 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Detection of Action Start in Untrimmed, Streaming Videos
Jul 23, 2018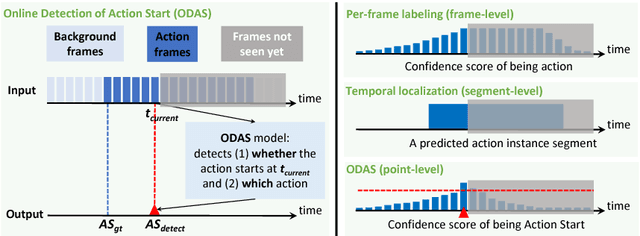
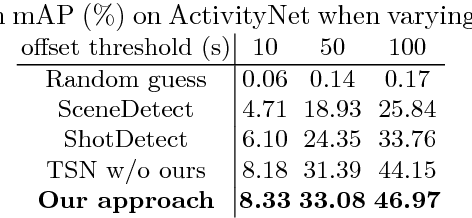
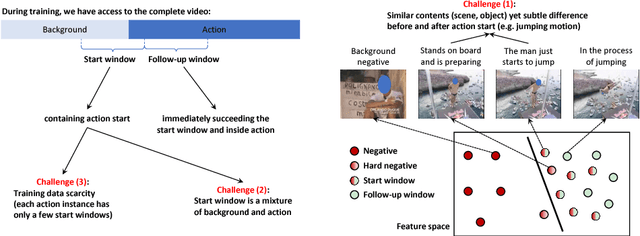
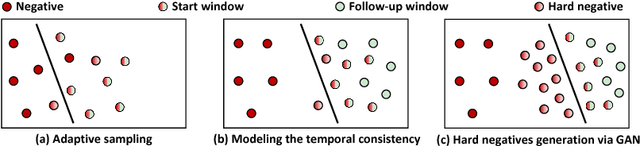
We aim to tackle a novel task in action detection - Online Detection of Action Start (ODAS) in untrimmed, streaming videos. The goal of ODAS is to detect the start of an action instance, with high categorization accuracy and low detection latency. ODAS is important in many applications such as early alert generation to allow timely security or emergency response. We propose three novel methods to specifically address the challenges in training ODAS models: (1) hard negative samples generation based on Generative Adversarial Network (GAN) to distinguish ambiguous background, (2) explicitly modeling the temporal consistency between data around action start and data succeeding action start, and (3) adaptive sampling strategy to handle the scarcity of training data. We conduct extensive experiments using THUMOS'14 and ActivityNet. We show that our proposed methods lead to significant performance gains and improve the state-of-the-art methods. An ablation study confirms the effectiveness of each proposed method.
AutoLoc: Weakly-supervised Temporal Action Localization
Jul 22, 2018

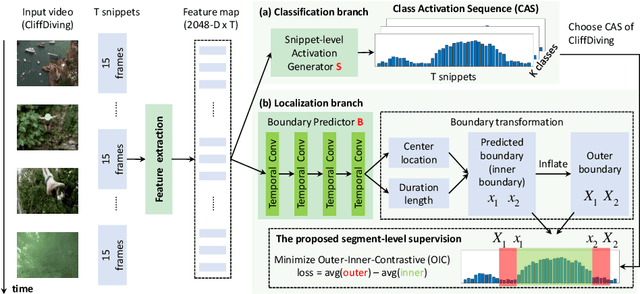

Temporal Action Localization (TAL) in untrimmed video is important for many applications. But it is very expensive to annotate the segment-level ground truth (action class and temporal boundary). This raises the interest of addressing TAL with weak supervision, namely only video-level annotations are available during training). However, the state-of-the-art weakly-supervised TAL methods only focus on generating good Class Activation Sequence (CAS) over time but conduct simple thresholding on CAS to localize actions. In this paper, we first develop a novel weakly-supervised TAL framework called AutoLoc to directly predict the temporal boundary of each action instance. We propose a novel Outer-Inner-Contrastive (OIC) loss to automatically discover the needed segment-level supervision for training such a boundary predictor. Our method achieves dramatically improved performance: under the IoU threshold 0.5, our method improves mAP on THUMOS'14 from 13.7% to 21.2% and mAP on ActivityNet from 7.4% to 27.3%. It is also very encouraging to see that our weakly-supervised method achieves comparable results with some fully-supervised methods.
CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos
Jun 13, 2017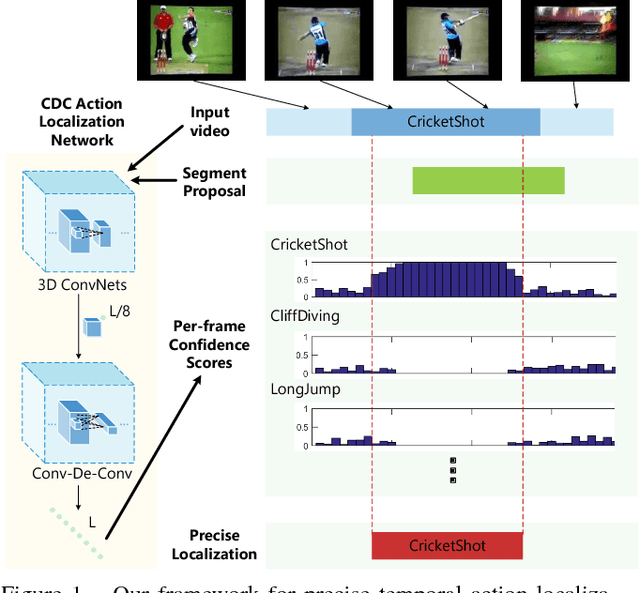
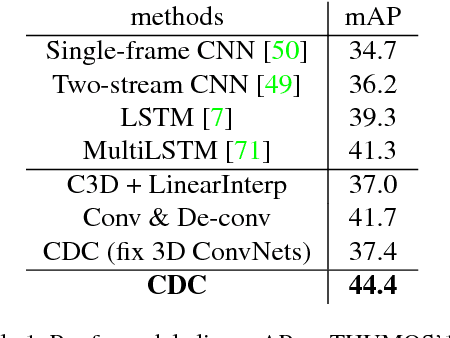

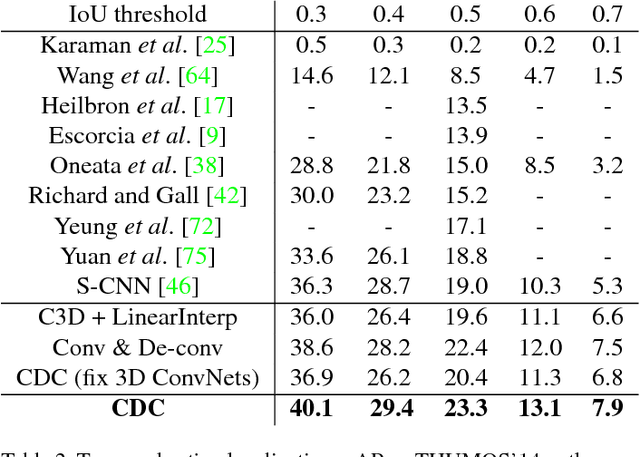
Temporal action localization is an important yet challenging problem. Given a long, untrimmed video consisting of multiple action instances and complex background contents, we need not only to recognize their action categories, but also to localize the start time and end time of each instance. Many state-of-the-art systems use segment-level classifiers to select and rank proposal segments of pre-determined boundaries. However, a desirable model should move beyond segment-level and make dense predictions at a fine granularity in time to determine precise temporal boundaries. To this end, we design a novel Convolutional-De-Convolutional (CDC) network that places CDC filters on top of 3D ConvNets, which have been shown to be effective for abstracting action semantics but reduce the temporal length of the input data. The proposed CDC filter performs the required temporal upsampling and spatial downsampling operations simultaneously to predict actions at the frame-level granularity. It is unique in jointly modeling action semantics in space-time and fine-grained temporal dynamics. We train the CDC network in an end-to-end manner efficiently. Our model not only achieves superior performance in detecting actions in every frame, but also significantly boosts the precision of localizing temporal boundaries. Finally, the CDC network demonstrates a very high efficiency with the ability to process 500 frames per second on a single GPU server. We will update the camera-ready version and publish the source codes online soon.