 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Based Deep Reinforcement Learning with Intrinsically Motivated Stimuli: On the Execution of Complex Robotic Tasks
Paper and Code
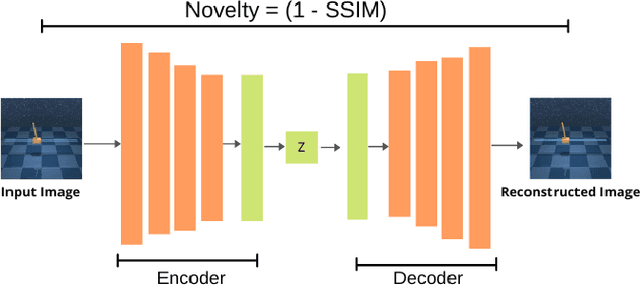
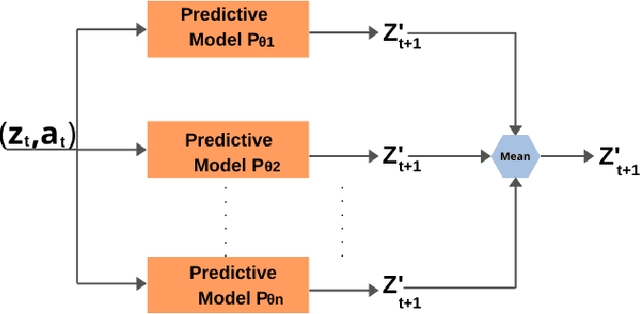
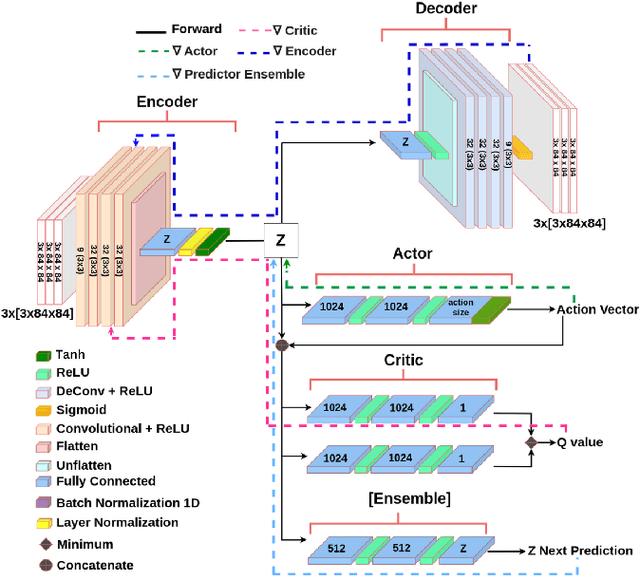
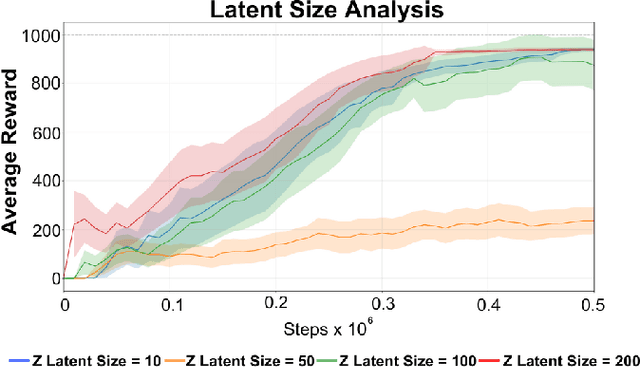
Reinforcement Learning (RL) has been widely used to solve tasks where the environment consistently provides a dense reward value. However, in real-world scenarios, rewards can often be poorly defined or sparse. Auxiliary signals are indispensable for discovering efficient exploration strategies and aiding the learning process. In this work, inspired by intrinsic motivation theory, we postulate that the intrinsic stimuli of novelty and surprise can assist in improving exploration in complex, sparsely rewarded environments. We introduce a novel sample-efficient method able to learn directly from pixels, an image-based extension of TD3 with an autoencoder called \textit{NaSA-TD3}. The experiments demonstrate that NaSA-TD3 is easy to train and an efficient method for tackling complex continuous-control robotic tasks, both in simulated environments and real-world settings. NaSA-TD3 outperforms existing state-of-the-art RL image-based methods in terms of final performance without requiring pre-trained models or human demonstrations.