 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Fusion Across Languages using Large Language Models
Mar 22, 2026Combining multiple knowledge graphs (KGs) across linguistic boundaries is a persistent challenge due to semantic heterogeneity and the complexity of graph environments. We propose a framework for cross-lingual graph fusion, leveraging the in-context reasoning and multilingual semantic priors of Large Language Models (LLMs). The framework implements structural linearization by mapping triplets directly into natural language sequences (e.g., [head] [relation] [tail]), enabling the LLM to map relations and reconcile entities between an evolving fused graph ($G_{c}^{(t-1)}$) and a new candidate graph ($G_{t}$). Evaluated on the DBP15K dataset, this exploratory study demonstrates that LLMs can serve as a universal semantic bridge to resolve cross-lingual discrepancies. Results show the successful sequential agglomeration of multiple heterogeneous graphs, offering a scalable, modular solution for continuous knowledge synthesis in multi-source, multilingual environments.
AMGPT: a Large Language Model for Contextual Querying in Additive Manufacturing
May 24, 2024Generalized large language models (LLMs) such as GPT-4 may not provide specific answers to queries formulated by materials science researchers. These models may produce a high-level outline but lack the capacity to return detailed instructions on manufacturing and material properties of novel alloys. Enhancing a smaller model with specialized domain knowledge may provide an advantage over large language models which cannot be retrained quickly enough to keep up with the rapid pace of research in metal additive manufacturing (AM). We introduce "AMGPT," a specialized LLM text generator designed for metal AM queries. The goal of AMGPT is to assist researchers and users in navigating the extensive corpus of literature in AM. Instead of training from scratch, we employ a pre-trained Llama2-7B model from Hugging Face in a Retrieval-Augmented Generation (RAG) setup, utilizing it to dynamically incorporate information from $\sim$50 AM papers and textbooks in PDF format. Mathpix is used to convert these PDF documents into TeX format, facilitating their integration into the RAG pipeline managed by LlamaIndex. Expert evaluations of this project highlight that specific embeddings from the RAG setup accelerate response times and maintain coherence in the generated text.
Gastro-Intestinal Tract Segmentation Using an Explainable 3D Unet
Sep 25, 2023In treating gastrointestinal cancer using radiotherapy, the role of the radiation oncologist is to administer high doses of radiation, through x-ray beams, toward the tumor while avoiding the stomach and intestines. With the advent of precise radiation treatment technology such as the MR-Linac, oncologists can visualize the daily positions of the tumors and intestines, which may vary day to day. Before delivering radiation, radio oncologists must manually outline the position of the gastrointestinal organs in order to determine position and direction of the x-ray beam. This is a time consuming and labor intensive process that may substantially prolong a patient's treatment. A deep learning (DL) method can automate and expedite the process. However, many deep neural networks approaches currently in use are black-boxes which lack interpretability which render them untrustworthy and impractical in a healthcare setting. To address this, an emergent field of AI known as Explainable AI (XAI) may be incorporated to improve the transparency and viability of a model. This paper proposes a deep learning pipeline that incorporates XAI to address the challenges of organ segmentation.
Realistic Differentially-Private Transmission Power Flow Data Release
Mar 25, 2021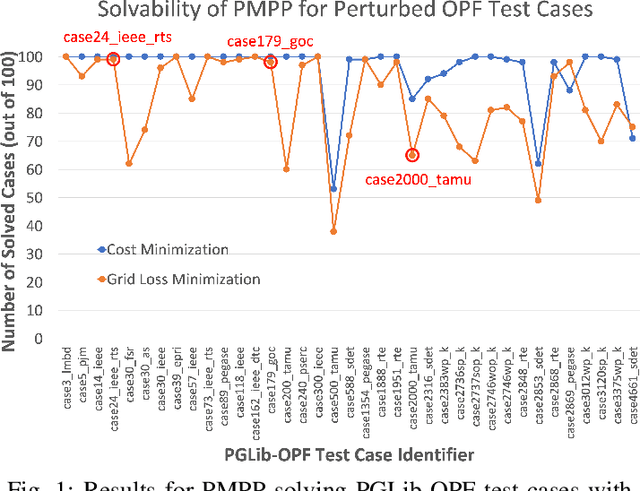
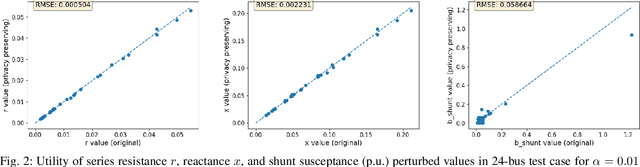
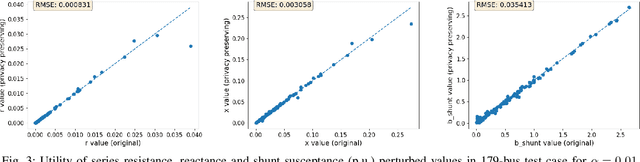
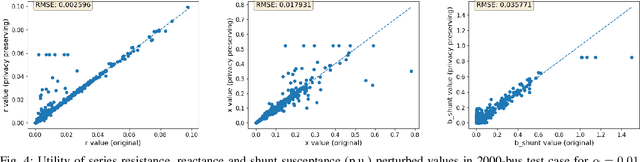
For the modeling, design and planning of future energy transmission networks, it is vital for stakeholders to access faithful and useful power flow data, while provably maintaining the privacy of business confidentiality of service providers. This critical challenge has recently been somewhat addressed in [1]. This paper significantly extends this existing work. First, we reduce the potential leakage information by proposing a fundamentally different post-processing method, using public information of grid losses rather than power dispatch, which achieve a higher level of privacy protection. Second, we protect more sensitive parameters, i.e., branch shunt susceptance in addition to series impedance (complete pi-model). This protects power flow data for the transmission high-voltage networks, using differentially private transformations that maintain the optimal power flow consistent with, and faithful to, expected model behaviour. Third, we tested our approach at a larger scale than previous work, using the PGLib-OPF test cases [10]. This resulted in the successful obfuscation of up to a 4700-bus system, which can be successfully solved with faithfulness of parameters and good utility to data analysts. Our approach addresses a more feasible and realistic scenario, and provides higher than state-of-the-art privacy guarantees, while maintaining solvability, fidelity and feasibility of the system.
Online Detection of Action Start in Untrimmed, Streaming Videos
Jul 23, 2018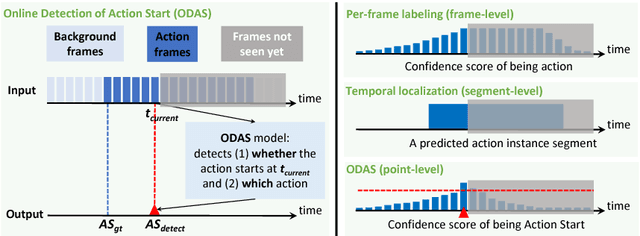
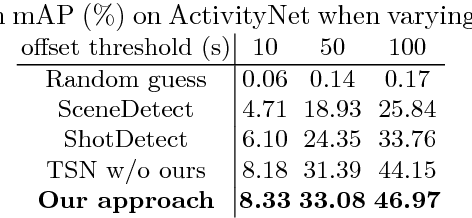
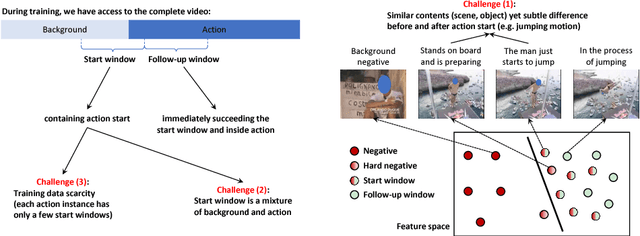
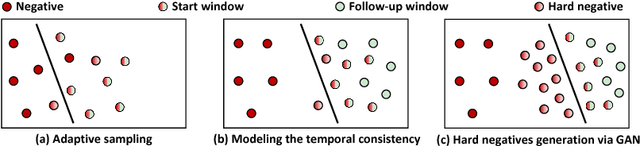
We aim to tackle a novel task in action detection - Online Detection of Action Start (ODAS) in untrimmed, streaming videos. The goal of ODAS is to detect the start of an action instance, with high categorization accuracy and low detection latency. ODAS is important in many applications such as early alert generation to allow timely security or emergency response. We propose three novel methods to specifically address the challenges in training ODAS models: (1) hard negative samples generation based on Generative Adversarial Network (GAN) to distinguish ambiguous background, (2) explicitly modeling the temporal consistency between data around action start and data succeeding action start, and (3) adaptive sampling strategy to handle the scarcity of training data. We conduct extensive experiments using THUMOS'14 and ActivityNet. We show that our proposed methods lead to significant performance gains and improve the state-of-the-art methods. An ablation study confirms the effectiveness of each proposed method.
CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos
Jun 13, 2017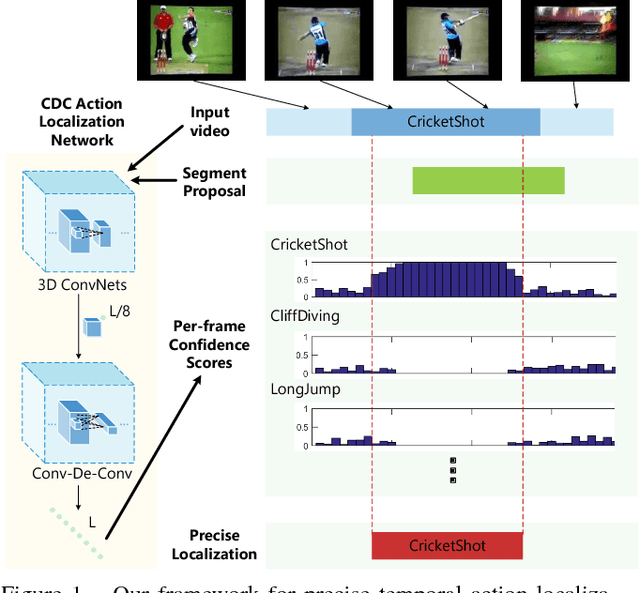
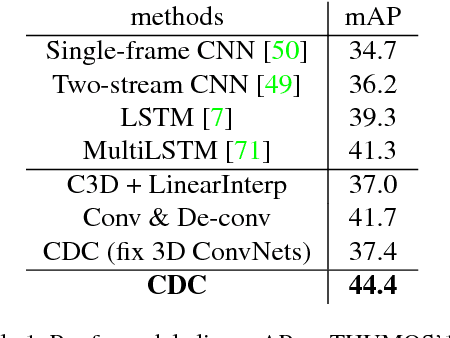

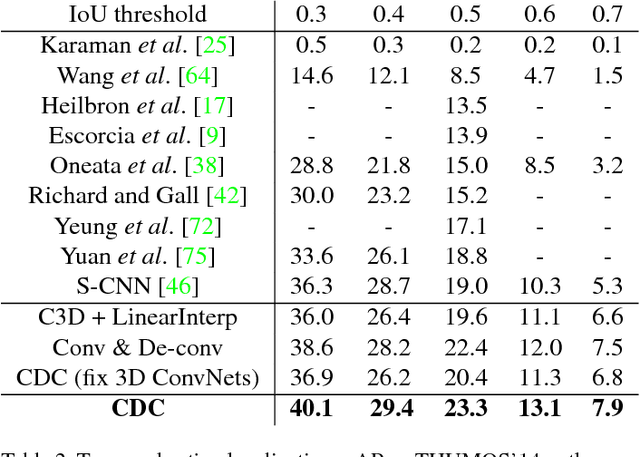
Temporal action localization is an important yet challenging problem. Given a long, untrimmed video consisting of multiple action instances and complex background contents, we need not only to recognize their action categories, but also to localize the start time and end time of each instance. Many state-of-the-art systems use segment-level classifiers to select and rank proposal segments of pre-determined boundaries. However, a desirable model should move beyond segment-level and make dense predictions at a fine granularity in time to determine precise temporal boundaries. To this end, we design a novel Convolutional-De-Convolutional (CDC) network that places CDC filters on top of 3D ConvNets, which have been shown to be effective for abstracting action semantics but reduce the temporal length of the input data. The proposed CDC filter performs the required temporal upsampling and spatial downsampling operations simultaneously to predict actions at the frame-level granularity. It is unique in jointly modeling action semantics in space-time and fine-grained temporal dynamics. We train the CDC network in an end-to-end manner efficiently. Our model not only achieves superior performance in detecting actions in every frame, but also significantly boosts the precision of localizing temporal boundaries. Finally, the CDC network demonstrates a very high efficiency with the ability to process 500 frames per second on a single GPU server. We will update the camera-ready version and publish the source codes online soon.