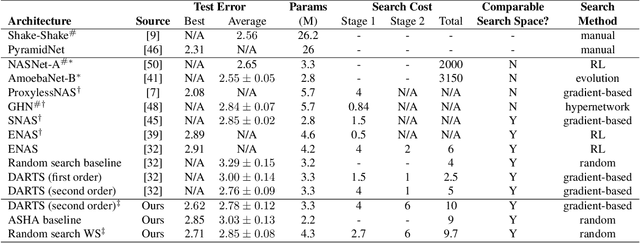
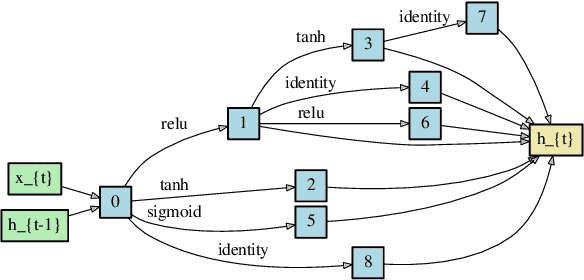

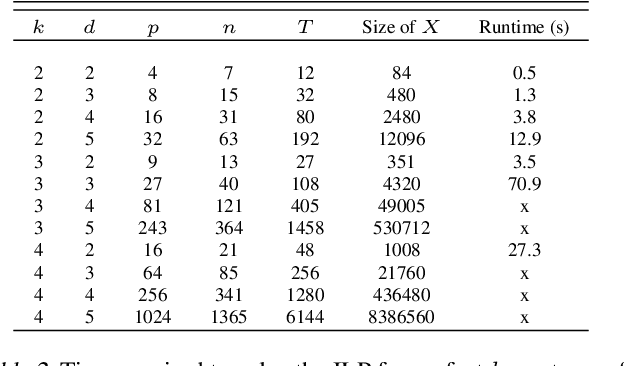
Neural architecture search (NAS) is a promising research direction that has the potential to replace expert-designed networks with learned, task-specific architectures. In this work, in order to help ground the empirical results in this field, we propose new NAS baselines that build off the following observations: (i) NAS is a specialized hyperparameter optimization problem; and (ii) random search is a competitive baseline for hyperparameter optimization. Leveraging these observations, we evaluate both random search with early-stopping and a novel random search with weight-sharing algorithm on two standard NAS benchmarks---PTB and CIFAR-10. Our results show that random search with early-stopping is a competitive NAS baseline, e.g., it performs at least as well as ENAS, a leading NAS method, on both benchmarks. Additionally, random search with weight-sharing outperforms random search with early-stopping, achieving a state-of-the-art NAS result on PTB and a highly competitive result on CIFAR-10. Finally, we explore the existing reproducibility issues of published NAS results. We note the lack of source material needed to exactly reproduce these results, and further discuss the robustness of published results given the various sources of variability in NAS experimental setups. Relatedly, we provide all information (code, random seeds, documentation) needed to exactly reproduce our results, and report our random search with weight-sharing results for each benchmark on two independent experimental runs.
Massively Parallel Hyperparameter Tuning
Oct 17, 2018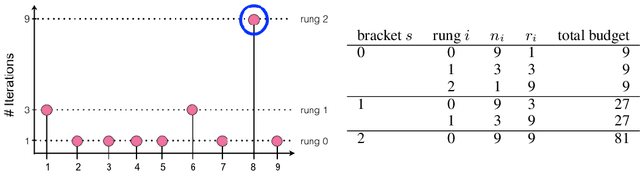

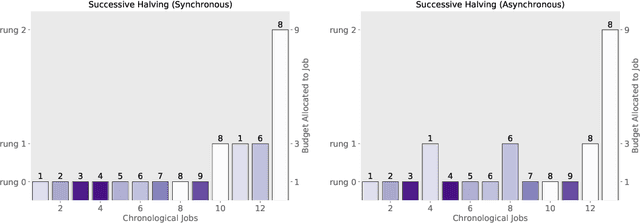
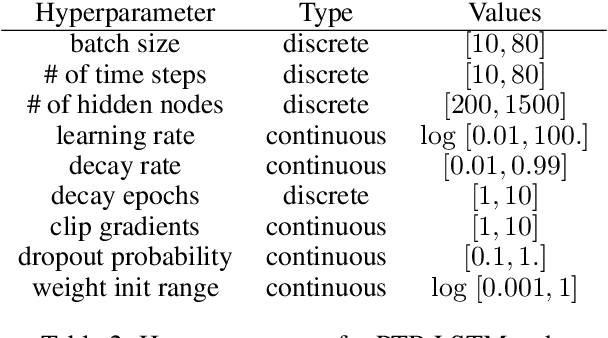
Modern learning models are characterized by large hyperparameter spaces. In order to adequately explore these large spaces, we must evaluate a large number of configurations, typically orders of magnitude more configurations than available parallel workers. Given the growing costs of model training, we would ideally like to perform this search in roughly the same wall-clock time needed to train a single model. In this work, we tackle this challenge by introducing ASHA, a simple and robust hyperparameter tuning algorithm with solid theoretical underpinnings that exploits parallelism and aggressive early-stopping. Our extensive empirical results show that ASHA slightly outperforms Fabolas and Population Based Tuning, state-of-the hyperparameter tuning methods; scales linearly with the number of workers in distributed settings; converges to a high quality configuration in half the time taken by Vizier (Google's internal hyperparameter tuning service) in an experiment with 500 workers; and beats the published result for a near state-of-the-art LSTM architecture in under 2x the time to train a single model.