 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Marine Biofouling Assessment: Benchmarking Computer Vision and Multimodal LLMs on the Level of Fouling Scale
Jan 28, 2026Marine biofouling on vessel hulls poses major ecological, economic, and biosecurity risks. Traditional survey methods rely on diver inspections, which are hazardous and limited in scalability. This work investigates automated classification of biofouling severity on the Level of Fouling (LoF) scale using both custom computer vision models and large multimodal language models (LLMs). Convolutional neural networks, transformer-based segmentation, and zero-shot LLMs were evaluated on an expert-labelled dataset from the New Zealand Ministry for Primary Industries. Computer vision models showed high accuracy at extreme LoF categories but struggled with intermediate levels due to dataset imbalance and image framing. LLMs, guided by structured prompts and retrieval, achieved competitive performance without training and provided interpretable outputs. The results demonstrate complementary strengths across approaches and suggest that hybrid methods integrating segmentation coverage with LLM reasoning offer a promising pathway toward scalable and interpretable biofouling assessment.
Pallet Detection And Localisation From Synthetic Data
Mar 29, 2025The global warehousing industry is experiencing rapid growth, with the market size projected to grow at an annual rate of 8.1% from 2024 to 2030 [Grand View Research, 2021]. This expansion has led to a surge in demand for efficient pallet detection and localisation systems. While automation can significantly streamline warehouse operations, the development of such systems often requires extensive manual data annotation, with an average of 35 seconds per image, for a typical computer vision project. This paper presents a novel approach to enhance pallet detection and localisation using purely synthetic data and geometric features derived from their side faces. By implementing a domain randomisation engine in Unity, the need for time-consuming manual annotation is eliminated while achieving high-performance results. The proposed method demonstrates a pallet detection performance of 0.995 mAP50 for single pallets on a real-world dataset. Additionally, an average position accuracy of less than 4.2 cm and an average rotation accuracy of 8.2{\deg} were achieved for pallets within a 5-meter range, with the pallet positioned head-on.
Benchmarking Reinforcement Learning Methods for Dexterous Robotic Manipulation with a Three-Fingered Gripper
Aug 27, 2024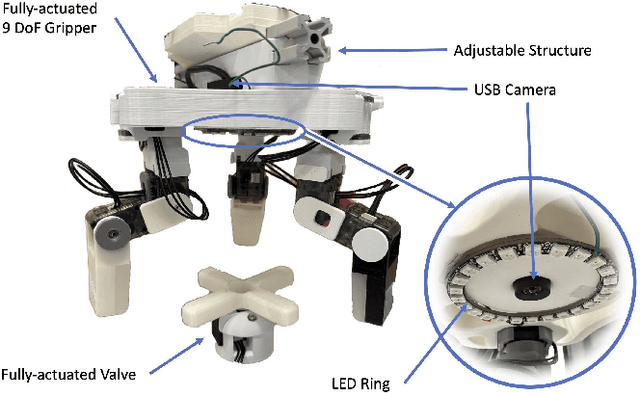
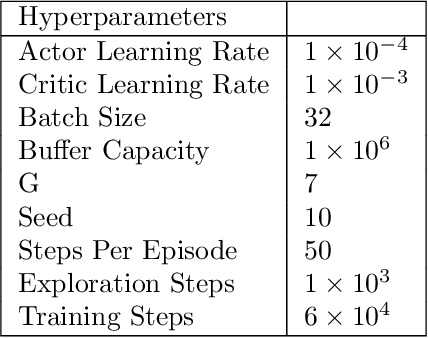
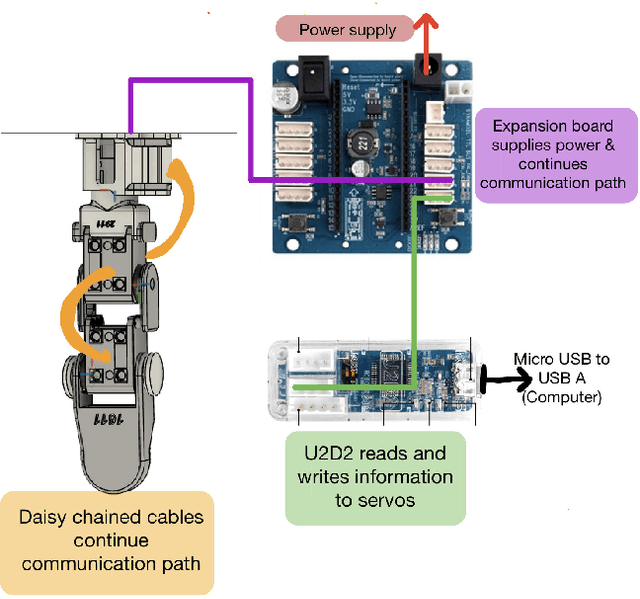
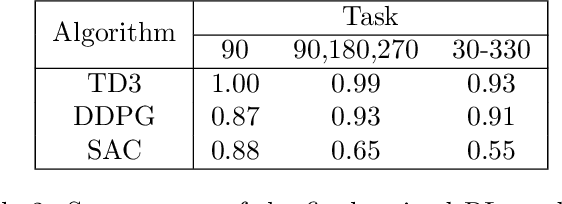
Reinforcement Learning (RL) training is predominantly conducted in cost-effective and controlled simulation environments. However, the transfer of these trained models to real-world tasks often presents unavoidable challenges. This research explores the direct training of RL algorithms in controlled yet realistic real-world settings for the execution of dexterous manipulation. The benchmarking results of three RL algorithms trained on intricate in-hand manipulation tasks within practical real-world contexts are presented. Our study not only demonstrates the practicality of RL training in authentic real-world scenarios, facilitating direct real-world applications, but also provides insights into the associated challenges and considerations. Additionally, our experiences with the employed experimental methods are shared, with the aim of empowering and engaging fellow researchers and practitioners in this dynamic field of robotics.
Image-Based Deep Reinforcement Learning with Intrinsically Motivated Stimuli: On the Execution of Complex Robotic Tasks
Jul 31, 2024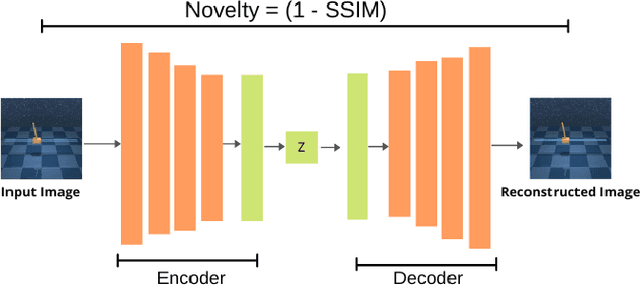
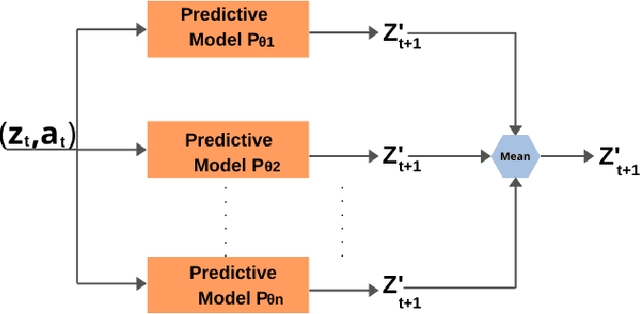
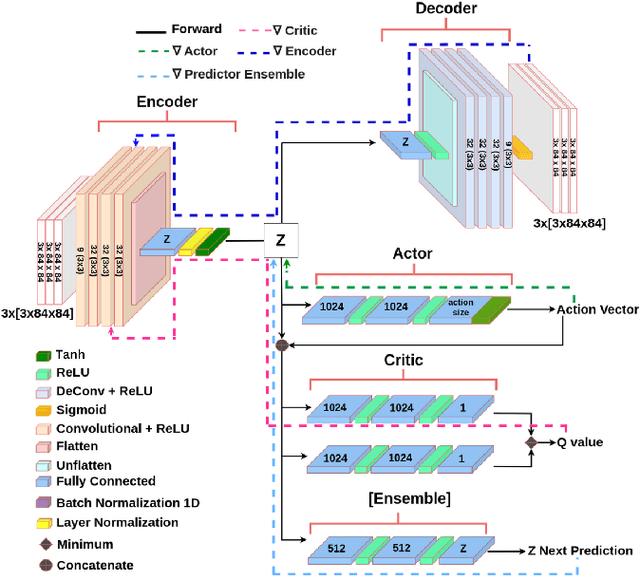
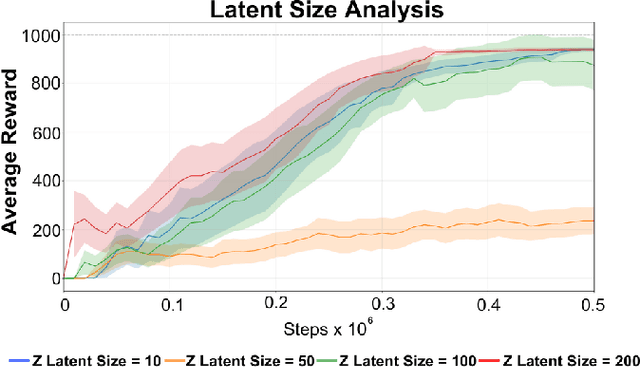
Reinforcement Learning (RL) has been widely used to solve tasks where the environment consistently provides a dense reward value. However, in real-world scenarios, rewards can often be poorly defined or sparse. Auxiliary signals are indispensable for discovering efficient exploration strategies and aiding the learning process. In this work, inspired by intrinsic motivation theory, we postulate that the intrinsic stimuli of novelty and surprise can assist in improving exploration in complex, sparsely rewarded environments. We introduce a novel sample-efficient method able to learn directly from pixels, an image-based extension of TD3 with an autoencoder called \textit{NaSA-TD3}. The experiments demonstrate that NaSA-TD3 is easy to train and an efficient method for tackling complex continuous-control robotic tasks, both in simulated environments and real-world settings. NaSA-TD3 outperforms existing state-of-the-art RL image-based methods in terms of final performance without requiring pre-trained models or human demonstrations.
CTD4 - A Deep Continuous Distributional Actor-Critic Agent with a Kalman Fusion of Multiple Critics
May 04, 2024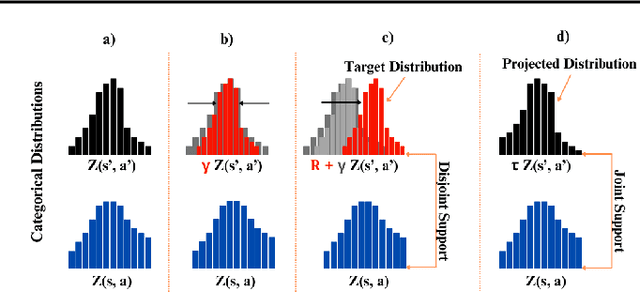
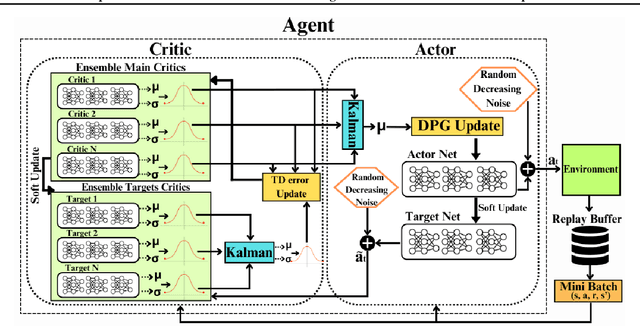
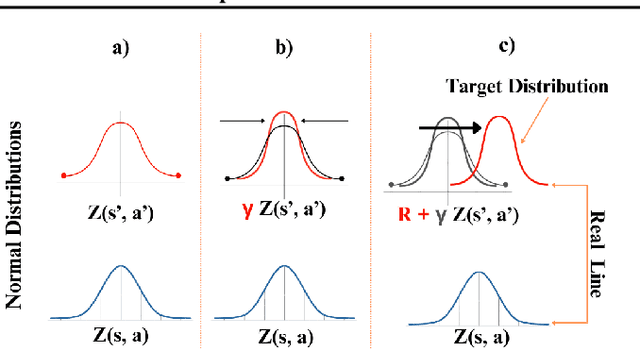
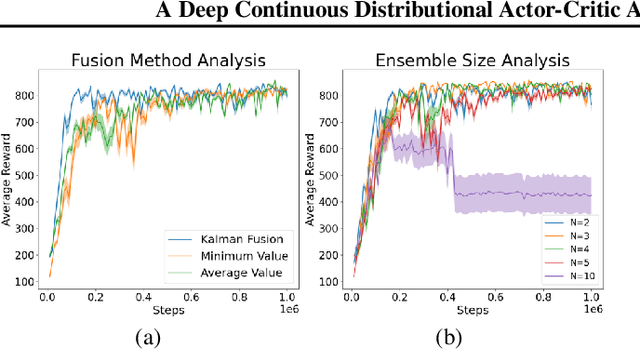
Categorical Distributional Reinforcement Learning (CDRL) has demonstrated superior sample efficiency in learning complex tasks compared to conventional Reinforcement Learning (RL) approaches. However, the practical application of CDRL is encumbered by challenging projection steps, detailed parameter tuning, and domain knowledge. This paper addresses these challenges by introducing a pioneering Continuous Distributional Model-Free RL algorithm tailored for continuous action spaces. The proposed algorithm simplifies the implementation of distributional RL, adopting an actor-critic architecture wherein the critic outputs a continuous probability distribution. Additionally, we propose an ensemble of multiple critics fused through a Kalman fusion mechanism to mitigate overestimation bias. Through a series of experiments, we validate that our proposed method is easy to train and serves as a sample-efficient solution for executing complex continuous-control tasks.
Improving Pallet Detection Using Synthetic Data
Feb 11, 2024
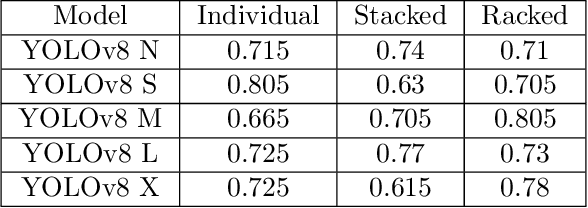


The use of synthetic data in machine learning saves a significant amount of time when implementing an effective object detector. However, there is limited research in this domain. This study aims to improve upon previously applied implementations in the task of instance segmentation of pallets in a warehouse environment. This study proposes using synthetically generated domain-randomised data as well as data generated through Unity to achieve this. This study achieved performance improvements on the stacked and racked pallet categories by 69% and 50% mAP50, respectively when being evaluated on real data. Additionally, it was found that there was a considerable impact on the performance of a model when it was evaluated against images in a darker environment, dropping as low as 3% mAP50 when being evaluated on images with an 80% brightness reduction. This study also created a two-stage detector that used YOLOv8 and SAM, but this proved to have unstable performance. The use of domain-randomised data proved to have negligible performance improvements when compared to the Unity-generated data.
Does ChatGPT and Whisper Make Humanoid Robots More Relatable?
Feb 11, 2024



Humanoid robots are designed to be relatable to humans for applications such as customer support and helpdesk services. However, many such systems, including Softbank's Pepper, fall short because they fail to communicate effectively with humans. The advent of Large Language Models (LLMs) shows the potential to solve the communication barrier for humanoid robotics. This paper outlines the comparison of different Automatic Speech Recognition (ASR) APIs, the integration of Whisper ASR and ChatGPT with the Pepper robot and the evaluation of the system (Pepper-GPT) tested by 15 human users. The comparison result shows that, compared to the Google ASR and Google Cloud ASR, the Whisper ASR performed best as its average Word Error Rate (1.716%) and processing time (2.639 s) are both the lowest. The participants' usability investigations show that 60% of the participants thought the performance of the Pepper-GPT was "excellent", while the rest rated this system as "good" in the subsequent experiments. It is proved that while some problems still need to be overcome, such as the robot's multilingual ability and facial tracking capacity, users generally responded positively to the system, feeling like talking to an actual human.
Racing Towards Reinforcement Learning based control of an Autonomous Formula SAE Car
Aug 24, 2023
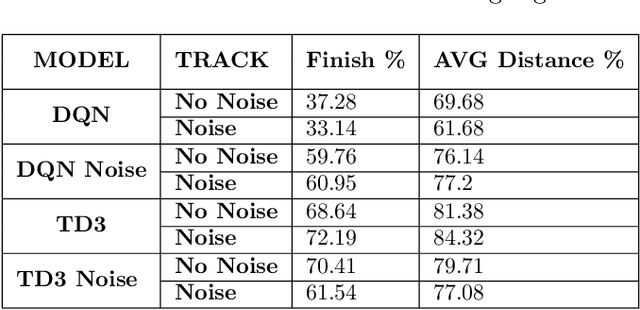


With the rising popularity of autonomous navigation research, Formula Student (FS) events are introducing a Driverless Vehicle (DV) category to their event list. This paper presents the initial investigation into utilising Deep Reinforcement Learning (RL) for end-to-end control of an autonomous FS race car for these competitions. We train two state-of-the-art RL algorithms in simulation on tracks analogous to the full-scale design on a Turtlebot2 platform. The results demonstrate that our approach can successfully learn to race in simulation and then transfer to a real-world racetrack on the physical platform. Finally, we provide insights into the limitations of the presented approach and guidance into the future directions for applying RL toward full-scale autonomous FS racing.
Seeing the Fruit for the Leaves: Robotically Mapping Apple Fruitlets in a Commercial Orchard
Aug 15, 2023

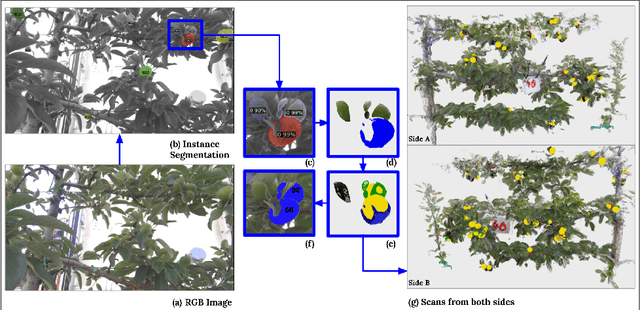

Aotearoa New Zealand has a strong and growing apple industry but struggles to access workers to complete skilled, seasonal tasks such as thinning. To ensure effective thinning and make informed decisions on a per-tree basis, it is crucial to accurately measure the crop load of individual apple trees. However, this task poses challenges due to the dense foliage that hides the fruitlets within the tree structure. In this paper, we introduce the vision system of an automated apple fruitlet thinning robot, developed to tackle the labor shortage issue. This paper presents the initial design, implementation,and evaluation specifics of the system. The platform straddles the 3.4 m tall 2D apple canopy structures to create an accurate map of the fruitlets on each tree. We show that this platform can measure the fruitlet load on an apple tree by scanning through both sides of the branch. The requirement of an overarching platform was justified since two-sided scans had a higher counting accuracy of 81.17 % than one-sided scans at 73.7 %. The system was also demonstrated to produce size estimates within 5.9% RMSE of their true size.
Visual based Tomato Size Measurement System for an Indoor Farming Environment
Apr 12, 2023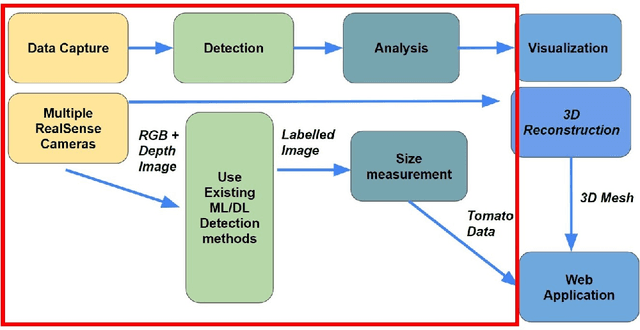
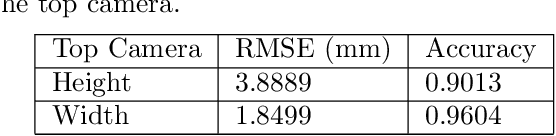

As technology progresses, smart automated systems will serve an increasingly important role in the agricultural industry. Current existing vision systems for yield estimation face difficulties in occlusion and scalability as they utilize a camera system that is large and expensive, which are unsuitable for orchard environments. To overcome these problems, this paper presents a size measurement method combining a machine learning model and depth images captured from three low cost RGBD cameras to detect and measure the height and width of tomatoes. The performance of the presented system is evaluated on a lab environment with real tomato fruits and fake leaves to simulate occlusion in the real farm environment. To improve accuracy by addressing fruit occlusion, our three-camera system was able to achieve a height measurement accuracy of 0.9114 and a width accuracy of 0.9443.