 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Marine Biofouling Assessment: Benchmarking Computer Vision and Multimodal LLMs on the Level of Fouling Scale
Jan 28, 2026Marine biofouling on vessel hulls poses major ecological, economic, and biosecurity risks. Traditional survey methods rely on diver inspections, which are hazardous and limited in scalability. This work investigates automated classification of biofouling severity on the Level of Fouling (LoF) scale using both custom computer vision models and large multimodal language models (LLMs). Convolutional neural networks, transformer-based segmentation, and zero-shot LLMs were evaluated on an expert-labelled dataset from the New Zealand Ministry for Primary Industries. Computer vision models showed high accuracy at extreme LoF categories but struggled with intermediate levels due to dataset imbalance and image framing. LLMs, guided by structured prompts and retrieval, achieved competitive performance without training and provided interpretable outputs. The results demonstrate complementary strengths across approaches and suggest that hybrid methods integrating segmentation coverage with LLM reasoning offer a promising pathway toward scalable and interpretable biofouling assessment.
Accelerating Real-World Overtaking in F1TENTH Racing Employing Reinforcement Learning Methods
Oct 30, 2025While autonomous racing performance in Time-Trial scenarios has seen significant progress and development, autonomous wheel-to-wheel racing and overtaking are still severely limited. These limitations are particularly apparent in real-life driving scenarios where state-of-the-art algorithms struggle to safely or reliably complete overtaking manoeuvres. This is important, as reliable navigation around other vehicles is vital for safe autonomous wheel-to-wheel racing. The F1Tenth Competition provides a useful opportunity for developing wheel-to-wheel racing algorithms on a standardised physical platform. The competition format makes it possible to evaluate overtaking and wheel-to-wheel racing algorithms against the state-of-the-art. This research presents a novel racing and overtaking agent capable of learning to reliably navigate a track and overtake opponents in both simulation and reality. The agent was deployed on an F1Tenth vehicle and competed against opponents running varying competitive algorithms in the real world. The results demonstrate that the agent's training against opponents enables deliberate overtaking behaviours with an overtaking rate of 87% compared 56% for an agent trained just to race.
OrchardDepth: Precise Metric Depth Estimation of Orchard Scene from Monocular Camera Images
Feb 20, 2025

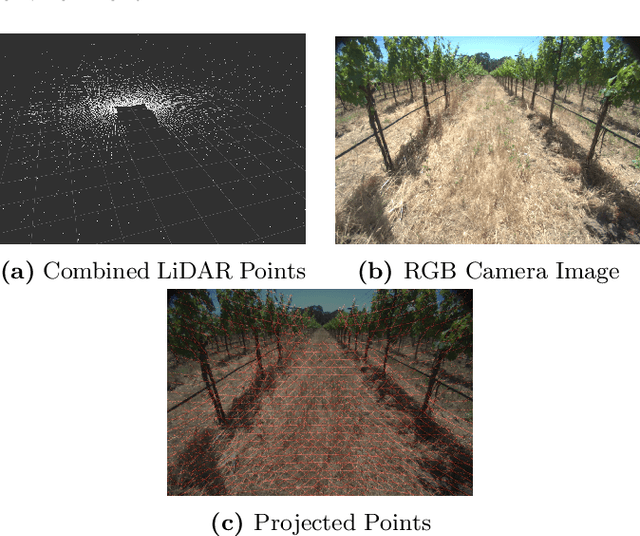
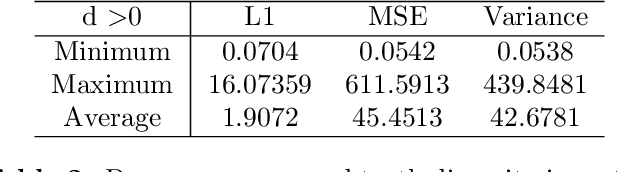
Monocular depth estimation is a rudimentary task in robotic perception. Recently, with the development of more accurate and robust neural network models and different types of datasets, monocular depth estimation has significantly improved performance and efficiency. However, most of the research in this area focuses on very concentrated domains. In particular, most of the benchmarks in outdoor scenarios belong to urban environments for the improvement of autonomous driving devices, and these benchmarks have a massive disparity with the orchard/vineyard environment, which is hardly helpful for research in the primary industry. Therefore, we propose OrchardDepth, which fills the gap in the estimation of the metric depth of the monocular camera in the orchard/vineyard environment. In addition, we present a new retraining method to improve the training result by monitoring the consistent regularization between dense depth maps and sparse points. Our method improves the RMSE of depth estimation in the orchard environment from 1.5337 to 0.6738, proving our method's validation.
Reward Prediction Error Prioritisation in Experience Replay: The RPE-PER Method
Jan 30, 2025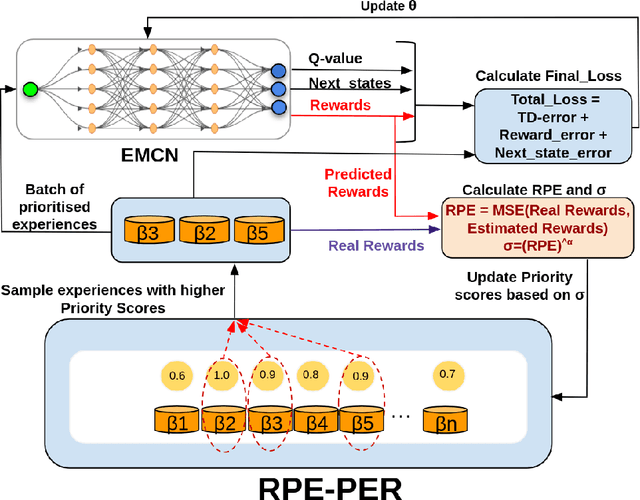
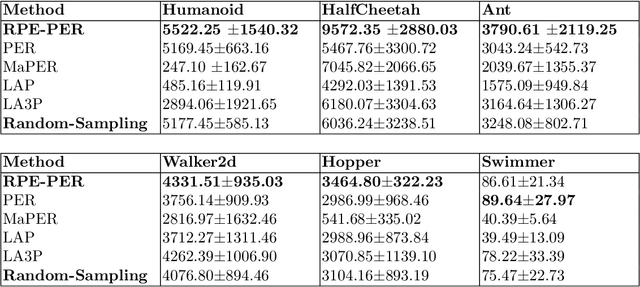


Reinforcement Learning algorithms aim to learn optimal control strategies through iterative interactions with an environment. A critical element in this process is the experience replay buffer, which stores past experiences, allowing the algorithm to learn from a diverse range of interactions rather than just the most recent ones. This buffer is especially essential in dynamic environments with limited experiences. However, efficiently selecting high-value experiences to accelerate training remains a challenge. Drawing inspiration from the role of reward prediction errors (RPEs) in biological systems, where they are essential for adaptive behaviour and learning, we introduce Reward Predictive Error Prioritised Experience Replay (RPE-PER). This novel approach prioritises experiences in the buffer based on RPEs. Our method employs a critic network, EMCN, that predicts rewards in addition to the Q-values produced by standard critic networks. The discrepancy between these predicted and actual rewards is computed as RPE and utilised as a signal for experience prioritisation. Experimental evaluations across various continuous control tasks demonstrate RPE-PER's effectiveness in enhancing the learning speed and performance of off-policy actor-critic algorithms compared to baseline approaches.
Bounded Exploration with World Model Uncertainty in Soft Actor-Critic Reinforcement Learning Algorithm
Dec 09, 2024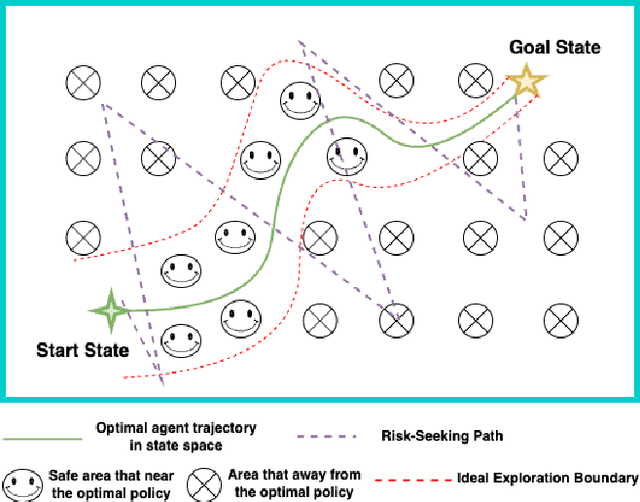
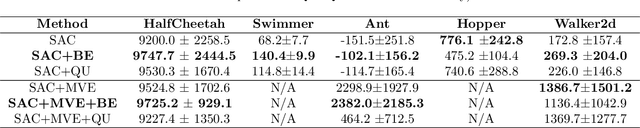
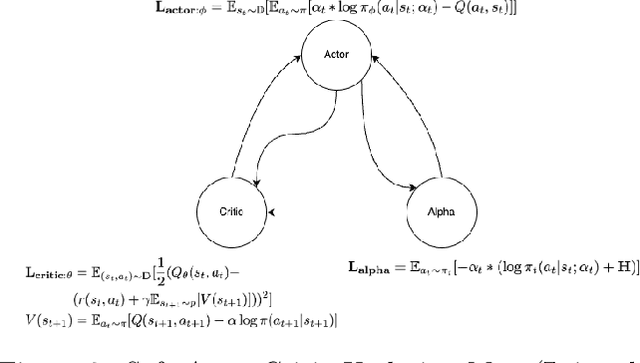
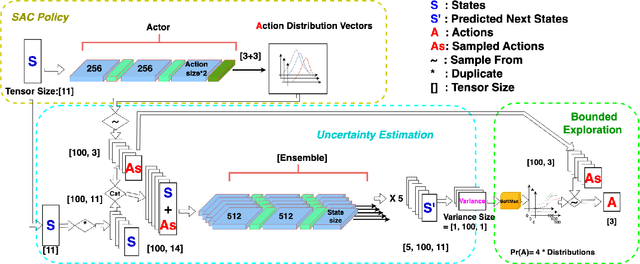
One of the bottlenecks preventing Deep Reinforcement Learning algorithms (DRL) from real-world applications is how to explore the environment and collect informative transitions efficiently. The present paper describes bounded exploration, a novel exploration method that integrates both 'soft' and intrinsic motivation exploration. Bounded exploration notably improved the Soft Actor-Critic algorithm's performance and its model-based extension's converging speed. It achieved the highest score in 6 out of 8 experiments. Bounded exploration presents an alternative method to introduce intrinsic motivations to exploration when the original reward function has strict meanings.
* 8 pages, 7 figures. Accepted as a poster presentation in the Australian Robotics and Automation Association (2023)
Benchmarking Reinforcement Learning Methods for Dexterous Robotic Manipulation with a Three-Fingered Gripper
Aug 27, 2024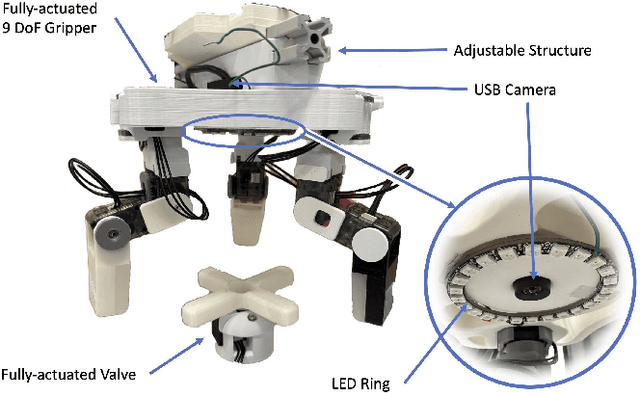
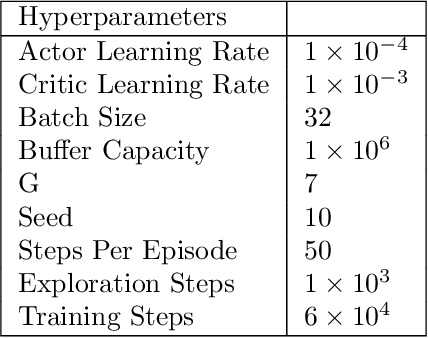
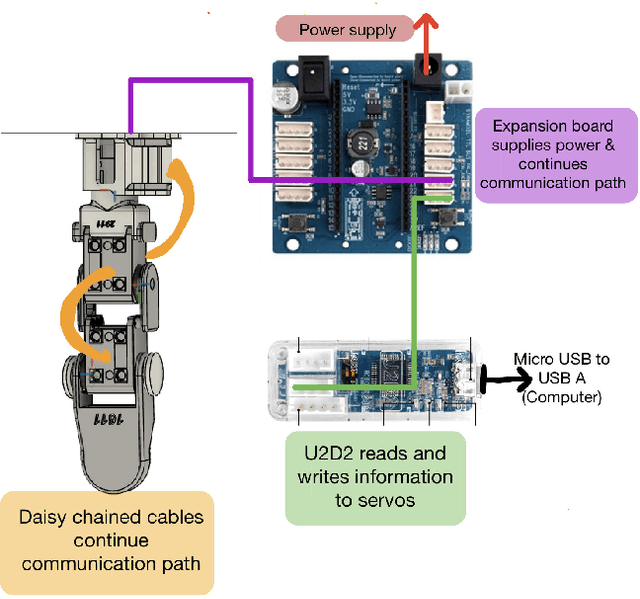
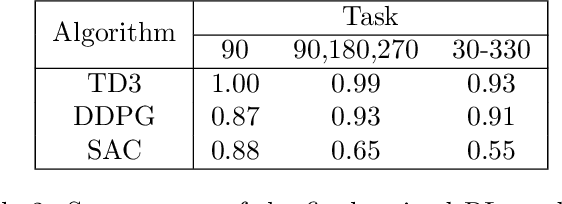
Reinforcement Learning (RL) training is predominantly conducted in cost-effective and controlled simulation environments. However, the transfer of these trained models to real-world tasks often presents unavoidable challenges. This research explores the direct training of RL algorithms in controlled yet realistic real-world settings for the execution of dexterous manipulation. The benchmarking results of three RL algorithms trained on intricate in-hand manipulation tasks within practical real-world contexts are presented. Our study not only demonstrates the practicality of RL training in authentic real-world scenarios, facilitating direct real-world applications, but also provides insights into the associated challenges and considerations. Additionally, our experiences with the employed experimental methods are shared, with the aim of empowering and engaging fellow researchers and practitioners in this dynamic field of robotics.
Image-Based Deep Reinforcement Learning with Intrinsically Motivated Stimuli: On the Execution of Complex Robotic Tasks
Jul 31, 2024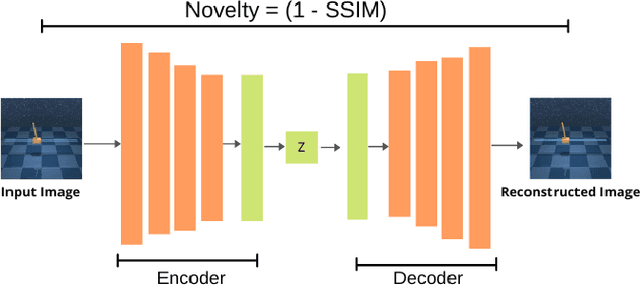
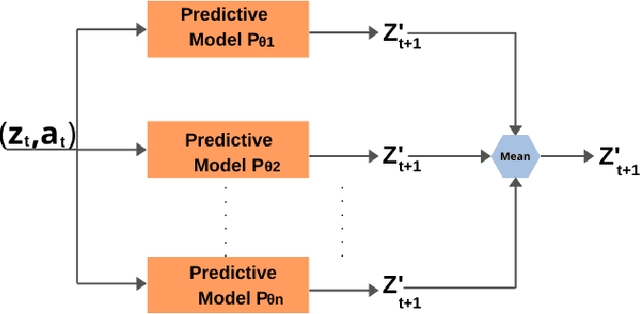
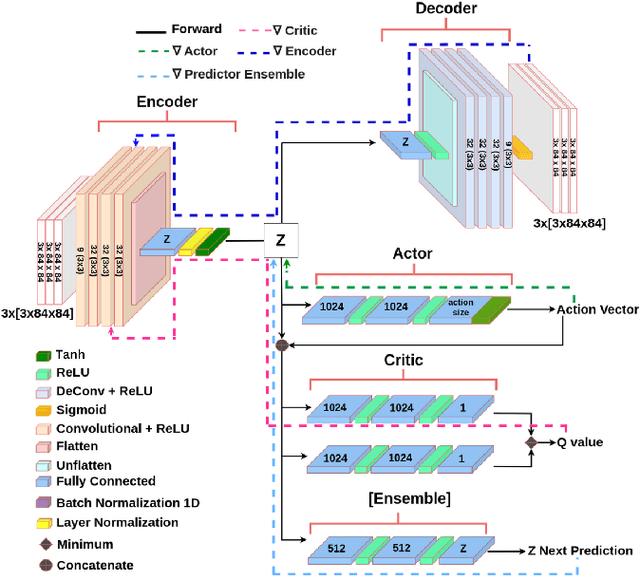
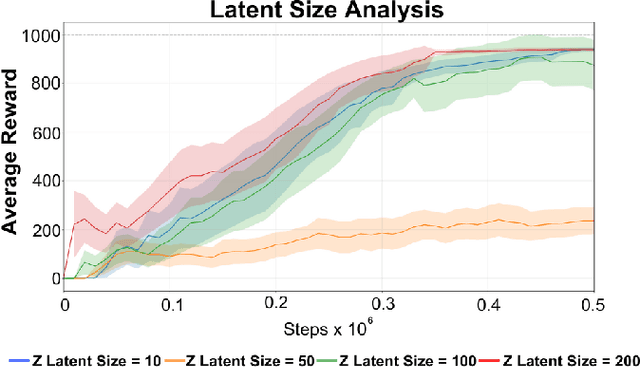
Reinforcement Learning (RL) has been widely used to solve tasks where the environment consistently provides a dense reward value. However, in real-world scenarios, rewards can often be poorly defined or sparse. Auxiliary signals are indispensable for discovering efficient exploration strategies and aiding the learning process. In this work, inspired by intrinsic motivation theory, we postulate that the intrinsic stimuli of novelty and surprise can assist in improving exploration in complex, sparsely rewarded environments. We introduce a novel sample-efficient method able to learn directly from pixels, an image-based extension of TD3 with an autoencoder called \textit{NaSA-TD3}. The experiments demonstrate that NaSA-TD3 is easy to train and an efficient method for tackling complex continuous-control robotic tasks, both in simulated environments and real-world settings. NaSA-TD3 outperforms existing state-of-the-art RL image-based methods in terms of final performance without requiring pre-trained models or human demonstrations.
CTD4 - A Deep Continuous Distributional Actor-Critic Agent with a Kalman Fusion of Multiple Critics
May 04, 2024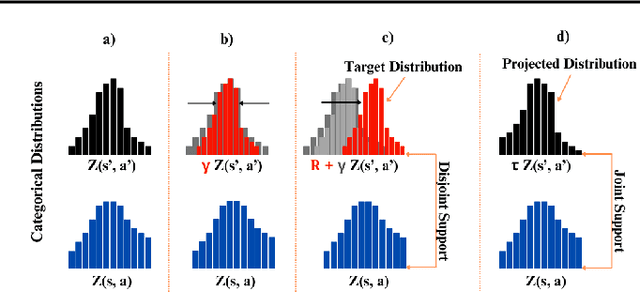
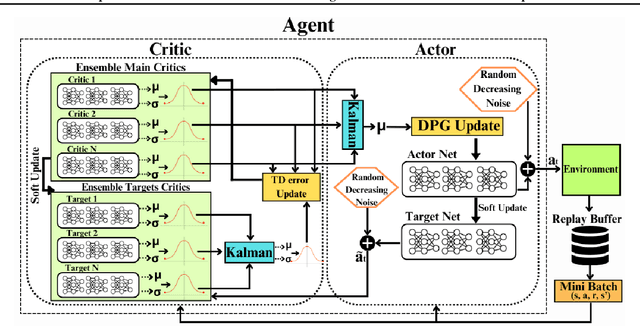
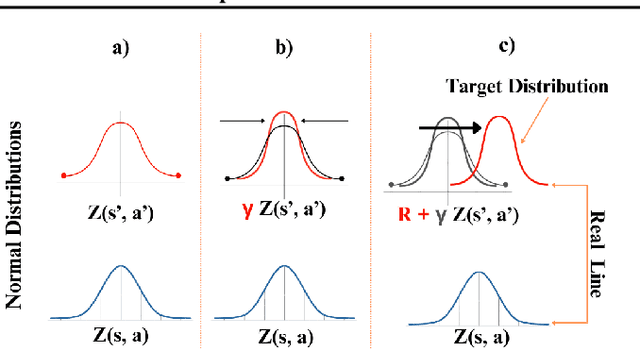
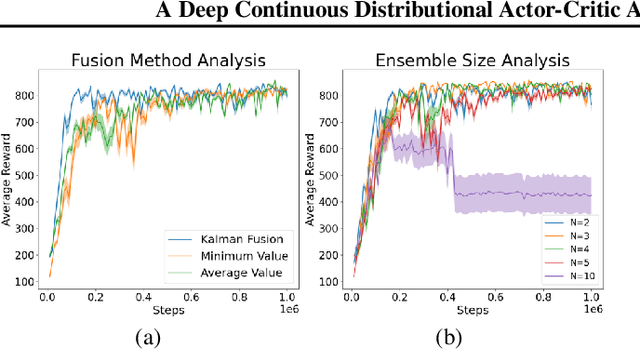
Categorical Distributional Reinforcement Learning (CDRL) has demonstrated superior sample efficiency in learning complex tasks compared to conventional Reinforcement Learning (RL) approaches. However, the practical application of CDRL is encumbered by challenging projection steps, detailed parameter tuning, and domain knowledge. This paper addresses these challenges by introducing a pioneering Continuous Distributional Model-Free RL algorithm tailored for continuous action spaces. The proposed algorithm simplifies the implementation of distributional RL, adopting an actor-critic architecture wherein the critic outputs a continuous probability distribution. Additionally, we propose an ensemble of multiple critics fused through a Kalman fusion mechanism to mitigate overestimation bias. Through a series of experiments, we validate that our proposed method is easy to train and serves as a sample-efficient solution for executing complex continuous-control tasks.
Deep Reinforcement Learning for Local Path Following of an Autonomous Formula SAE Vehicle
Jan 05, 2024
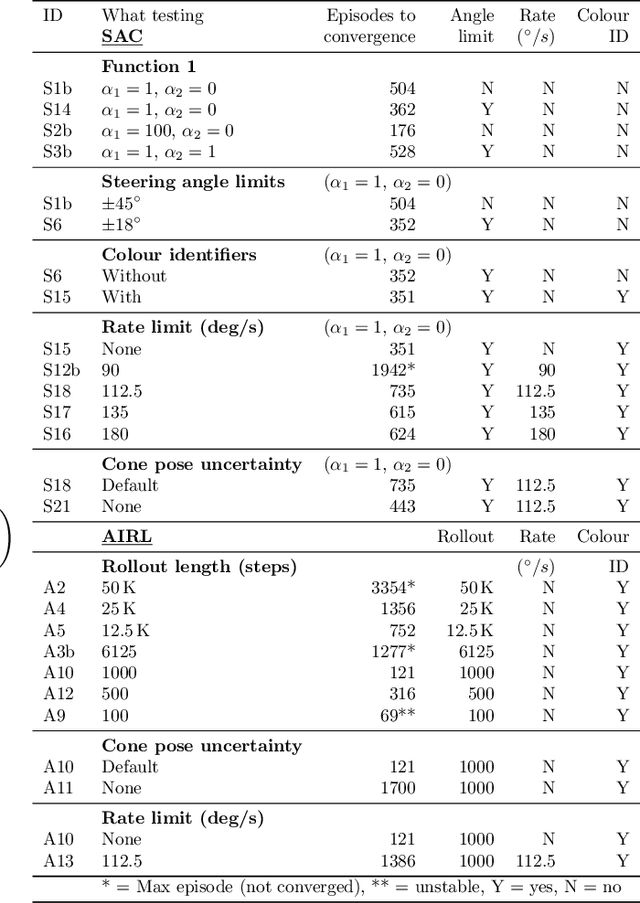

With the continued introduction of driverless events to Formula:Society of Automotive Engineers (F:SAE) competitions around the world, teams are investigating all aspects of the autonomous vehicle stack. This paper presents the use of Deep Reinforcement Learning (DRL) and Inverse Reinforcement Learning (IRL) to map locally-observed cone positions to a desired steering angle for race track following. Two state-of-the-art algorithms not previously tested in this context: soft actor critic (SAC) and adversarial inverse reinforcement learning (AIRL), are used to train models in a representative simulation. Three novel reward functions for use by RL algorithms in an autonomous racing context are also discussed. Tests performed in simulation and the real world suggest that both algorithms can successfully train models for local path following. Suggestions for future work are presented to allow these models to scale to a full F:SAE vehicle.
Racing Towards Reinforcement Learning based control of an Autonomous Formula SAE Car
Aug 24, 2023
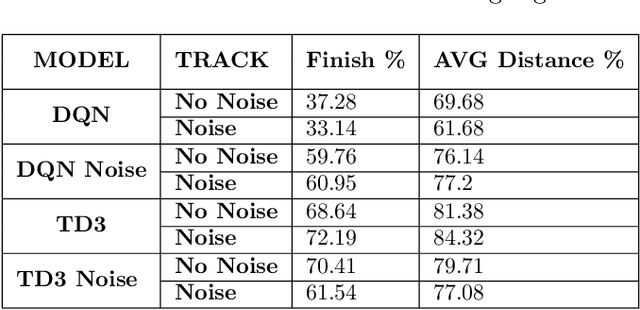


With the rising popularity of autonomous navigation research, Formula Student (FS) events are introducing a Driverless Vehicle (DV) category to their event list. This paper presents the initial investigation into utilising Deep Reinforcement Learning (RL) for end-to-end control of an autonomous FS race car for these competitions. We train two state-of-the-art RL algorithms in simulation on tracks analogous to the full-scale design on a Turtlebot2 platform. The results demonstrate that our approach can successfully learn to race in simulation and then transfer to a real-world racetrack on the physical platform. Finally, we provide insights into the limitations of the presented approach and guidance into the future directions for applying RL toward full-scale autonomous FS racing.