 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Fine-Tuning: Align then Refine
Feb 11, 2023



Fine-tuning large-scale pretrained models has led to tremendous progress in well-studied modalities such as vision and NLP. However, similar gains have not been observed in many other modalities due to a lack of relevant pretrained models. In this work, we propose ORCA, a general cross-modal fine-tuning framework that extends the applicability of a single large-scale pretrained model to diverse modalities. ORCA adapts to a target task via an align-then-refine workflow: given the target input, ORCA first learns an embedding network that aligns the embedded feature distribution with the pretraining modality. The pretrained model is then fine-tuned on the embedded data to exploit the knowledge shared across modalities. Through extensive experiments, we show that ORCA obtains state-of-the-art results on 3 benchmarks containing over 60 datasets from 12 modalities, outperforming a wide range of hand-designed, AutoML, general-purpose, and task-specific methods. We highlight the importance of data alignment via a series of ablation studies and demonstrate ORCA's utility in data-limited regimes.
Multi-step Planning for Automated Hyperparameter Optimization with OptFormer
Oct 10, 2022



As machine learning permeates more industries and models become more expensive and time consuming to train, the need for efficient automated hyperparameter optimization (HPO) has never been more pressing. Multi-step planning based approaches to hyperparameter optimization promise improved efficiency over myopic alternatives by more effectively balancing out exploration and exploitation. However, the potential of these approaches has not been fully realized due to their technical complexity and computational intensity. In this work, we leverage recent advances in Transformer-based, natural-language-interfaced hyperparameter optimization to circumvent these barriers. We build on top of the recently proposed OptFormer which casts both hyperparameter suggestion and target function approximation as autoregressive generation thus making planning via rollouts simple and efficient. We conduct extensive exploration of different strategies for performing multi-step planning on top of the OptFormer model to highlight its potential for use in constructing non-myopic HPO strategies.
AANG: Automating Auxiliary Learning
May 27, 2022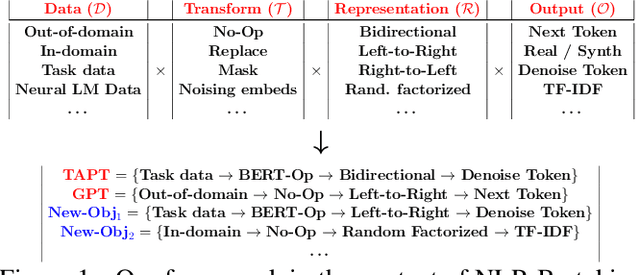

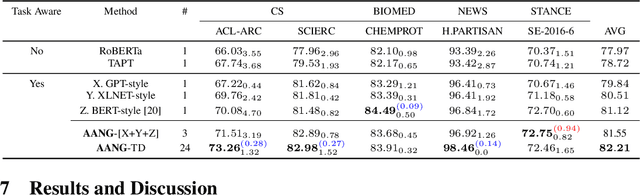
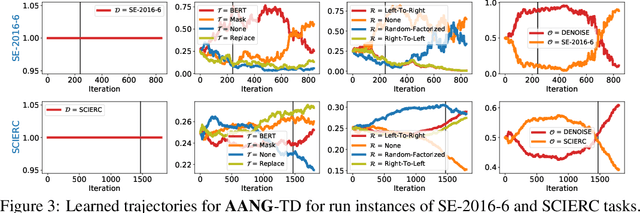
When faced with data-starved or highly complex end-tasks, it is commonplace for machine learning practitioners to introduce auxiliary objectives as supplementary learning signals. Whilst much work has been done to formulate useful auxiliary objectives, their construction is still an art which proceeds by slow and tedious hand-design. Intuitions about how and when these objectives improve end-task performance have also had limited theoretical backing. In this work, we present an approach for automatically generating a suite of auxiliary objectives. We achieve this by deconstructing existing objectives within a novel unified taxonomy, identifying connections between them, and generating new ones based on the uncovered structure. Next, we theoretically formalize widely-held intuitions about how auxiliary learning improves generalization of the end-task. This leads us to a principled and efficient algorithm for searching the space of generated objectives to find those most useful to a specified end-task. With natural language processing (NLP) as our domain of study, we empirically verify that our automated auxiliary learning pipeline leads to strong improvements over competitive baselines across continued training experiments on a pre-trained model on 5 NLP end-tasks.
Should We Be Pre-training? An Argument for End-task Aware Training as an Alternative
Sep 15, 2021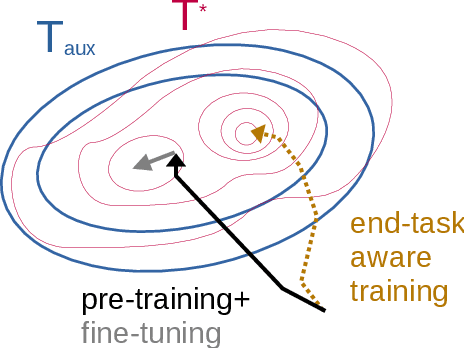

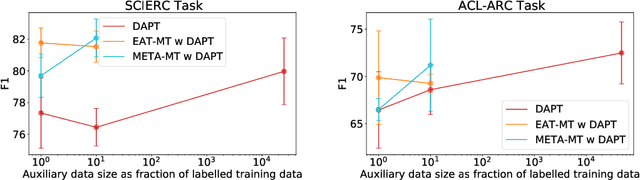

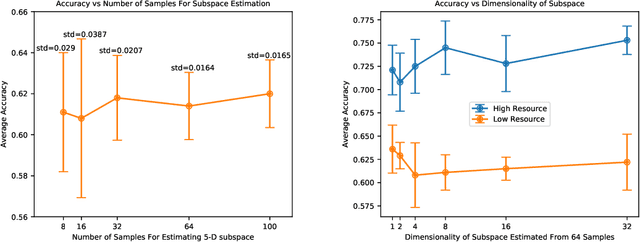
Pre-training, where models are trained on an auxiliary objective with abundant data before being fine-tuned on data from the downstream task, is now the dominant paradigm in NLP. In general, the pre-training step relies on little to no direct knowledge of the task on which the model will be fine-tuned, even when the end-task is known in advance. Our work challenges this status-quo of end-task agnostic pre-training. First, on three different low-resource NLP tasks from two domains, we demonstrate that multi-tasking the end-task and auxiliary objectives results in significantly better downstream task performance than the widely-used task-agnostic continued pre-training paradigm of Gururangan et al. (2020). We next introduce an online meta-learning algorithm that learns a set of multi-task weights to better balance among our multiple auxiliary objectives, achieving further improvements on end task performance and data efficiency.
Auxiliary Task Update Decomposition: The Good, The Bad and The Neutral
Aug 25, 2021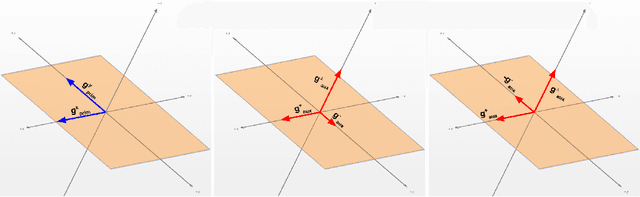

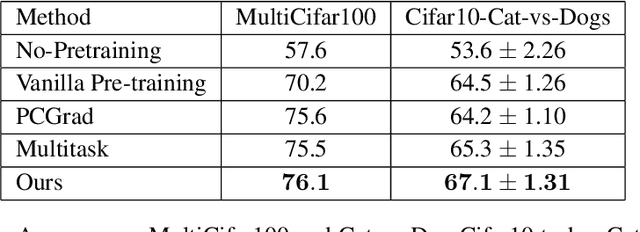
While deep learning has been very beneficial in data-rich settings, tasks with smaller training set often resort to pre-training or multitask learning to leverage data from other tasks. In this case, careful consideration is needed to select tasks and model parameterizations such that updates from the auxiliary tasks actually help the primary task. We seek to alleviate this burden by formulating a model-agnostic framework that performs fine-grained manipulation of the auxiliary task gradients. We propose to decompose auxiliary updates into directions which help, damage or leave the primary task loss unchanged. This allows weighting the update directions differently depending on their impact on the problem of interest. We present a novel and efficient algorithm for that purpose and show its advantage in practice. Our method leverages efficient automatic differentiation procedures and randomized singular value decomposition for scalability. We show that our framework is generic and encompasses some prior work as particular cases. Our approach consistently outperforms strong and widely used baselines when leveraging out-of-distribution data for Text and Image classification tasks.
Audio to Body Dynamics
Dec 19, 2017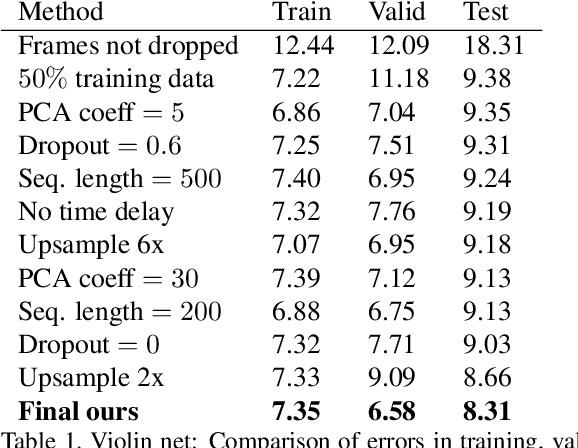
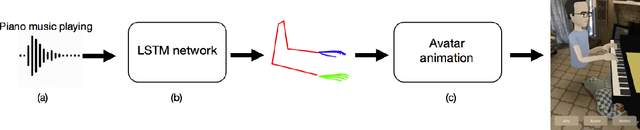


We present a method that gets as input an audio of violin or piano playing, and outputs a video of skeleton predictions which are further used to animate an avatar. The key idea is to create an animation of an avatar that moves their hands similarly to how a pianist or violinist would do, just from audio. Aiming for a fully detailed correct arms and fingers motion is a goal, however, it's not clear if body movement can be predicted from music at all. In this paper, we present the first result that shows that natural body dynamics can be predicted at all. We built an LSTM network that is trained on violin and piano recital videos uploaded to the Internet. The predicted points are applied onto a rigged avatar to create the animation.