 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal and Near-Optimal Adaptive Vector Quantization
Feb 05, 2024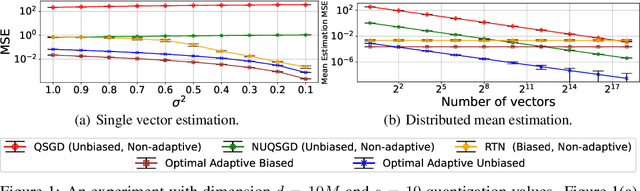
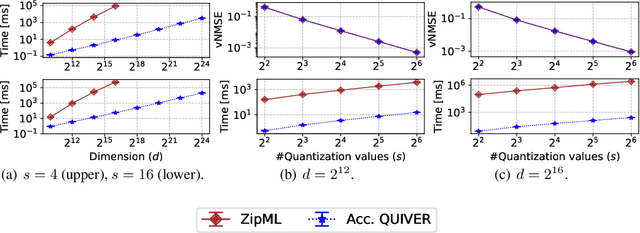
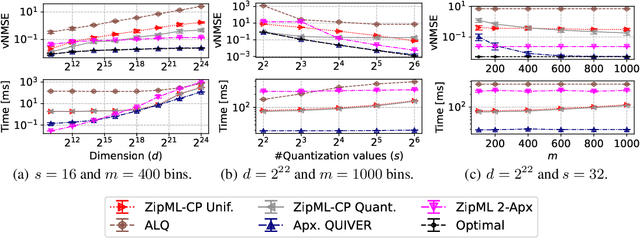
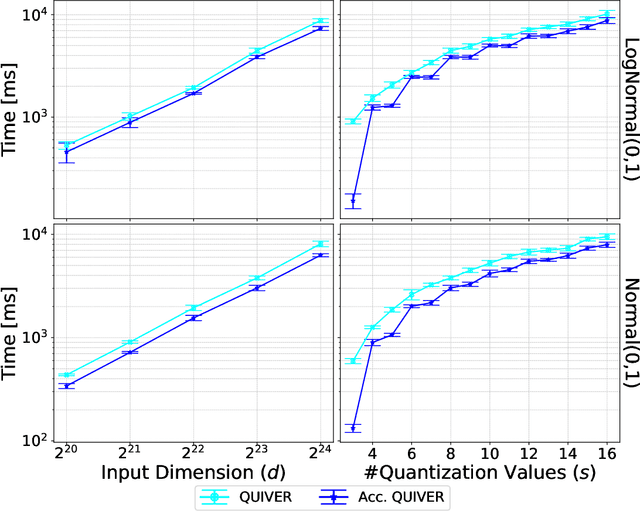
Quantization is a fundamental optimization for many machine-learning use cases, including compressing gradients, model weights and activations, and datasets. The most accurate form of quantization is \emph{adaptive}, where the error is minimized with respect to a given input, rather than optimizing for the worst case. However, optimal adaptive quantization methods are considered infeasible in terms of both their runtime and memory requirements. We revisit the Adaptive Vector Quantization (AVQ) problem and present algorithms that find optimal solutions with asymptotically improved time and space complexity. We also present an even faster near-optimal algorithm for large inputs. Our experiments show our algorithms may open the door to using AVQ more extensively in a variety of machine learning applications.
How to send a real number using a single bit
Oct 08, 2020
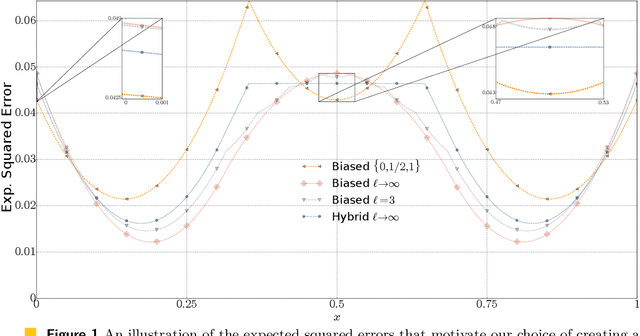
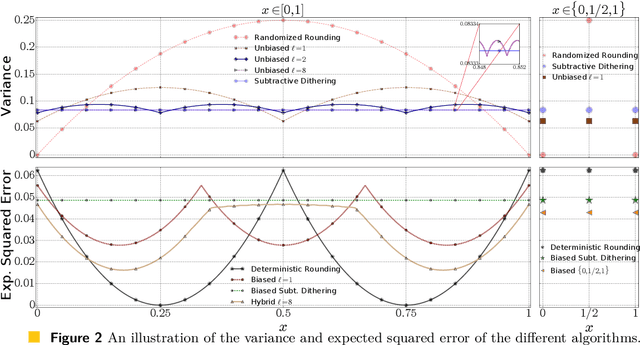
We consider the fundamental problem of communicating an estimate of a real number $x\in[0,1]$ using a single bit. A sender that knows $x$ chooses a value $X\in\set{0,1}$ to transmit. In turn, a receiver estimates $x$ based on the value of $X$. We consider both the biased and unbiased estimation problems and aim to minimize the cost. For the biased case, the cost is the worst-case (over the choice of $x$) expected squared error, which coincides with the variance if the algorithm is required to be unbiased. We first overview common biased and unbiased estimation approaches and prove their optimality when no shared randomness is allowed. We then show how a small amount of shared randomness, which can be as low as a single bit, reduces the cost in both cases. Specifically, we derive lower bounds on the cost attainable by any algorithm with unrestricted use of shared randomness and propose near-optimal solutions that use a small number of shared random bits. Finally, we discuss open problems and future directions.